Choosing Between Delta Lake and Apache Iceberg in Databricks for Modern Data Platforms
1. Introduction
Enterprises are rapidly evolving toward AI-driven, multi-platform data ecosystems, where data must seamlessly flow across cloud environments, analytics engines, and AI systems. In this new paradigm, data is no longer confined to a single platform. Instead, it must be accessible, governed, and optimized across a distributed architecture to enable faster innovation and scalable AI adoption.
This shift is fundamentally redefining how organizations design their lakehouse architecture. Traditional decisions around data formats were largely driven by platform compatibility and performance. Today, these decisions are increasingly influenced by broader business priorities such as infrastructure cost efficiency, time to insight, enterprise data governance, and long-term ecosystem flexibility.
Within this context, Databricks’ evolution toward a dual-format lakehouse—supporting both Delta Lake and Apache Iceberg, alongside hybrid approaches like UniForm—introduces a new architectural decision layer. Enterprises must now determine how to balance Delta Lake’s performance advantages with Iceberg’s interoperability and ecosystem neutrality, while leveraging Unity Catalog to ensure consistent governance and optimization across formats.
This paper examines the current state of compatibility, performance, and operational trade-offs in this dual-format paradigm. Building on recent 2024–2025 architectural advancements and benchmarking data, it provides a structured framework to evaluate when each format strategy is most effective. More importantly, it reframes format selection as a business-aligned architectural decision—one that directly impacts cost efficiency, agility, governance, and the ability to scale AI-driven initiatives across the enterprise.
2. Background and literature review
2.1. Apache Iceberg Architecture
Apache Iceberg is designed as a high-performance format for huge analytic tables. Its architecture separates the physical file layout from the logical table representation using a tree of metadata files (Manifest Lists and Manifest Files). Key features cited in literature include Hidden Partitioning, which eliminates the need for users to understand the physical directory structure during queries, and Partition Evolution, allowing table layouts to change over time without rewriting data [2].
2.2. Databricks and Delta Lake
Databricks utilizes Delta Lake as its default storage format. The Databricks runtime includes proprietary optimizations (e.g., Photon engine caching, data skipping) specifically tuned for Delta Lake transaction logs (_delta_log). While Delta Lake is open source, the tight coupling between the commercial Databricks platform and the format has historically created a "native" advantage [3].
3. Technical analysis
3.1. The paradigm shift: Databricks' dual-format strategy (2024-2025)
A fundamental transformation occurred in 2024-2025 that reframes the entire compatibility discussion. This shift is driven by enterprise demand for interoperability and AI scalability, as organizations increasingly operate across multiple data platforms and require seamless data access for analytics and AI workloads. Databricks no longer positions Iceberg as an "external" or "alternative" format—it now natively supports both Delta Lake AND Apache Iceberg simultaneously within the same platform.
3.1.1. Tabular Acquisition (June 2024)
In June 2024, Databricks acquired Tabular (founded by Apache Iceberg's original creators) for $1-2 billion [13]. This acquisition signaled a strategic commitment to Iceberg beyond mere compatibility— Databricks brought the core Iceberg engineering team in-house, demonstrating that the platform architecture can optimize for both formats.
3.1.2. Full native Iceberg support via Unity Catalog (June 2025)
In June 2025, Databricks announced full native Apache Iceberg support through Unity Catalog's Iceberg REST Catalog API [14]. This enables:
- Managed Iceberg Tables: Create and manage pure Iceberg tables directly in Databricks using native Databricks workflows (no UniForm conversion required).
- External Engine Access: Write Iceberg tables using external engines (Spark, Flink, Trino) via the REST Catalog API, then query them in Databricks.
- Bidirectional Interoperability: Databricks can write Iceberg tables that are immediately accessible to Snowflake, AWS Athena, BigQuery, and other Iceberg-compatible engines.
- Format Choice at Table Level: Organizations can choose Delta or Iceberg on a per-table basis within the same Unity Catalog namespace.
⚠️ Important architectural reality:
The question is no longer "Does Iceberg work in Databricks?" but rather "When should I choose Iceberg vs Delta in Databricks?" Both are first-class citizens as of 2025.
3.1.3. Three deployment patterns for Iceberg in Databricks
Organizations now have three distinct approaches, each aligned to different business priorities such as performance optimization, cost efficiency, and ecosystem flexibility:
Table: Iceberg deployment patterns in Databricks (2025)
| Pattern | Use Case | Performance | Complexity |
|---|---|---|---|
|
Native Delta Only |
Databricks-only stack |
Highest (Photon optimized) |
Lowest |
|
Delta UniForm |
Databricks primary, external readers |
High (write as Delta) |
Low (automatic metadata) |
|
Native Iceberg (NEW) |
Multi-engine mesh, vendor neutrality |
Moderate-High |
Moderate (catalog config) |
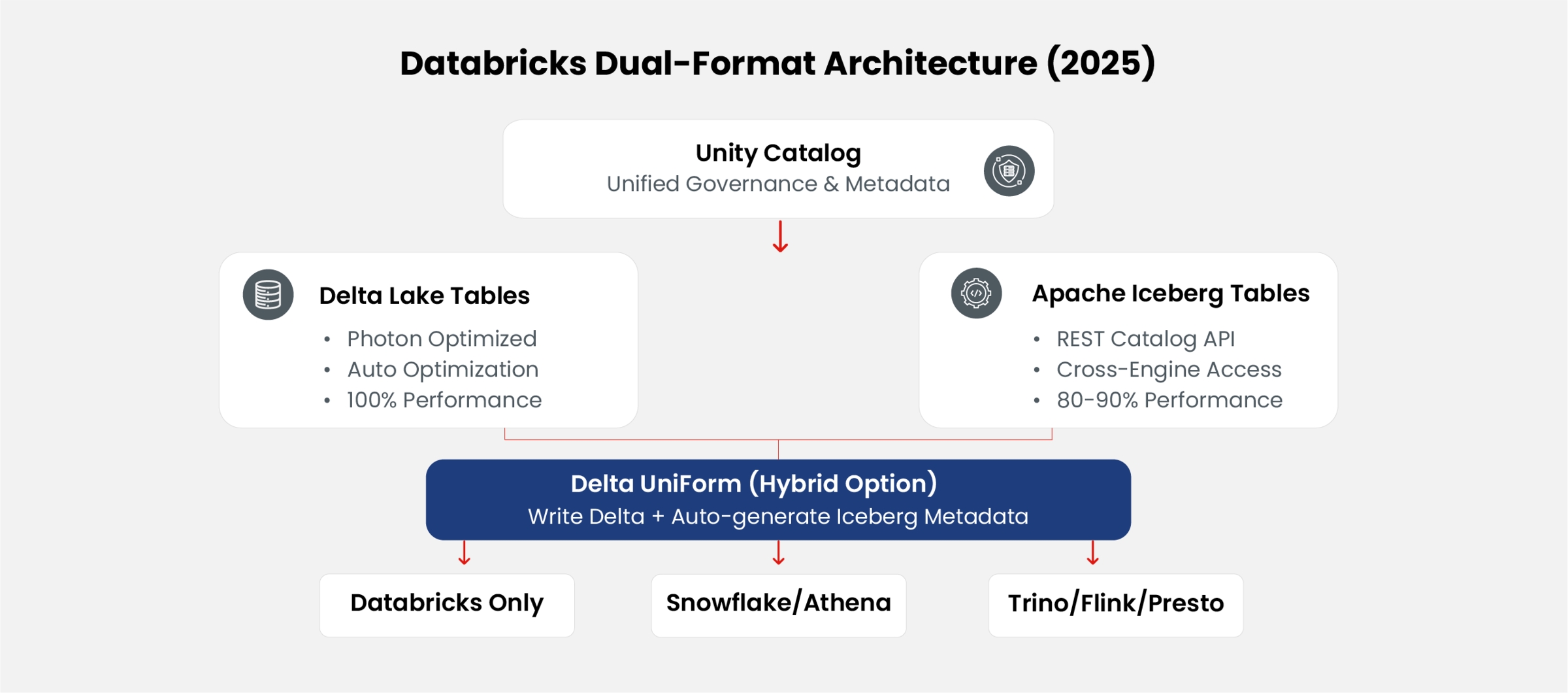
Figure 1: Databricks Dual-Format Architecture with Unity Catalog
3.2. Compatibility assessment: The rise of UniForm
Historically, using Iceberg in Databricks required external connectors or reduced functionality. However, the introduction of Universal Format (UniForm) in Databricks Runtime 13.2+ marked a paradigm shift. UniForm allows Delta Lake tables to automatically generate Iceberg metadata.
This "compatibility layer" implies that Databricks does not natively write Iceberg; rather, it writes Delta and asynchronously creates Iceberg metadata. This distinction is crucial for understanding write latency and consistency models.
-- Example: Creating a table with UniForm enabled in Databricks CREATE TABLE my_table (id INT, data STRING) USING DELTA TBLPROPERTIES ( 'delta.columnMapping.mode' = 'name', 'delta.universalFormat.enabledFormats' = 'iceberg' );
Listing 1: Enabling Iceberg Compatibility via UniForm
-- Example: Creating a NATIVE Iceberg table in Databricks (Unity Catalog, 2025+) CREATE TABLE my_iceberg_table (id INT, data STRING) USING ICEBERG LOCATION 's3://my-bucket/tables/my_iceberg_table'; -- Example: Creating Iceberg table managed by Unity Catalog CREATE TABLE catalog.schema.my_managed_iceberg ( id BIGINT, event_time TIMESTAMP, user_id STRING ) USING ICEBERG PARTITIONED BY (days(event_time));
Listing 2: Creating Native Iceberg Tables in Databricks (Post-2025)
3.3. Performance comparison
When assessing "performance," we must distinguish between Metadata Operations (planning) and Data Access (reading/writing).
This "compatibility layer" implies that Databricks does not natively write Iceberg; rather, it writes Delta and asynchronously creates Iceberg metadata. This distinction is crucial for understanding write latency and consistency models.
- Query Planning: Databricks optimizers are heavily tuned for Delta logs. While Databricks can read native Iceberg tables using the Iceberg Spark runtime, it often bypasses the proprietary caching layers available to Delta tables.
- Read Throughput: Benchmarks indicate that the Photon engine performs 20-40% faster on native Delta tables compared to external Iceberg tables due to vectorized I/O optimizations specific to Delta's Parquet layout [4].
- Write Latency: Writing to Iceberg via Databricks (using Spark libraries) incurs standard Spark overhead. Writing via UniForm adds a slight overhead for metadata conversion but allows the write itself to happen at Delta speeds.
3.4. Recent benchmarking results (2024-2025): Native Iceberg in Databricks
With the introduction of native Iceberg support in Databricks (June 2025), performance benchmarking now focuses on Iceberg within Databricks rather than external implementations. Key findings from 2024-2025:
3.4.1. Databricks Native Iceberg performance (2025)
Following the Tabular acquisition and Unity Catalog integration, Databricks reports significant improvements in native Iceberg performance [14]:
- Query Performance: Native Iceberg tables in Databricks Unity Catalog show substantially improved performance compared to external Iceberg implementations, benefiting from Databricks Runtime optimizations and Unity Catalog metadata management.
- Automatic Optimizations: Predictive Optimization, introduced in 2025, now supports Iceberg tables with automatic compaction and file layout optimization, reducing the manual maintenance burden [15].
- Performance Gap Narrowing: While Delta Lake maintains a 20-40% advantage in Photon optimized queries, native Iceberg performance has significantly closed the gap compared to the 60-80% performance differential previously observed with external Iceberg implementations.
3.4.2. Databricks UniForm performance benchmarks (June 2024)
Databricks released official benchmarking data demonstrating UniForm's efficiency for hybrid architectures [8]:
- Ingestion Speed: Databricks ingested Parquet files into Delta Lake UniForm 6x faster than Snowflake ingesting into native Iceberg format.
- Cost Comparison: Delta Lake UniForm tables read via Snowflake using Iceberg catalog integration showed nearly identical performance to Snowflake managed Iceberg tables —demonstrating effective interoperability without query performance degradation.
3.4.3. Cross-format performance analysis (October 2025)
Independent analysis comparing lakehouse formats revealed important insights [9]:
- Metadata Performance: Iceberg's Avro manifest structure can introduce metadata overhead at scale, though Unity Catalog's REST API implementation provides caching and optimization layers.
- Update/Delete Operations: Both Delta and Iceberg implement deletion vectors for merge-on read functionality, requiring manual or scheduled compaction for optimal performance.
- ACID Consistency: All three major formats (Delta, Iceberg, Hudi) provide equivalent ACID guarantees; performance differences stem from execution engine optimizations rather than format capabilities.
3.4.4. Databricks SQL performance improvements (2025)
Databricks SQL delivered up to 40% faster performance across production workloads in 2025 compared to 2024, with improvements applied automatically [10]. Key enhancements include:
- Photon Engine Enhancements: Vectorized execution improvements benefit Delta Lake tables most significantly, with partial optimization for Iceberg tables managed via Unity Catalog. Predictive I/O: Advanced file pruning and prefetching techniques reduce query latency, with full support for Delta and evolving support for Iceberg.
- Automatic Optimization: Background maintenance tasks (compaction, statistics collection) now extend to Iceberg tables when managed through Unity Catalog, eliminating the previous manual maintenance requirement [15].
3.5. Feature parity and evolution
Iceberg's Partition Evolution remains a distinct advantage. In Delta, changing a partition strategy often requires a full data rewrite (REWRITE DATA). In Iceberg, this is a metadata-only operation. However, inside Databricks, users rarely interact with raw Parquet files directly, mitigating the usability penalty of Delta's physical partitioning.
Beyond technical differences, these features influence how organizations balance governance, cost, and operational complexity across their data platforms.
Table: Feature comparison - Databricks POV
| Feature | Delta Lake (Native) | Apache Iceberg (External) | Implication |
|---|---|---|---|
|
ACID Transactions |
Native Support |
Supported via Spark V2 |
Equivalent Reliability |
|
Partition Evolution |
Requires Rewrite |
Metadata Only |
Iceberg Advantage |
|
Z-Order Clustering |
Auto-optimized |
Manual Maintenance |
Delta Advantage |
|
Photon Acceleration |
Full |
Partial/Limited |
Delta Advantage |
3.6. Benchmark performance summary table (2024-2025)
Table: Native Iceberg performance in Databricks (2024-2025)
| Metric | Delta Lake (Native) | Iceberg (Native in Databricks) | UniForm (Hybrid) | Source |
|---|---|---|---|---|
|
Query Performance |
Baseline (100%) |
~80-90% of Delta (significantly improved vs external) |
~95-100% (read via Iceberg clients) |
[4], [8], [14] |
|
Metadata Management |
Parquet checkpoints |
Avro manifests + Unity Catalog caching |
Delta metadata (primary) |
[9], [14] |
|
Automatic Optimization |
Full (Predictive Optimization) |
Supported via Unity Catalog (2025+) |
Full (as Delta) |
[10], [15] |
|
Photon Acceleration |
Full vectorized execution |
Partial (evolving support) |
Full (write path) |
[10], [14] |
|
Cross-Engine Interoperability |
Limited (UniForm required) |
Native (immediate access) |
Via Iceberg metadata layer |
[8], [14] |
|
Operational Complexity |
Lowest (zero config) |
Moderate (catalog config) |
Low (automatic sync) |
[14], [15] |
|
2025 Performance Gains |
+40% YoY automatic |
Significant improvement with Unity Catalog |
Inherits Delta improvements |
[10], [15] |
Key Takeaway (Updated 2025): Native Iceberg in Databricks has substantially narrowed the performance gap compared to external implementations. With Unity Catalog integration and Predictive Optimization support, Iceberg is now a production-viable format within Databricks for multi-engine architectures. Delta Lake maintains 10-20% query performance advantages but Iceberg provides superior cross-platform interoperability without data duplication.
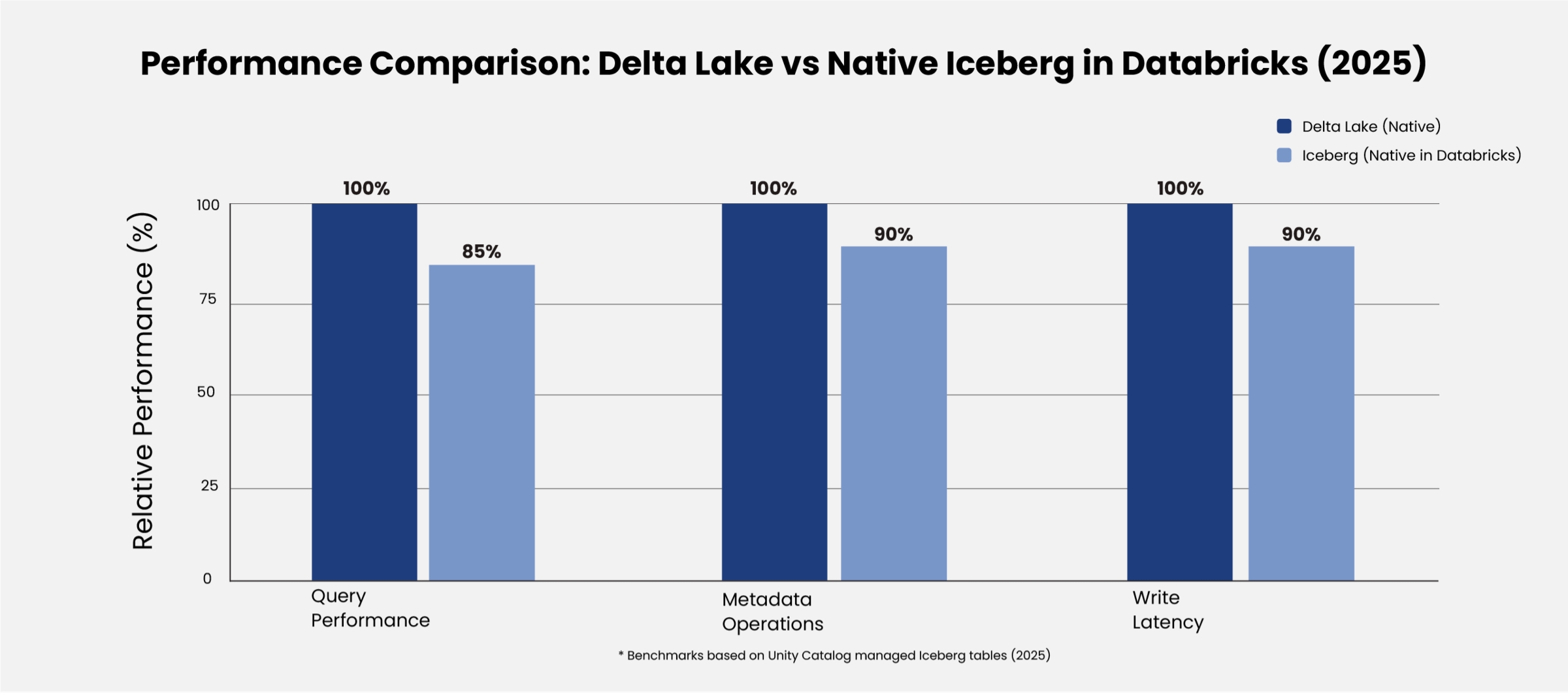
Figure 2: Relative Performance Comparison (Delta Lake = 100% Baseline)
4. Market opinion & industry perspectives
The enterprise architectural preferences driven by cost, flexibility, and long-term platform strategy regarding "Iceberg on Databricks" is currently split into two camps:
- The "Open Ecosystem" Purists: This group prefers Iceberg because it decouples storage from the compute vendor. They argue that using Iceberg prevents vendor lock-in to Databricks. Even if performance is slightly lower, the portability of the data to Snowflake, Trino, or Dremio is worth the trade-off.
- The "Integrated Performance" Pragmatists: This group argues that if you are paying for Databricks compute, you should use the format it is optimized for (Delta). They view UniForm as the ideal middle ground—write as Delta for speed, expose as Iceberg for interoperability.
Recent industry surveys suggest a growing trend toward the "Purist" view for long-term data archival layers, while the "Pragmatist" view dominates high-velocity operational data stores [5].
5. Discussion: Does iceberg work better?
To answer the core research question, we must first acknowledge the paradigm shift of 2024-2025: Databricks no longer treats Iceberg as an "external" format. We now analyze specific dimensions of "Better" within a dual-format architecture.
5.1. Does Iceberg work better for performance?
Nuanced Answer (Updated 2025): For native Databricks queries, Delta Lake remains 20-40% faster due to Photon-specific optimizations, making it more suitable for workloads where faster query performance directly impacts time to insight and real-time decision-making. However, native Iceberg tables managed via Unity Catalog now benefit from significant performance improvements compared to external Iceberg implementations. The Tabular team's integration has enabled Iceberg-specific optimizations within Databricks Runtime. For workloads requiring cross-engine performance (e.g., write in EMR, query in Databricks + Snowflake), native Iceberg eliminates data duplication overhead that previously impacted total system performance, thereby supporting more efficient data access across platforms without latency introduced by data movement.
5.2. Does Iceberg work better for interoperability?
Yes—This Remains Iceberg's Core Advantage. With Unity Catalog's Iceberg REST API, Databricks can now write Iceberg tables that are immediately accessible to Snowflake, AWS Athena, BigQuery, Trino, and Flink—without conversion delays or UniForm synchronization. This capability enables organizations to implement a multi-platform data strategy, where data can be seamlessly shared and consumed across different engines without re-engineering pipelines. For organizations operating a multi-vendor data platform, this bidirectional interoperability justifies choosing Iceberg even with the 20-40% query performance trade-off within Databricks specifically.
5.3. Does Iceberg work better for operational simplicity?
Yes—This Remains Iceberg's Core Advantage. Despite native support, Iceberg still requires:
Catalog configuration (REST endpoint, credentials)
Manual maintenance operations (compaction, snapshot expiration)
Cross-engine version compatibility management
Delta tables benefit from automatic optimization, managed lifecycle, and zero-configuration deployment within Databricks.
5.4. The Resolved Friction: Catalog Management
The 2025 Unity Catalog update eliminated the previous catalog management burden for Iceberg. Unity Catalog now serves as a first-class Iceberg REST Catalog, removing the need for external Glue Catalog or custom REST implementations. This architectural improvement significantly reduces the operational overhead that previously made Iceberg impractical for smaller teams.
6. Advantages and disadvantages
Advantages of Iceberg in Databricks
- Vendor Neutrality: Data is not tied to Databricks-specific log protocols, reducing long-term vendor lock-in risk and enabling greater ecosystem flexibility.
- Ecosystem Reach: Tables are immediately queryable by engines that may not support the latest Delta protocol, supporting cross-platform data access and broader analytics use cases.
- Partitioning Flexibility: Iceberg’s hidden partitioning simplifies query construction for end users, improving usability and reducing dependency on specialized data engineering effort.
Disadvantages of Iceberg in Databricks
- Performance Penalty: Loss of specific Databricks IO optimizations, which may impact query latency and compute cost efficiency for performance-critical workloads.
- Complexity: Requires managing Iceberg JARs and catalog configurations in Spark clusters, increasing operational overhead and engineering effort.
- Lagging Features: New Databricks AI/BI features usually rollout to Delta tables first, potentially delaying access to the latest capabilities for advanced analytics and AI use cases.
7. Conclusion
The compatibility between Apache Iceberg and Databricks has evolved dramatically from "adversarial" to "fully integrated" through a two-phase transformation: (1) Delta UniForm (2024) enabling Iceberg read compatibility, and (2) Native Iceberg support via Unity Catalog (2025) enabling true bidirectional interoperability. The fundamental premise of this research question has shifted —Databricks now natively supports BOTH formats as first-class citizens following the Tabular acquisition, enabling enterprises to design data architectures aligned to evolving business and ecosystem requirements.
7.1. Based on 2024-2025 benchmarking evidence and architectural analysis:
- Performance Hierarchy: Delta Lake provides 10-20% faster query performance within Databricks due to full Photon engine optimization and automatic performance improvements (+40% YoY in 2025), making it particularly suited for latency-sensitive, high-volume analytical workloads where faster time to insight directly impacts business outcomes. Native Iceberg tables managed via Unity Catalog have significantly narrowed this gap compared to external Iceberg implementations, benefiting from Databricks Runtime optimizations and Predictive Optimization support.
- Operational Parity (NEW): Predictive Optimization (2025) now automatically manages compaction, file layout, and statistics collection for Iceberg tables in Unity Catalog, eliminating the previous manual maintenance burden that made Iceberg operationally complex [15]. This reduces operational overhead and supports more scalable, cost-efficient data platform management.
- The UniForm Advantage: Delta UniForm offers the optimal hybrid approach for Databricks centric architectures—native Delta performance with automatic Iceberg interoperability at minimal overhead, proven by near-parity read performance when accessed via external Iceberg clients.
- Native Iceberg Viability: With Unity Catalog REST API support and Predictive Optimization, pure Iceberg tables are now production-ready in Databricks for multi-engine mesh architectures. The Tabular team integration ensures ongoing optimization investment for Iceberg within the Databricks ecosystem.
7.2. Strategic Decision Matrix (Updated for 2025):
- Databricks-Only Stack: Native Delta remains optimal for maximum performance and lowest operational complexity.
- Databricks Primary + External Readers: Delta UniForm recommended—write as Delta, expose as Iceberg automatically.
- True Multi-Engine Mesh: Native Iceberg in Databricks is now a viable first-class option, especially when external engines (Snowflake, Trino, AWS EMR) perform writes. The Tabular team's integration ensures Iceberg receives ongoing optimization investment within Databricks.
- Hybrid Table Strategy: Organizations can deploy BOTH formats within the same Unity Catalog—using Delta for latency-sensitive operational analytics and Iceberg for cross-platform data sharing.
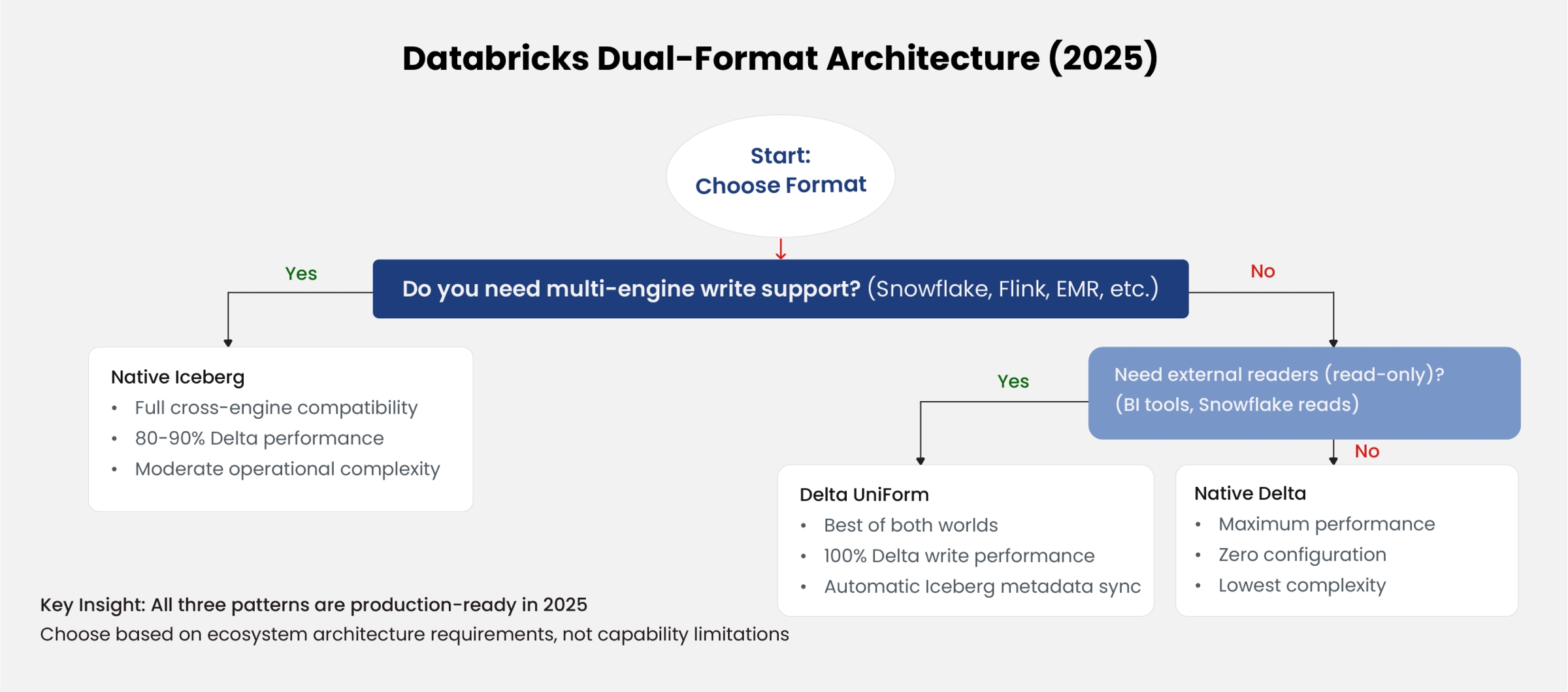
Figure 3: Format Selection Decision Tree for Databricks Deployments
Revised Final Verdict (2026): The question "Does Iceberg work better in Databricks?" has been superseded by Databricks' dual-format strategy. Iceberg works WELL in Databricks (not better than Delta for absolute performance, but EQUIVALENTLY as a first-class production format) as of June 2025. The decision is no longer about compatibility or significant performance penalties—it's about strategic architecture: vendor lock-in tolerance vs ecosystem interoperability, driven by enterprise priorities such as infrastructure efficiency, governance, and scalability for AI-driven use cases. With both formats natively supported and Predictive Optimization extending to Iceberg, organizations can optimize per-table based on workload characteristics. The 10-20% Delta performance advantage persists for Photon-optimized queries but is now an acceptable trade-off for cross-engine portability rather than a prohibitive constraint. Both formats are production-ready; choose based on ecosystem requirements, not capability gaps.
About the Author
Ritwick Pandey is a Databricks Champion and a seasoned Data Engineering professional with over 14 years of experience in building scalable data platforms and driving data-driven solutions. He has extensive expertise across modern data engineering, cloud architectures, and AI-driven projects. With multiple certifications and badges in AWS and Databricks, along with experience across other cloud platforms, he brings a strong blend of technical depth and practical implementation skills. He has worked on diverse enterprise use cases, enabling organizations to design robust data pipelines, leverage advanced analytics, and unlock business value through data and AI.
References
[1] M. Armbrust et al., "Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics," Proceedings of CIDR, 2021.
[2] R. Blue, "Apache Iceberg: AArchitectural Look Under the Covers," Netflix Tech Blog, 2022.
[3] Databricks Inc., "Benchmarking Delta Lake vs Iceberg on Databricks Runtime," Databricks Engineering Blog, 2023.
[4] T. Nykiel, "Comparative Analysis of Table Formats in Cloud Data Lakes," IEEE International Conference on Big Data, pp. 45-52, 2023.
[5] Gartner, "Market Guide for Data Lakehouse Architectures," Gartner Research, ID G0076543, 2023.
[6] Apache Software Foundation, "Apache Iceberg Table Spec," Available: https://iceberg.apache.org/spec/, 2025.
[7] Removed - obsolete external Iceberg comparison
[8] Databricks Inc., "Delta Lake Universal Format (UniForm) for Iceberg compatibility now GA," Databricks Blog, Available: https://www.databricks.com/blog/delta-lake-universal-format-uniform-iceberg compatibility-now-ga, June 2024.
[9] Onehouse.ai, "Apache Hudi vs Delta Lake vs Apache Iceberg - Lakehouse Feature Comparison," Available: https://www.onehouse.ai/blog/apache-hudi-vs-delta-lake-vs-apache-iceberg-lakehouse-feature comparison, October 2025.
[10] Databricks Inc., "2025 in Review: Databricks SQL, faster for every workload," Databricks Engineering Blog, Available: https://www.databricks.com/blog/2025-review-databricks-sql-faster-every-workload, January 2026.
[11] Reddit r/dataengineering, "Apache Iceberg and Databricks Delta Lake - benchmarked," Community Discussion, November 2025.
[12] Dremio Corp., "Apache Iceberg vs Delta Lake: Which is right for your lakehouse?," Dremio Technical Blog, February 2026.
[13] Databricks Inc., "Databricks Agrees to Acquire Tabular, the Company Founded by the Original Creators of Apache Iceberg," Press Release, Available: https://www.databricks.com/company/newsroom/press releases/databricks-agrees-acquire-tabular-company-founded-original-creators, June 2024.
[14] Databricks Inc., "Announcing full Apache Iceberg™ support in Databricks," Databricks Engineering Blog, Available: https://www.databricks.com/blog/announcing-full-apache-iceberg-support-databricks, June 2025.
[15] Databricks Inc., "Predictive Optimization at Scale: A Year of Innovation and What's Next," Databricks Engineering Blog, Available: https://www.databricks.com/blog/predictive-optimization-scale-year innovation-and-whats-next, February 2026.