---
# Proven methods to reduce AWS cloud infrastructure cost
**URL:** https://www.sigmoid.com/blogs/proven-methods-to-reduce-aws-cloud-infrastructure-cost/
Date: 2020-11-17
Author: Sigmoid
Post Type: post
Summary: As organizations grow, so does their data and the costs associated with handling data. With the advancement in data engineering services, cloud...Read More...
Categories: Cloud Transformation
Tags: AI/ML, Data Management
Featured Image: https://www.sigmoid.com/wp-content/uploads/2023/11/Proven-Methods-to-Reduce-AWS-Cloud-Infrastructure-Cost-banner-opt.jpg
---
As organizations grow, so does their data and the costs associated with handling data. With the advancement in [data engineering](/ebooks-whitepapers/data-engineering-overcome-challenges-in-enterprise-analytics/) services, cloud computing has become more timely and prominent than ever. Most large businesses today are [migrating from on-prem to cloud](/cloud-migration/) environments, and there is an increasing focus on cloud cost optimization as spends can eventually go unchecked and result in increased IT overheads.
Many instances such as EC2 in AWS provide a cloud computing platform. Amazon EC2 pricing is free to try which may then include costs associated with the services availed. In this blog we will look at some methods based on real world experiences that have helped businesses in effective [AWS cloud hosting](/events/cloud-webinar/) cost management.
Here are some essential prerequisites to keep in mind while dealing with [cloud infrastructure](/cloud-migration/)
- Look at cost optimization as a practice rather than a one time activity
- Ensure proper tagging practice is in place by company/function/product/team/environment. Follow this link for best practices.
- Get in-depth information on cost details to define the right set of activities for reducing cost.
- Choose a custom monitoring solution if needed. If the billing dashboard doesn’t provide the report the way you needed it, get a custom monitoring solution. Maybe just a script using a billing API to figure out cost at day level by division/team/product. At Sigmoid we have developed an [in-house tool](/accelerators/sigview/) which provides in-depth cost segregation.
## Making the most out of AWS credits
With growing competition among cloud providers, all major providers including Amazon, lend cloud credits for migrating to their platform or staying with them. However, they may ask for a term commitment or request for use cases to offer these credits.
Startups can tie up with accelerator/angel-fund providers or affiliated to organizations such as Nasscom “10000 startups”(India) will help you start building products without any upfront investment on [cloud infrastructure](/cloud-migration/). You get credit up to $100,000 from various cloud providers including [AWS](/events/cloud-webinar/) based on the problem that you are trying to solve with your product.
Talking about AWS cloud hosting cost, there is also AWS Activate, which provides startups with a host of benefits, including AWS credits, technical support and training, to help grow your business. It offers credit up to $100K based on the use case.
In case of enterprises, if the account is tied with AWS reseller partner then you can negotiate for a discount up to 5%. Additionally, Amazon also offers credits for POCs if they see that the concept could increase cloud utilization over the period of time.
## Saving on compute costs
- Select the right instance family: While working with our clients, we noticed that they often use the wrong instance family. i.e one of them was using C type instances for memory intensive workloads as a result of which they had to opt for bigger instances which eventually resulted in higher costs.
- Use Spot wherever possible (stateless infra): For data analytics workloads, we noticed that on many occasions we have to launch 100’s of machines for a few mins to run these workloads and then stop them. Our own PaaS infrastructure runs on 85%+ spot instances and for a few we opted for spotinst, where we need to ensure that the data is intact despite machines being restarted. Before considering spot check for suitable instance and interruption using spot advisor [link](https://aws.amazon.com/ec2/spot/instance-advisor/).
- Leverage spotinst (now spot.io): Spotinst is a great way to get spot instances for persistence data storage. It ensures that your ENI and storage is re-attached to a new instance along with public IP but we don’t recommend spot/spoinst for workload where downtime has severe business impact.
- Use EC2 Fleet: This option allows combining both on-demand and spot instances. Instances need to be defined in units, we can have different types of instances in a fleet.
- Use the latest generation instance type on Dev: We notice that each time AWS comes up with a new generation, they offer 8-10% discount/hr and 10-40% performance boost. We have a practice of keeping our own product dev workload on latest instances. This helps us reduce cost and achieve better performance. Also, this helps to test workloads on new instances before pushing it on Staging and Production environments.
- Plan migration to latest generation instances for QA/Prod: Until now, we have migrated to the latest instances twice. In the 5th generation, there were some issues while running the Hadoop cluster. Therefore we recommend thorough functional, performance and load testing on staging environment before migrating to the production environment.
- Use a reserved instance: around 8% instances are reserved for longterm stateful workloads. Also look to find instances on the marketplace to get better price and less commitment tenure. When selecting a reserve instance choose the right type class.
- Shutdown instances when not in use: This refers to shutting down dev instance post business hours if they are not being used. Instead of providing AWS access to developers, we have Jenkins jobs through which they can request for instances. Along with the number of days they need an instance, they have to define usual working hours so that the cron keeps the machines running during the specified working hours.
- Use Autoscaling: We recommend Auto-scaling in production environments to accommodate for spike in traffic without having a major impact on costs. For our in house PaaS, we have created a custom auto-scaling script which works based on events.
- Select the right region. Do compare pricing of services you’re planning to use with region options available. In some regions you may end up paying almost two times more.
- Define custom auto scaling for [big data](/blogs/etl-on-cloud-transforming-big-data-analytics/) workloads: This ensures better control on cost without hampering the performance. For one of our use cases, we perform auto-scaling based on custom events in the application. This reduced big data workload cost by 40%.
- Consider [containerization](/blogs/containerization-of-pyspark-using-kubernetes/) or serverless: If you have stateless applications then this is one of the best options to optimize costs and save management effort. We have converted our monolithic UI app to microservices based on the 12factor.net recommendation. It was then containerized, and used along with a helm chart. We were able to save almost 70% of the cost to host these microservices compared to virtual machine based infra. No manual interventions needed for deployment/scaling.

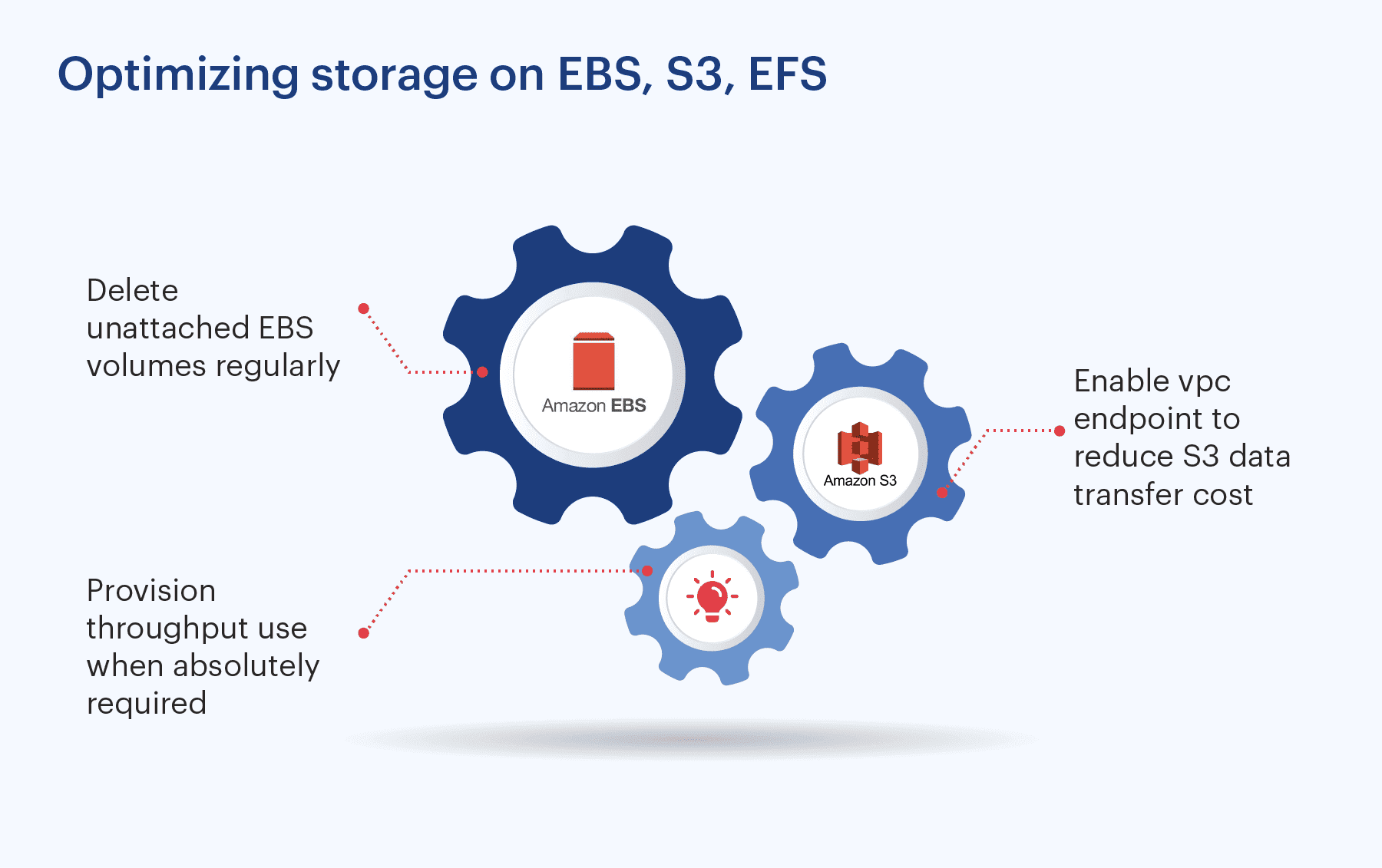
## Optimizing Storage:
There are 3 options offered by Amazon but choose the right storage based on requirements.
**Amazon EBS – Block storage**
There are 5 different types of EBS volumes. While creating an EBS volume select the right EBS storage type based on performance and durability needs. Provisioned IOPS are expensive and it is recommended that they are used only on critical systems where there is a need for high performance i.e Databases.
In our self managed Hadoop cluster we use gp2 storage to just store Hadoop cluster logs. For data storage, we use object storage. These are the few standards we follow internally to keep EBS costs low.
- Create EBS volumes with minimal buffer size than required (max 20%).
- Keep application logs on a dedicated disk.
- Delete unattached EBS volumes regularly.
- Enable the “Delete on Termination” option on non-critical instances.
- Delete obsolete Snapshots
- Use LVM.
- Terminate Instances that are not in use. Just stopping them will only reduce instance costs but EBS costs will prevail.
**Amazon S3**
**Object storage:** There are 6 storage classes that are designed to accommodate different access requirements. This guide by Amazon will help you to choose the right class for your use case.
- Setup right policy for the data archival or deletion
- Enable vpc endpoint to reduce S3 data transfer cost.
** Amazon EFS – file storage**
- There are multiple classes that are designed to accommodate frequent or in-frequent data access requirements.
- Setup right policy for the data migration from general purpose to infrequent access class storage to reduce cost drastically.
- Provision throughput use when absolutely required.
## Our rule book for Databases, Networking and EMR
Databases:
- Select the right instance class: As mentioned under the Compute section, choosing the right class is very important.
- Select the right instance size: Our mantra for Dev/QA environments, start with lowest and increase based on need. For production environments, run a performance test to choose the best option.
- Opt for Reserved instances: For predictable workload choose reserve instances and save up to 35%. These reserved instances cant be sold on the marketplace so be mindful while choosing the reserve instances or choose flexi type reserved instances.
- Use instance stop wherever database engines support them. This can be used for the Dev and QA instances to reduce cost.
- Choose the right storage type according to workload. E.g. EBS storage.
- Evaluate using a PoC wherever Aurora serverless is being used. Since there are certain limitations here. But if they are not a concern, consider switching.
- Keep snapshot retention period as per restoration plan.
- Enable storage autoscaling to avoid over-provisioning.
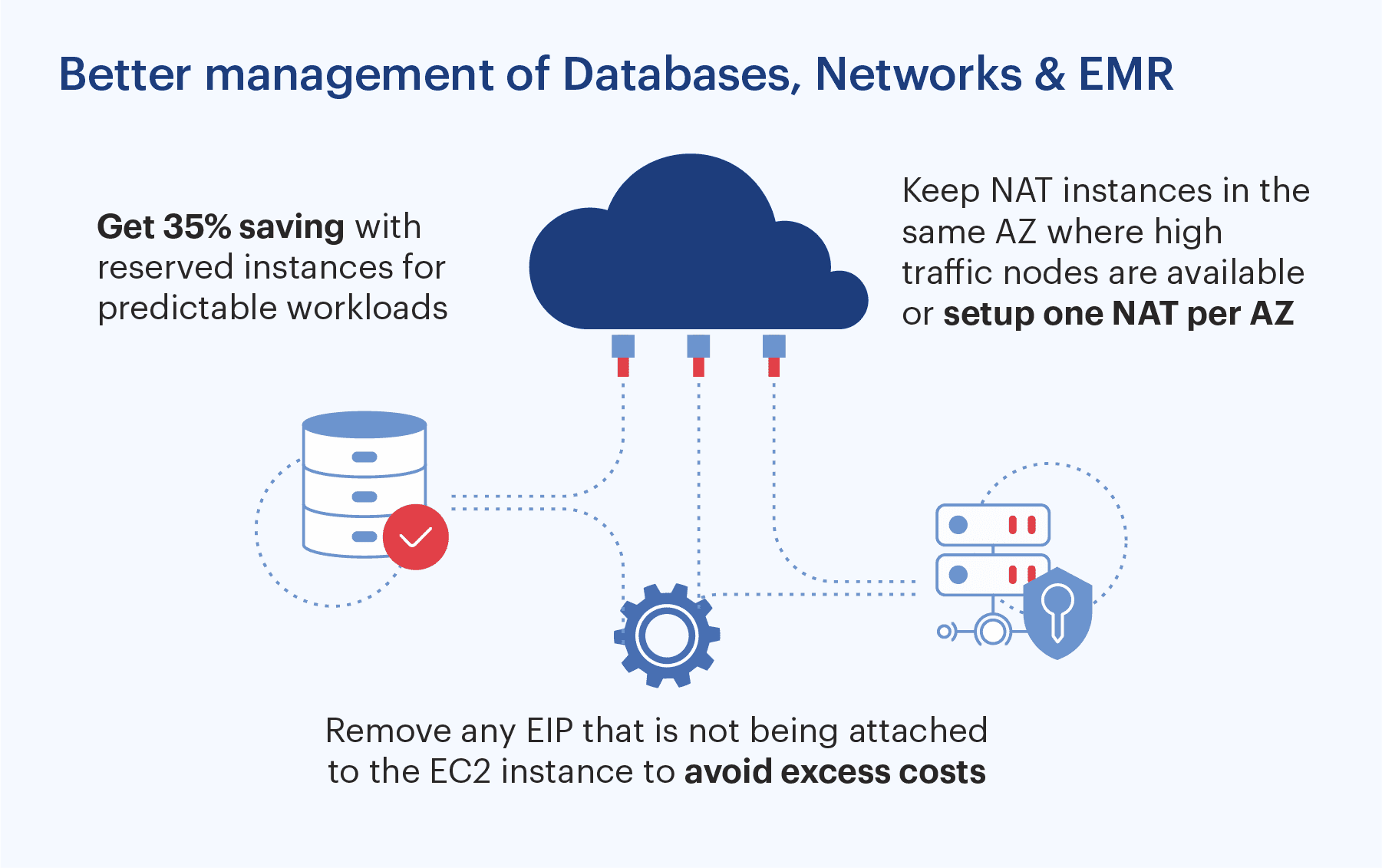
Networking
- Elastic IP: Remove any EIP that is not being attached to the EC2 instance to avoid excess costs
- VPC endpoint: Use VPC endpoint for S3 and Dynamodb to reduce data transfer cost on both services.
- Nat Gateway: Keep NAT instances in the same AZ where high traffic nodes are available or setup one nat per AZ.
Data transfer:
- Inter-Region data transfer: Accessing data from AWS S3 via EC2 instance in the different region is charged.
- Data Transfer within the same AWS Region: Data transfer across Availability Zones or VPC Peering connections in the same AWS Region is charged.
EMR
EMR can now be launched with 3 master nodes. To create a cost-effective infrastructure, we can use Instance fleets, where we can use Core nodes with minimum spot and maximum on-demand. Use Tasks node completely on the spot which will be used as executors thereby reducing costs, there are options to use auto-scaling with custom policy and also managed auto-scaling.
There are other services where we can save costs such as ElastiCache/redshift etc. In our next blog, we will target cost-saving options by each service.
## Conclusion
In this blog we have listed the practices we have followed on AWS over the years to have an optimized and cost-effective infrastructure. This comes as an outcome of continuous research, where we have created dashboards with timelines from two days up to two months, for comparing and understanding the costing of different services. This is aligned with the philosophy for [DevOps](/data-devops/) at Sigmoid that includes adherence to predefined KPIs for identifying and optimizing infrastructure costs.
## About the author
Jagan is a Dev Ops evangelist who leads the Dev Ops practice at Sigmoid. He has instrumental in maintaining and supporting highly critical data systems for clients across CPG, Retail, AdTech, BFSI, QSR and Hi-Tech verticals.
Join our upcoming webinar – [Reduce AWS Costs of High Volume ETL Pipeline by up to 65%](/events/cloud-webinar/), on 17 December to learn more from industry experts.
[lc_the_tags]
## Featured blogs
[lc_get_posts post_type="post"
posts_per_page="4" orderby="date" output_view="lc_get_posts_mycustom_view" output_number_of_columns="4"
output_wrapper_class="row" output_article_class="shadow" output_hide_elements="Excerpt"
output_excerpt_length="0" output_excerpt_text="Read More" output_heading_tag="span"
output_featured_image_format="thumbnail" output_featured_image_class="card-img-left" ]
## Share
[addtoany]
Subscribe to get latest insights
## Talk to our experts
Get the best ROI with Sigmoid’s services in data engineering and AI
## Suggested readings
[View all](/blogs/)

#### [Using Datawig, an AWS Deep Learning Library for Missing Value Imputation](/blogs/datawig-missing-value-imputation/)
[Read blog](/blogs/datawig-missing-value-imputation/)

#### [Sigmoid enables significant cost reduction on Google Cloud Platform for Reckitt](https://www.sigmoid.com/press-release/google-cloud-platform-for-reckitt/)
[Read blog](https://www.sigmoid.com/press-release/google-cloud-platform-for-reckitt/)

#### [Best Practices for Adopting Multi-Cloud Strategy in your Organization](/blogs/multi-cloud-strategy/)
[Read blog](/blogs/multi-cloud-strategy/)
---
## Categories
- Cloud Transformation
---
## Navigation
- [WordPress.org](https://wordpress.org/)
- [Documentation](https://wordpress.org/documentation/)
- [Learn WordPress](https://learn.wordpress.org/)
- [Support](https://wordpress.org/support/forums/)
- [Feedback](https://wordpress.org/support/forum/requests-and-feedback)
- [Sigmoid](https://www.sigmoid.com/)
- [Community](https://community.wpmanageninja.com/portal/space/fluent-forms/home)
- [Docs](https://wpmanageninja.com/docs/fluent-form/)
- [Developer Docs](https://developers.fluentforms.com/)
- [Documentation](https://imagify.io/documentation/)
- [Rate Imagify on WordPress.org](https://wordpress.org/support/view/plugin-reviews/imagify?rate=5#postform)
- [Manage](admin.php?page=litespeed)
- [Settings](admin.php?page=litespeed-cache)
- [Image Optimization](admin.php?page=litespeed-img_optm)
- [Company](/about-sigmoid)
- [Newsroom](/newsroom)
- [Life at Sigmoid](/careers)
- [Takshashila](/takshashila)
- [Contact Us](/contact-us)
- [AI Strategy Blueprint your AI advantage](/enterprise-ai-strategy/)
- [Generative AI Drive innovation with Generative AI](/generative-ai/)
- [Responsible AI Build trust with ethical AI practices](/responsible-ai-in-enterprise/)
- [Agentic AI Reshape business with scalable agentic systems](/agentic-ai-solutions/)
- [AI Managed Services Ensure reliable AI performance](/ai-managed-services/)
- [Advanced Analytics Transform your business with data-driven insights](/advanced-data-analytics-solutions/)
- [Start Assessment](/agentic-ai-readiness-index/)
- [Data Strategy Strong data foundations for scalable AI](/data-analytics-strategy/)
- [Data Management Leverage data as a strategic asset](/ai-data-management-services/)
- [Data Ops Automate data for speed and quality](/data-devops/)
- [Data Engineering Deliver insights faster with scalable pipelines](/data-engineering/)
- [Cloud Transformation Modernize data to maximise efficiency](/cloud-migration/)
- [Download Whitepaper](/ebooks-whitepapers/building-data-products-in-a-data-mesh-to-drive-business-value/)
- [Data Modeling Structure data for better decisions](/data-modeling-services/)
- [Data Visualization Transform data into actionable stories](/data-visualization-service/)
- [BI Migration Enhance decision making with modern BI tools](/bi-migration/)
- [Data Observability Build trust with healthy, accurate data](/data-observability/)
- [Automated Insights Make smarter decisions with auto-generated insights](/automated-insights/)
- [Download Whitepaper](/ebooks-whitepapers/power-bi-hacks/)
- [CPG & Retail End-to-end analytics for planning, operations, and commercial excellence](/industries/cpg-analytics/)
- [Life Sciences Trusted intelligence across clinical, commercial, and operational workflows](/industries/life-sciences/)
- [Financial Services AI-powered analytics for risk, compliance and customer experience](/industries/banking-financial-analytics-services/)
- [Read case study](/case-studies/data-clean-room-enables-real-time-insights-to-improve-operational-efficiency/)
- [MediaIQ Advanced platform for in-flight marketing measurement](/accelerators/sigmoid-mediaiq-multi-touch-attribution-tool/)
- [CampaignIQ AI-driven platform for optimized campaign budget allocation](/accelerators/sigmoid-campaigniq/)
- [AssistBot GenAI email assistant that automates human-like responses](/accelerators/sigmoid-assistbot-for-ai-email-assistant/)
- [CreativeBot GenAI tool for personalized and brand-aligned creative design](/accelerators/sigmoid-creativebot/)
- [SocialBot GenAI platform to analyze digital conversations and trends](/accelerators/#marketing|socialbot)
- [DemandIQ Predict trends accurately and optimize inventory management](/accelerators/sigmoid-demandiq/)
- [NetworkIQ Track and optimize logistics operations in real-time to quickly address disruptions](/accelerators/sigmoid-networkiq/)
- [SupplyIQ End-to-end platform to optimize supply chain operations](/accelerators/sigmoid-supplyiq/)
- [ProcurementIQ Automated procurement operations for maximum savings, compliance and efficiency](/accelerators/sigmoid-procurementiq/)
- [RapidML Accelerated deployment for machine learning models](/accelerators/sigmoid-rapidml/)
- [DataGuard Comprehensive platform for proactive data quality management](/accelerators/data-quality-tool-sigmoid-dataguard/)
- [CloudPulse Cloud cost optimization platform with multi-cloud management](/accelerators/sigmoid-cloudpulse/)
- [RAPID GenAI foundation with built-in governance and cost clarity](/accelerators/sigmoid-rapid/)
- [AnalyticsBot GenAI based platform to streamline decision-making in analytics](/accelerators/sigmoid-analyticsbot/)
- [DataConnect Seamlessly ingest, integrate and harmonize data from diverse sources](/accelerators/sigmoid-dataconnect/)
- [Reconica AI-powered data harmonization and reconciliation engine](/accelerators/sigmoid-reconica/)
- [ConverseBot GenAI driven insights generation for automated insights from reports](/accelerators/#sales|conversebot)
- [iNRM Cross-lever revenue growth optimization platform](/accelerators/sigmoid-inrm/)
- [AssortmentIQ Optimize shelf layouts and assortment mix at scale with AI-based insights](/accelerators/sigmoid-assortmentiq/)
- [Read Whitepaper](/ebooks-whitepapers/building-agentic-ai-chatbots-for-business-process-transformation/)
- [Listen Podcast](/events/podcast/how-jack-in-the-box-is-redefining-personalization-and-supply-chain-with-ai/)
- [Blogs](/blogs/)
- [White Papers](/ebooks-whitepapers/)
- [Case Studies](/case-studies/)
- [Podcast](/events/podcast/#Podcasts)
- [Read Blog](/blogs/the-genai-adoption-triad-responsibility-ethics-and-explainability/)
- [ConverseBot](/accelerators/#sales|conversebot/)
## Tags
- AI/ML
- Data Management
---
## Footer Links
- [Talk to our AI experts](/contact-us/)
- [AI Strategy](/enterprise-ai-strategy/)
- [Agentic AI](/agentic-ai-solutions/)
- [Generative AI](/generative-ai/)
- [AI Managed Services](/ai-managed-services/)
- [Responsible AI](/responsible-ai-in-enterprise/)
- [Advanced Analytics](/advanced-data-analytics-solutions/)
- [Data Strategy](/data-analytics-strategy//)
- [Data Engineering](/data-engineering/)
- [Data Management](/ai-data-management-services/)
- [Cloud Transformation](/cloud-transformation/)
- [Data Ops](/data-devops/)
- [Data Visualization](/data-visualization-service/)
- [Automated Insights](/automated-insights/)
- [BI Migration](/bi-migration/)
- [Data Modeling](/data-modeling-services/)
- [Data Observability](/data-observability/)
- [CPG & Retail](/industries/cpg-analytics/)
- [Financial Services](/industries/banking-financial-analytics-services/)
- [Life Sciences](/industries/life-sciences/)
- [Case Studies](/case-studies/)
- [Thought Leadership](/ebooks-whitepapers/)
- [Blogs](/blogs/)
- [Company](/about-sigmoid/)
- [Newsroom](/newsroom/)
- [Accelerators](/accelerators/)
- [Careers](/careers/)
- [Privacy Policy |](/privacy-policy/)
- [Cookie Policy](/cookie-policy/)