Apache ‘Spark’ing innovation in Data Processing optimization
Introduction
Apache Spark holds a prominent position in big data processing and is widely used by developers. However, despite its widespread adoption, many may not be familiar with its origins and mechanics.
Apache Spark came into existence when a team of skilled UC Berkeley researchers undertook the initiative to overcome the limitations of MapReduce.
In traditional MapReduce implementations, the disk I/O operation from Map to Reduce stage involves storing results on the distributed file system. The cumulative impact of reading and writing to disk at each stage, especially with large datasets, can result in prolonged execution times, occasionally reaching hours or even days.
To address this, Spark was designed with in-memory processing. By minimizing the need for repeated disk I/O operations, Spark became 10-20 times faster than MapReduce.
Over time, Spark has consistently expanded and adapted to meet the dynamic demands of data processing. In our exploration of Apache Spark’s inner workings, we’ll unravel each stage of its architectural evolution, showcasing how it solidified its position as a preferred tool among data engineers worldwide.
Apache Spark Framework
In 2010, Apache Spark addressed prolonged execution with in-memory processing which allowed it to cache intermediate results in memory between stages. The Apache Spark framework follows a master-slave architecture, featuring a master node and multiple worker nodes within the cluster.
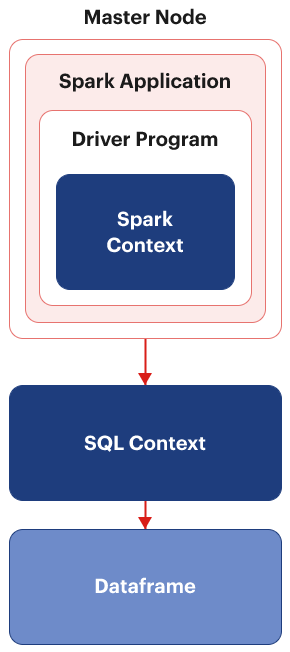
Upon submitting a Spark application– essentially the code written – to the master node, it triggers the initiation of the driver program. Each Spark application incorporates a driver program that initializes a Spark Context, which serves as the gateway for any Spark functionality.
SparkContext’s main work includes:
- Establishing a connection to spark cluster
- Calculating required resources to run the application
- Creating Resilient Distributed Datasets (RDDs)
- Monitoring the execution of application
- Shutting down the application
Later in the Spark journey, SQL Context was introduced. It’s purpose was to create Dataframes that in turn process structured and semi-structured data.
Apache 2.0
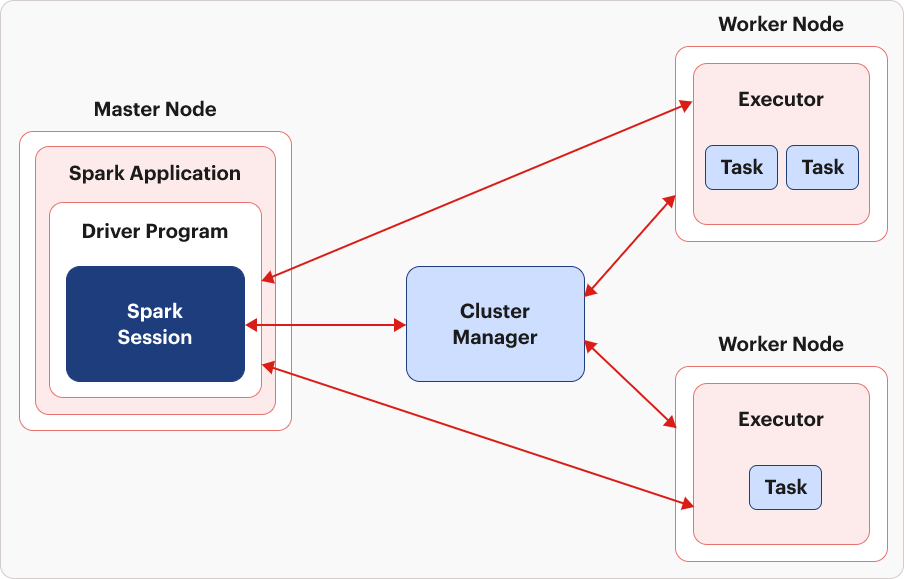
Following the advent of Spark 2.0, Spark Session took on the role of the new entry point for Spark functionalities. In this transition, SQL Context was deprecated, leaving Spark Context with limited functions, primarily centered around creating RDDs.
Spark Session establishes a connection with the Spark cluster, while the Cluster Manager efficiently allocates necessary resources to Worker nodes. The Cluster Manager adapts, serving as a standalone entity for single-node clusters and transforming into YARN or Mesos for multi-node clusters.
Once resources are allocated, Executors come into play and processes are initiated on worker nodes with the responsibility of executing tasks. A task, which is the computation unit performed on a single data partition, runs on a single core of the worker node. In the event of a task failure, a retry is triggered following the configured fault-tolerance action. Executors continuously monitor tasks, reporting back to the driver program in case of any issues.
The tasks executed in the executors are initially part of a series forming a Directed Acyclic Graph (DAG). This has been explained using the example below.
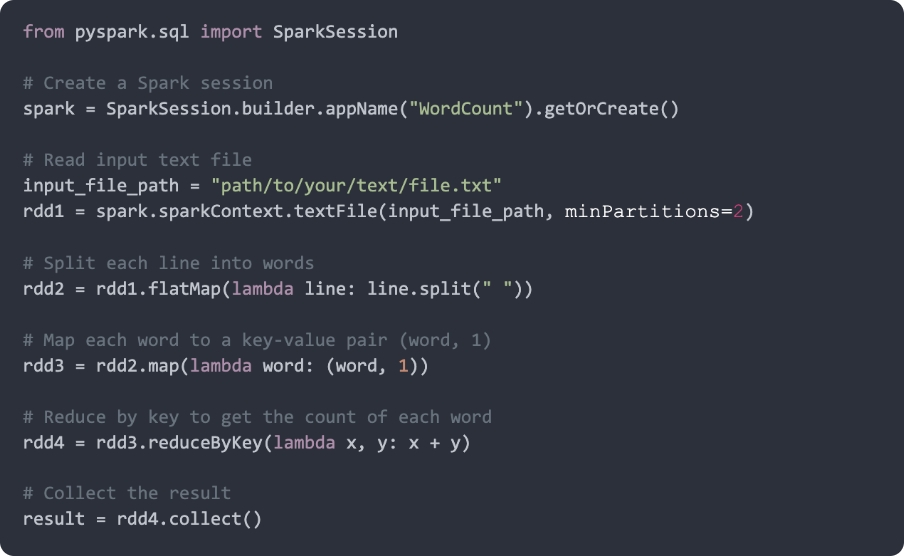
When a Spark action is invoked, it gives rise to a Job. Spark adheres to lazy evaluation, implying that processing only occurs when an action is triggered. Transformations, until then, are stored in the form of a DAG. The entire transformation from Job to tasks is done by DAG Scheduler. These tasks are then sent to Task Scheduler which further sends them to Cluster Manager.
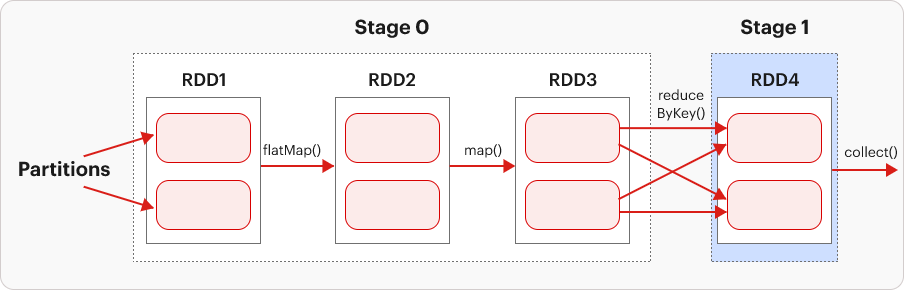
Whenever data shuffling occurs across the network, Spark segments the job into multiple Stages. Thus, a stage is created during data shuffling. In our code, the use of the reduceByKey() function induces data shuffling to group similar keys, resulting in the job being split into two stages.
A file undergoes reading and transformation into an RDD (Resilient Distributed Dataset), the immutable foundation of any Spark application. RDD embodies resilience, distribution across multiple nodes, and a collection of partitioned data with values.
RDDs offer two fundamental operations: Transformations and Actions. In the provided code, three transformations—flatMap, map, and reduceByKey—are performed on the RDD, followed by a single action, collect. This combination forms the building blocks of a robust Spark application.
Did you know ?
There are two types of transformations, Narrow transformation and Wide transformation.
| Narrow transformation |
|---|
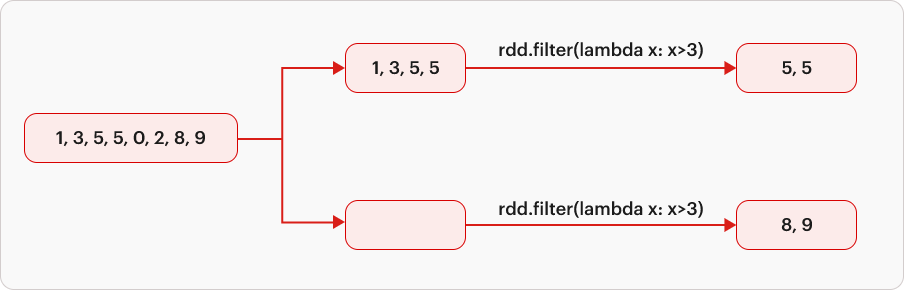 |
| In narrow transformations, the input partition influences just one output partition. It is a one-to-one function between input and output, without the need for intricate data shuffling. Classic examples include filter, select, map, and flatmap. |
| Wide transformation |
|---|
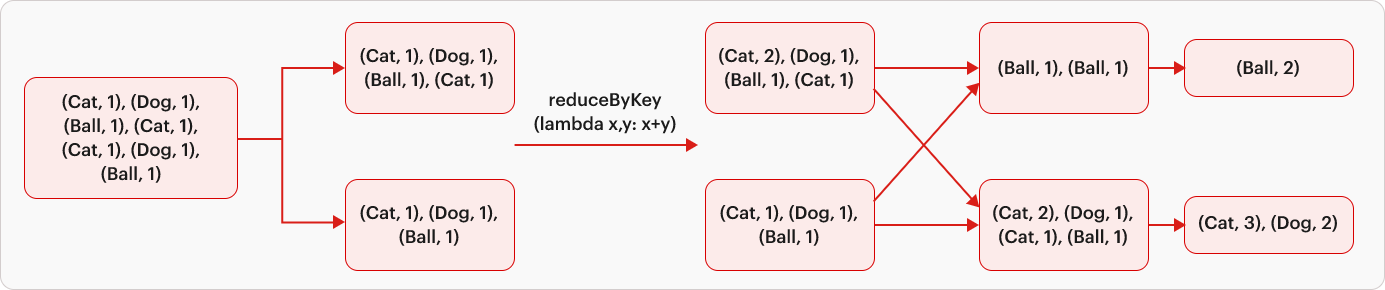 |
| In wide transformations, the input partitions take on a grander role with one-to-many function. The dynamic data shuffling ensures that data sharing the same keys end up in the same partition. Examples include reduceByKeys, groupBy, distinct, and repartition. |
Evolution of Spark DataFrame Optimizers
Initially, RDDs were widely used but lacked schema for handling diverse data types. Imagine a file with 100 records mirrored exactly by the RDD, partitioned, and dispersed across the cluster. In response, Dataframes emerged as a solution, built upon the foundation of RDDs. DataFrames inherit RDD features and add structured elegance. The diagram below encapsulates the evolution of Spark DataFrame Optimizers, a visual ode to Spark’s pursuit of optimization excellence. Let’s delve into the specifics of this evolution.
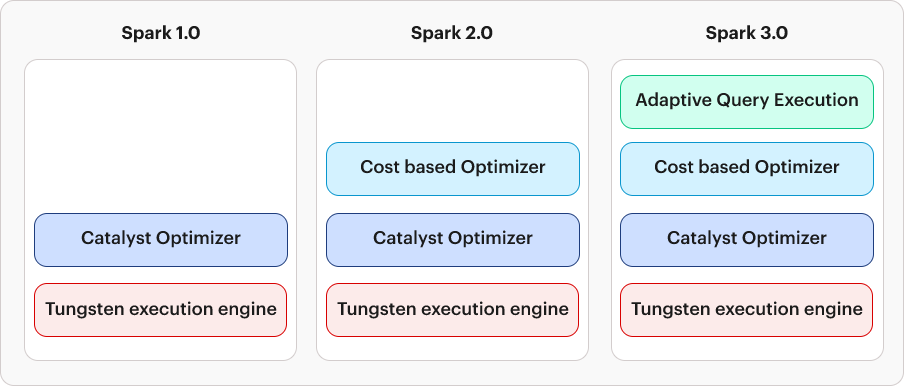
Apache 1.0

Structured by nature, DataFrames leverage the Catalyst Optimizer, dissecting the logical plan and optimizing it before physical execution. This resulted in enhanced performance that surpassed similar RDD operations. The Optimized query plan takes center stage, guided by the Tungsten engine, which compiles Spark queries into optimized bytecode for seamless execution.
Apache 2.0

Apache Spark continues to improve when Spark 2.0 introduces the Cost-Based Optimizer to assess the cost associated with distinct physical plans. Decisions are made to minimize execution time and resource usage.
Apache 3.0
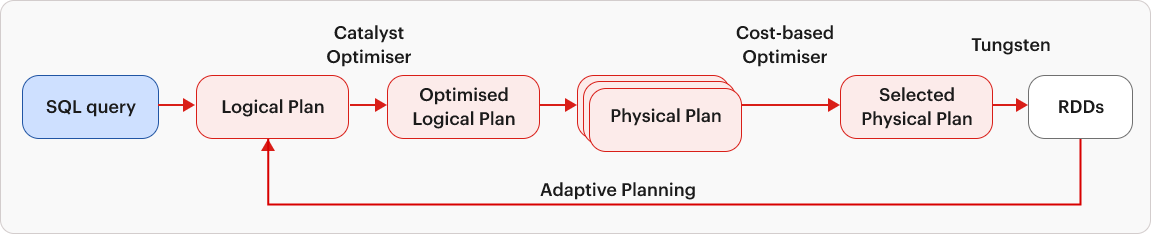
Fast forward to Spark 3.0, where Adaptive Query Execution (AQE) adjusts query execution plans based on real-time statistics, enhancing Spark’s efficiency in diverse and dynamic data scenarios.
Conclusion
Apache Spark’s evolution unveils transformative milestones whether it be Apache 1.0 laying the foundation for structured data processing or Apache 2.0 taking the lead with dynamic resource orchestration. The evolution of Spark DataFrame Optimizers highlighted a commitment to structured elegance and continuous optimization. In Apache 3.0, Adaptive Query Execution (AQE) emerged as a dynamic feature, adjusting execution plans based on real-time statistics, marking a pinnacle in Spark’s efficiency for diverse data scenarios.
As we reflect on Spark’s evolution, we witness a testament to its resilience and adaptability in the face of evolving data processing needs. The journey of Spark DataFrame Optimizers encapsulates the relentless pursuit of optimization excellence, driving innovation and empowerment in the realm of big data analytics. With each iteration, Spark continues to redefine the boundaries of possibility, propelling data-driven insights into new realms of discovery and efficiency.
About the Author
Ashish Chouhan, an Associate Software Development Engineer at Sigmoid, is a budding data engineer in the industry. His experience includes distributed computing systems such as Apache Spark, cloud-based platforms like Azure and AWS, and various data warehousing solutions. He is passionate about architecting and refining data pipelines, and shows great interest to apply his knowledge to projects that require robust data engineering solutions.