Using Datawig, an AWS deep learning library for missing value imputation
Reading Time: 4 minutes

While training a Machine Learning model the quality of the model is directly proportional to the quality of data. However, in some cases, there are a lot of missing values in the dataset affecting the quality of prediction in the long run. Several methods can be used to fill the missing values and Datawig is one of the most efficient ones.
Datawig is a Deep Learning library developed by AWS Labs and is primarily used for “Missing Value Imputation”. The library uses “mxnet” as a backend to train the model and generate the predictions.
In this blog, we will look into some of the important components of the library and how it can be used for imputing missing values in a dataset.
Important Components of the Datawig Library
To understand how the library works let’s first go through some of the important components and understand what exactly they do.
- Column Encoders
- The column encoders convert the raw data of a column into an encoded numerical representation
- We have four Column encoders present in the Datawig library:
- Sequential Encoder For sequencing text data
- BowEncoder: Bag-of-words encoding for text data. (Hashing vectorizer or tfidf based on the algorithm used)
- Categorical Encoder: One hot encoding for categorical columns
- Numerical Encoder: For encoding numerical columns
- Column Featurizers
- Column featurizers are used to feed encoded data from “Column Encoders” into the imputer model’s computational graph for training and prediction
- We have four column featurizers present in the Datawig library:
- LSTMFeaturizer:To be used with Sequential Encoder and maps Sequence of input into vectors using LSTM
- BowFeaturizer: To be used with Bag-of-Words encoded columns
- EmbeddingFeaturizer: Maps encoded categorical columns into vector representation (word embeddings)
- NumericalFeaturizer: To be used with numerical encoded columns and extract features using fully connected layers
- Simple Imputer
- Using a simple imputer is the simplest way one can train a missing value imputation model. It only takes the below three parameters:
- Input_column: This represents the list of feature columns
- Output_column: This takes the name of the target column that one is training
- Output_path: The path where the trained model is supposed to be stored
- Say we have a dataset with 3 different columns a, b, c and based on a and b we want to fill the missing values of column c. Then, simple imputer will work as follows:
imputer = SimpleImputer(
input_columns=['a', 'b'],
output_column='c',
output_path = 'imputer_model'
)
#Fit an imputer model on the train data
imputer.fit(train_df=df_train)
predictions = imputer.predict(df_test)
- Imputer.fit: To train model
- Imputer.fit_hpo: To train and tune the model. It has a dictionary built in to choose the values from, also one can pass hyperparameters in the form of a custom dictionary to tune the model based on project requirements
- Imputer gives more control over the training process, which is one of the primary reasons for using Imputer over simple imputer
- Imputer takes four parameters as input:
- Data_featurizers: It’s a list of featurizers associated with different feature columns
- Label_encoders: It’s a list of encoded target columns
- Data_encoders: It’s a list of encoders associated with different feature columns
- Output_path: The path where the trained model is supposed to be stored
- Say we have a dataset with 3 different columns a, b, c, and based on a and b we want to fill the missing values of column c. Then, imputer will work as follows:
data_encoder_cols = [BowEncoder('a'), BowEncoder('b')]
label_encoder_cols = [CategoricalEncoder('c')]
data_featurizer_cols = [BowFeaturizer('a'), BowFeaturizer('b')]
imputer = Imputer(
data_featurizers=data_featurizer_cols,
label_encoders=label_encoder_cols,
data_encoders=data_encoder_cols,
output_path='imputer_model'
)
imputer.fit(train_df=df_train)
predictions = imputer.predict(df_test)
- More customization is possible for the training process
- Tuning the parameters while encoding the feature and target columns to get a balance between the training time and accuracy of the model
How Datawig Helped in my Project?
- Overview of the Project
- We had a dataset with 50 different columns and we had to impute the missing values on 25 different columns out of those 50
- Out of the 25 columns 13 columns were numerical and 12 were categorical
- Part summary of the dataset
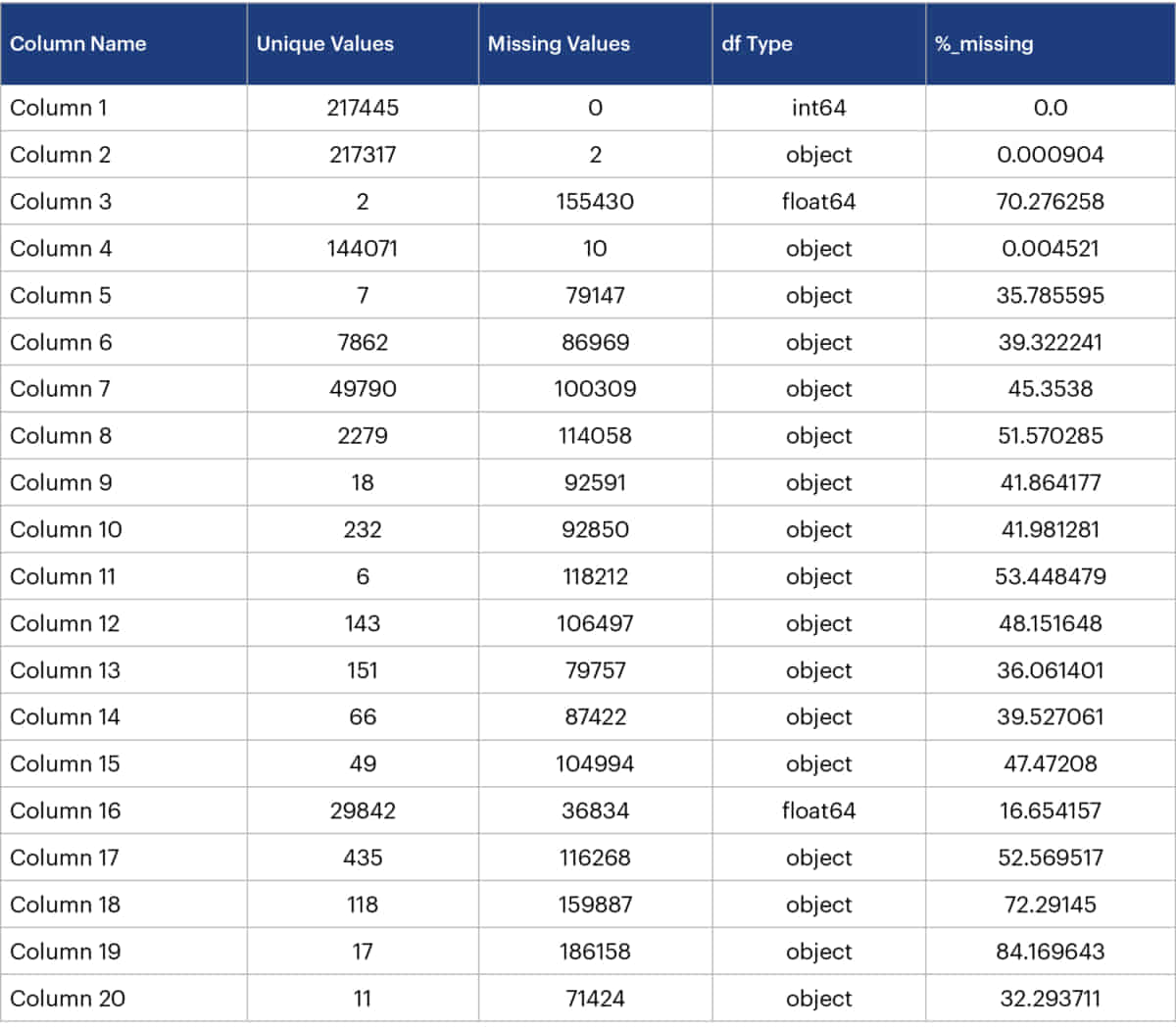
- Approach
- For each of the target columns (25 columns for which we are doing the imputation), we did the feature selection and then ran the Datawig using the Imputer Since we can run the Imputer over all the target columns, at one time on the loop it was pretty straightforward. After the base model results we went on to tune the model and below were the final results on the target columns.
- Numerical Columns:
- Categorical Columns:
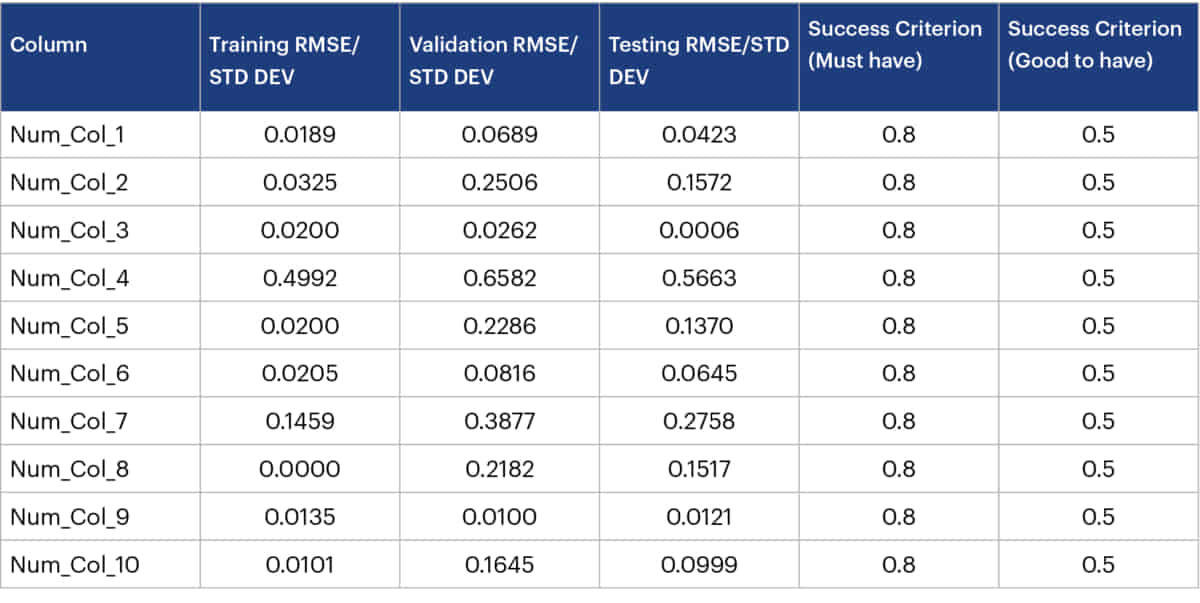
The client-defined metric was RMSE/Standard deviation of <= 0.5 for the numerical columns while the acceptable score was RMSE/Standard deviation of <= 0.8. In the above table, the computed metrics are mentioned for all the Numerical columns against their respective training, validation, and testing dataset. We could achieve a standard deviation of <0.5 for numeric columns.
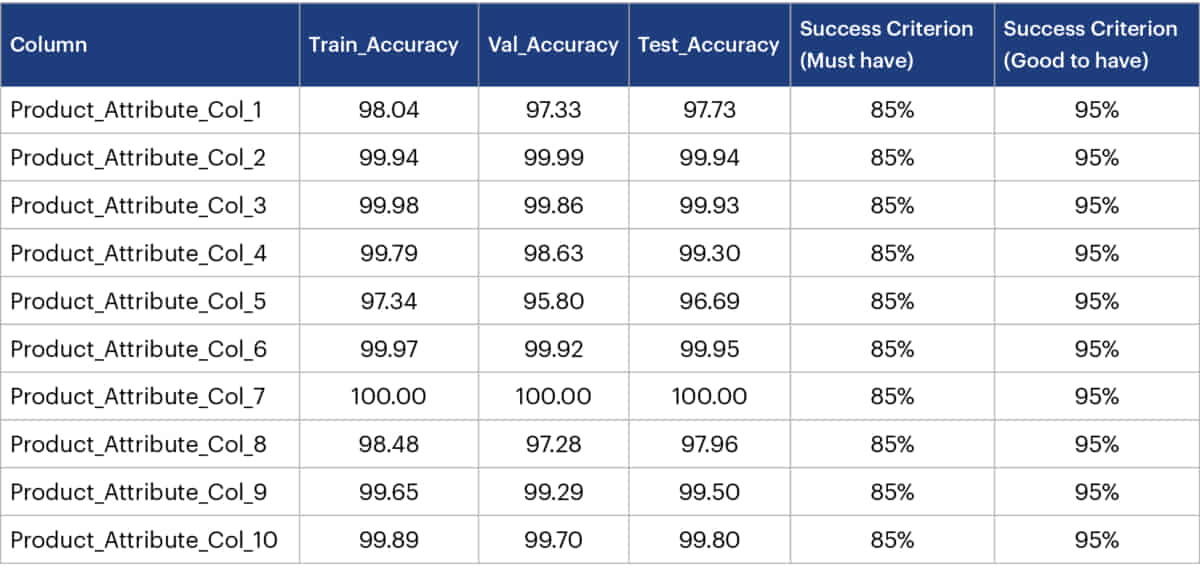
For the categorical columns, we used accuracy as the key metric. The ideal criteria were to achieve accuracy of >= 95% and acceptable criteria were to achieve accuracy of >= 85%. We could achieve >90% accuracy in predicting categorical data.
Conclusion
Datawig as an imputation tool is a great choice whether one wants to solve simple imputation problems or complex scalable imputation problems with comparable and sometimes even better results than the other standard practices. It’s a nice tool to have in your repository.
About the Author
Anurag Srivastava is a Data Scientist at Sigmoid. He works on data modelling process along with predictive model design to gain insights on Business data. Currently, his work focuses on “Demand Forecasting” in Supply Chain.
Featured blogs







Featured blogs