Fault tolerant stream processing with Spark Streaming
Reading Time: 4 minutes

After a look at how Spark Streaming works, and discussing good production practices for Spark Stream processing, this blog talks about making your Spark streaming implementation fault-tolerant and highly available.
Fault tolerance
If you plan to use Spark Streaming in a production environment, it’s essential that your system be fault tolerant. Fault tolerance is the capability to operate even after a failure and the possibility to recover from it. For a system to recover from failure you need redundant components that can replace faulty counterparts. The state of the system needs to be maintained — no data or state can be lost. A spark streaming system is primarily composed of 3 main components – master, slave and a receiver.
Spark and Spark Streaming with the RDD concept at the core are inherently designed to recover from worker failures. RDDs (Resilient Distributed Datasets), as the name suggests can regain their state by re-computation of lost blocks in case of failure. DStreams utilize the capability of underlying RDD’s to recover from failures.
To recover from failures, you need to ensure that all components are fault tolerant. Spark Streaming system is composed of a master and a Worker. Master executes the driver program and the Worker executes the Receiver and Executors. Driver program is responsible for running the job, interacting with the user(job submitter), collecting the output to submit it to the user.
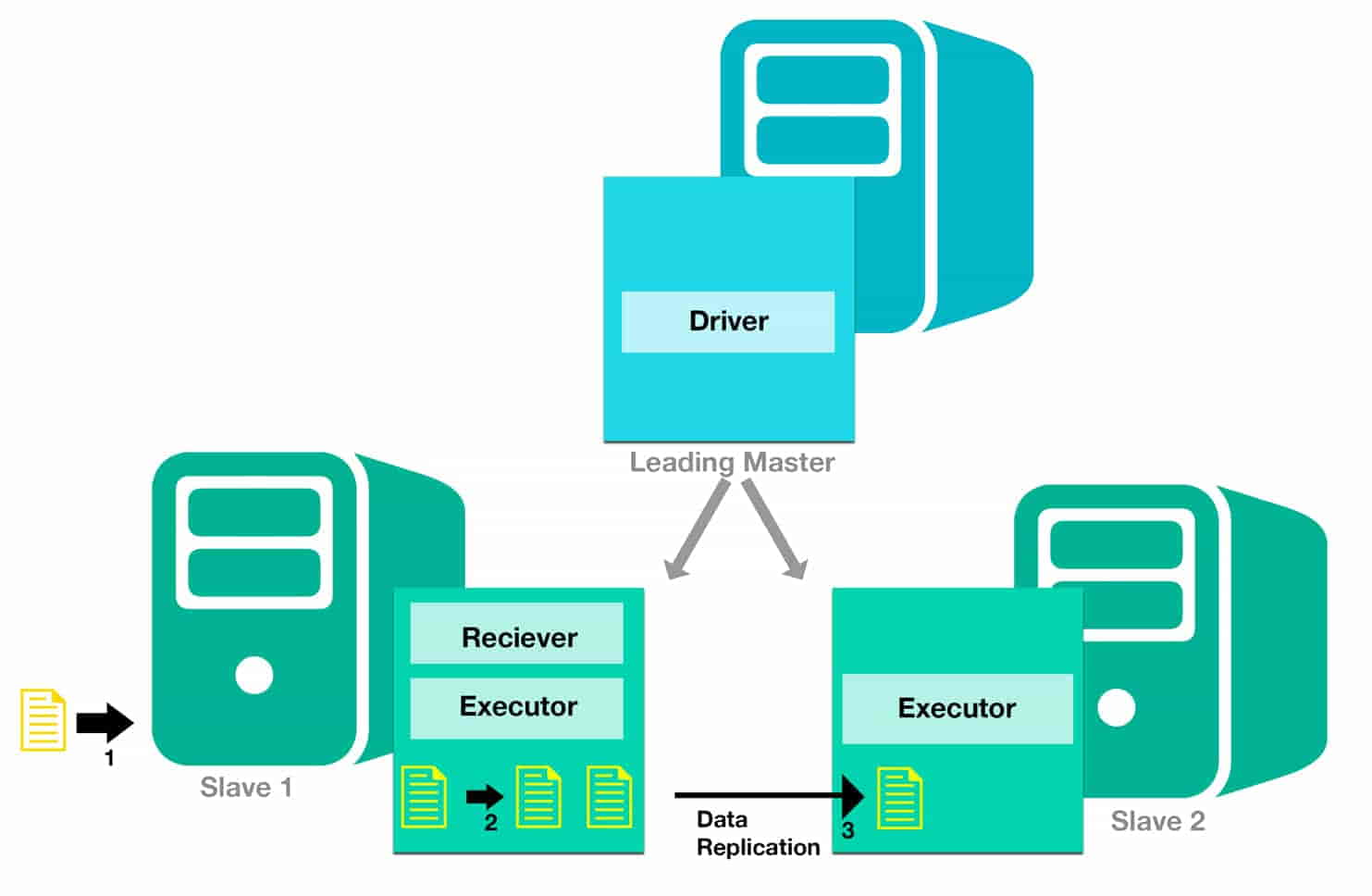
Mesos helps in making the master fault tolerant by maintaining backup masters. Executors are relaunched if they fail. Post failure, executors are relaunched automatically and spark streaming production does parallel recovery by re-computing RDD’s on input data. Moreover the data received by the receiver is replicated on another Spark Slave. But for the system to be fault tolerant external components need to support the fault tolerance. Receivers run as long running tasks by the worker, and are restarted by the worker when they fail. You can implement receivers using Custom Akka actors, with a supervisor for them to auto heal in case they fail.
This is a simple Akka based custom receiver.
| class SampleActorReceiver[T: ClassTag](urlOfPublisher: String) extends Actor with ActorHelper { lazy private val remotePublisher = context.actorSelection(urlOfPublisher) def receive: PartialFunction[Any, Unit] = { case msg => store(msg.asInstanceOf[T]) }} |
To add a supervisor, add the below code inside your Actor class. The below code limits the no of retries to bring up the system to 10 within one minute and also depicts the various directives in practice.
| override val supervisorStrategy = OneForOneStrategy(maxNrOfRetries = 10, withinTimeRange = 1 minute) { case _: ArithmeticException => Resume case _: NullPointerException => Restart case _: IllegalArgumentException => Stop case _: Exception => Escalate } |
Spark Streaming also provides Write Ahead logs for fault tolerance, all the received data is written to write ahead logs before it can be processed by a spark streaming. In case of failure, the data can be replayed from the logs to avoid any data loss. WAL can lead to getting the same data processed twice while recovering from failure, hence the use of Kafka Direct receiver is more preferable.
High Availability
A system is said to be highly available if it has tolerable downtime, the time duration would depend on how critical the application is. It is impossible for a machine to have zero downtime. Say from past data we know that a machine has an uptime of 97.7%. We can say that it has a probability of 0.023 of going down, similarly if we have 2 redundant systems the probability of both of them going down at the same time is 0.023*0.023. In most High availability environments we have 3 machines in use, in that case the probability of going down is (0.023*0.023*0.023). After doing the maths it comes out to be 0.000012167, this implies that the system guarantees an uptime of 99.9987833%. 97.7 might not be acceptable but 99.9987 is an acceptable uptime guarantee.
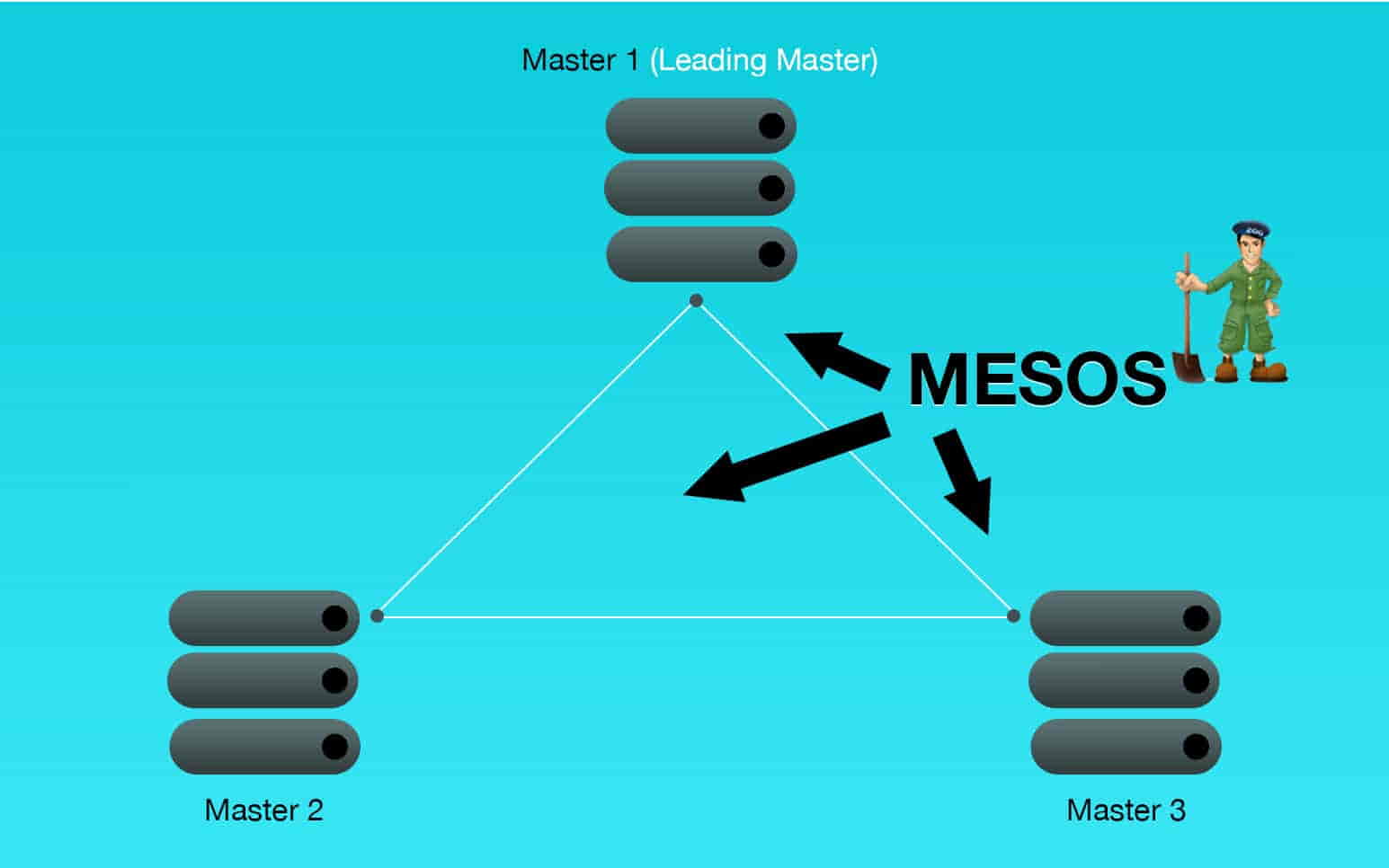
With Spark Streaming we use Mesos, for understanding purposes, it can be assumed to be a distributed operating system. It manages the CPU, memory and other resources for applications like Spark, Hadoop, Kafka or ElasticSearch. With the advent to Distributed computing, Mesos has hit the hot rod. There was a need for a cluster manager that would take care of all the day to day tasks of a cluster. And with more and more applications going the distributed way, Mesos has emerged at the right time for data stream processing.
When Mesos is used with Spark it takes over the job of the Spark Master, it decides what tasks are to be allocated to which slave. Mesos has to make the Driver highly available as it manages backup masters with the help of zookeeper. When the leading master goes down, zookeeper selects a new leader and the execution is continued on the new leading master.
Elected masters feed the metadata from the leading master all the time, when the leading master goes down the new leading master can start from the point where the previous leading master left.
About the Author
Arush was a technical team member at Sigmoid. He was involved in multiple projects including building data pipelines and real time processing frameworks.
Featured blogs







Featured blogs