---
# Fault tolerant streaming workflows with Apache Mesos
**URL:** https://www.sigmoid.com/blogs/fault-tolerant-streaming-workflows/
Date: 2015-04-09
Author: Sigmoid
Post Type: post
Summary: Mesos High Availability Cluster Apache Mesos is a high availability cluster operating system as it has several masters, with one Leader. The...Read More...
Categories: Data Management
Tags: Cloud Transformation
Featured Image: https://www.sigmoid.com/wp-content/uploads/2023/01/Fault-tolerant-Streaming-Workflows-with-Apache-Mesos-banner.png
---
## Mesos High Availability Cluster
Apache Mesos is a high availability cluster operating system as it has several masters, with one Leader. The other (standby) masters serve as backup in case the leader master fails. Zookeeper elects the master nodes and handles the failures.
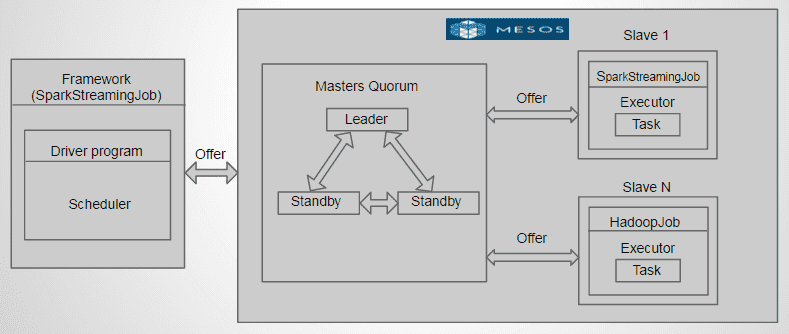
Mesos is framework independent and can intelligently schedule and run [Spark](/blogs/spark-streaming-internals/), Hadoop, and other frameworks concurrently on the same cluster.
Before diving deep into how fault tolerance streaming workflows can be created with Apache Mesos, we will have a quick overview of Spark and [Spark Streaming](/blogs/spark-streaming-internals/).
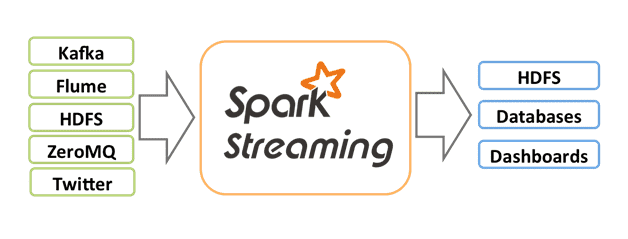
Spark powers a stack of frameworks including Spark SQL, MLlib for [machine learning](/data-science-services/), GraphX, and Spark Streaming. You can combine these libraries seamlessly in the same application.
## RDDs
**R**esilient **D**istributed **D**atasets (RDDs) are a Big collection of data which are Immutable (can’t be changed once created), Distributed (across the cluster),Lazily evaluated (won’t do anything unless action is triggered.), Type Inferred (the compiler will figure out the object type), Cacheable (can load whole dataset into memory).
Many big-data applications viz., monitoring systems, alert systems, computing systems to name a few, need to process large data streams in near-real time. Spark Streaming can process large chunks of data, runs streaming computation as a series of small, batch jobs. In Spark Streaming, the incoming data is split into small batches of time interval (200ms by default) and Spark treats each batch data as a RDD and processes them using RDD operation, which are returned in batches after processing.
### Spark Streaming over a HA Mesos Cluster
To use Mesos from Spark, you need a Spark binary package available in a place accessible (http/s3/hdfs) by Mesos, and a Spark driver program configured to connect to Mesos.
Configuring the driver program to connect to Mesos,
val sconf = new SparkConf()
.setMaster(“mesos://zk://10.121.93.241:2181,10.181.2.12:2181,10.107.48.112:2181/mesos”)
.setAppName(“MyStreamingApp”)
.set(“spark.executor.uri”,”hdfs://Sigmoid/executors/spark-1.3.0-bin-hadoop2.4.tgz”)
.set(“spark.mesos.coarse”, “true”)
.set(“spark.cores.max”, “30”)
.set(“spark.executor.memory”, “10g”)
val sc = new SparkContext(sconf)
val ssc = new StreamingContext(sc, Seconds(1))
### Failure in simple streaming pipeline
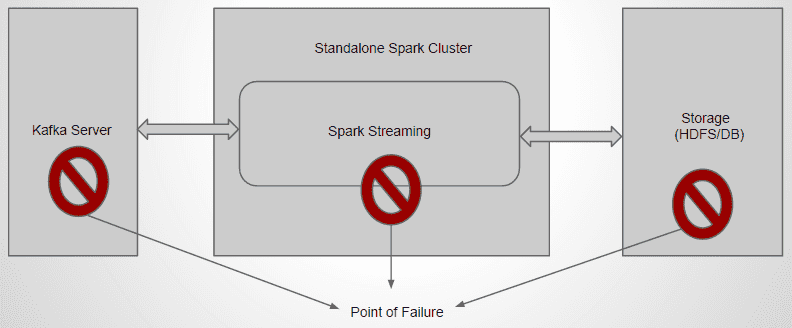
With a simple spark streaming pipeline as shown in the figure, there are certain failure scenarios that may occur. By default, Kafka and HDFS are configured in high-availability mode, we will be focusing on Spark streaming fault tolerance.
Real-time stream processing systems must be operational 24/7, which requires them to recover from all kinds of failures in the system.
- Spark and its RDD abstraction is designed to seamlessly handle failures of any worker nodes in the cluster
- In Streaming, driver failure can be recovered with checkpointing application state.
- Write Ahead Logs (WAL) & Acknowledgements can ensure zero data loss
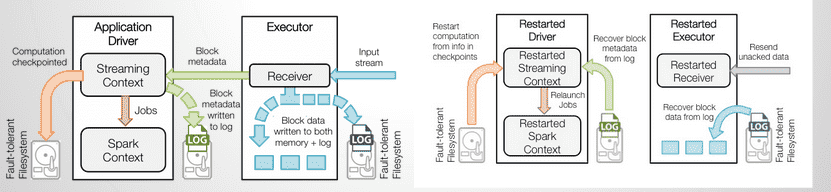
This image on right represents the processing of the received data in a fault tolerant system. When a Spark Streaming application starts (i.e., the driver starts), the associated StreamingContext (starting point of all streaming functionality) uses the SparkContext to launch Receivers as long running tasks, the receivers receive data from [source systems](/blogs/getting-data-into-spark-streaming/) like Kafka, flume etc These Receivers receive and buffers the streaming data into executors memory for processing.
In this fault tolerant file system the streaming data is checkpointed to another set of files periodically.
To ensure fault tolerance, when the failed driver restarts, the checkpointed data along with data from WAL is used to restart the driver, receivers and the contexts.
## Simple Fault-tolerant Streaming Infra
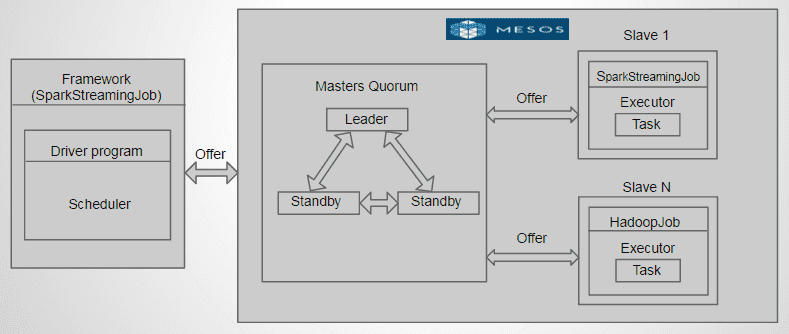
[Spark Streaming](/blogs/spark-streaming-production/) cluster and storage system are placed in Mesos cluster but the source systems like Kafka are out of the Mesos as the source can be from anywhere. So by having the Spark streaming in Mesos, even if a driver fails, there are standby drivers which takes care of the streaming process and thereby ensures fault tolerance.
**Goal:** Receive & process data at 1M events/sec
Understanding the bottlenecks:
- Network : 1Gbps
- # Cores/Slave : 4
- DISK IO : 100MB/S on SSD
Choosing the correct # Resources
- Since single slave can handle up to 100MB/S network and disk IO, a minimum of 6 slaves could take me to ~600MB/S
## Scaling the pipeline
One way to obtain high throughput is to launch more receivers on machines, and it will let you consume more data at once. There are other techniques like, setting up custom add-ons on top of [mesos](/blogs/apache-arrow-future-open-source-columnar-memory-analytics/) like Marathon to throw more machines (scale up and down the cluster automatically). Before scaling any [pipeline](/etl-and-data-pipeline/), one should always know their goals and the limitations on the available resources. So in a basic data-center all machines these days are equipped with around 4 cores of CPU, 1Gbit network card, and 100MB/S SSD Storage, if you say you want to process around 1Million events per second (600bytes each), then you will be needing like a minimum of 6 machines to get to that scale, since each of the machines can handle around 100MB/S in terms of network and DISK I/O.
## About the Author
Akhil was a Software Developer at Sigmoid focuses on distributed computing, big data analytics, scaling and optimising performance.
[lc_the_tags]
## Featured blogs
[lc_get_posts post_type="post"
posts_per_page="4" orderby="date" output_view="lc_get_posts_mycustom_view" output_number_of_columns="4"
output_wrapper_class="row" output_article_class="shadow" output_hide_elements="Excerpt"
output_excerpt_length="0" output_excerpt_text="Read More" output_heading_tag="span"
output_featured_image_format="thumbnail" output_featured_image_class="card-img-left" ]
## Share
[addtoany]
Subscribe to get latest insights
## Talk to our experts
Get the best ROI with Sigmoid’s services in data engineering and AI
## Suggested readings
[View all](/blogs/)

#### [Fault Tolerant Stream Processing with Spark Streaming](/blogs/fault-tolerant-stream-processing/)
[Read blog](/blogs/fault-tolerant-stream-processing/)

#### [Overview of Spark Architecture & Spark Streaming](/blogs/spark-streaming-internals/)
[Read blog](/blogs/spark-streaming-internals/)

#### [Getting Data into Spark Streaming](/blogs/getting-data-into-spark-streaming/)
[Read blog](/blogs/getting-data-into-spark-streaming/)
---
## Categories
- Data Management
---
## Navigation
- [WordPress.org](https://wordpress.org/)
- [Documentation](https://wordpress.org/documentation/)
- [Learn WordPress](https://learn.wordpress.org/)
- [Support](https://wordpress.org/support/forums/)
- [Feedback](https://wordpress.org/support/forum/requests-and-feedback)
- [Sigmoid](https://www.sigmoid.com/)
- [Community](https://community.wpmanageninja.com/portal/space/fluent-forms/home)
- [Docs](https://wpmanageninja.com/docs/fluent-form/)
- [Developer Docs](https://developers.fluentforms.com/)
- [Documentation](https://imagify.io/documentation/)
- [Rate Imagify on WordPress.org](https://wordpress.org/support/view/plugin-reviews/imagify?rate=5#postform)
- [Manage](admin.php?page=litespeed)
- [Settings](admin.php?page=litespeed-cache)
- [Image Optimization](admin.php?page=litespeed-img_optm)
- [Company](/about-sigmoid)
- [Newsroom](/newsroom)
- [Life at Sigmoid](/careers)
- [Takshashila](/takshashila)
- [Contact Us](/contact-us)
- [AI Strategy Blueprint your AI advantage](/enterprise-ai-strategy/)
- [Generative AI Drive innovation with Generative AI](/generative-ai/)
- [Responsible AI Build trust with ethical AI practices](/responsible-ai-in-enterprise/)
- [Agentic AI Reshape business with scalable agentic systems](/agentic-ai-solutions/)
- [AI Managed Services Ensure reliable AI performance](/ai-managed-services/)
- [Advanced Analytics Transform your business with data-driven insights](/advanced-data-analytics-solutions/)
- [Start Assessment](/agentic-ai-readiness-index/)
- [Data Strategy Strong data foundations for scalable AI](/data-analytics-strategy/)
- [Data Management Leverage data as a strategic asset](/ai-data-management-services/)
- [Data Ops Automate data for speed and quality](/data-devops/)
- [Data Engineering Deliver insights faster with scalable pipelines](/data-engineering/)
- [Cloud Transformation Modernize data to maximise efficiency](/cloud-migration/)
- [Download Whitepaper](/ebooks-whitepapers/building-data-products-in-a-data-mesh-to-drive-business-value/)
- [Data Modeling Structure data for better decisions](/data-modeling-services/)
- [Data Visualization Transform data into actionable stories](/data-visualization-service/)
- [BI Migration Enhance decision making with modern BI tools](/bi-migration/)
- [Data Observability Build trust with healthy, accurate data](/data-observability/)
- [Automated Insights Make smarter decisions with auto-generated insights](/automated-insights/)
- [Download Whitepaper](/ebooks-whitepapers/power-bi-hacks/)
- [CPG & Retail End-to-end analytics for planning, operations, and commercial excellence](/industries/cpg-analytics/)
- [Life Sciences Trusted intelligence across clinical, commercial, and operational workflows](/industries/life-sciences/)
- [Financial Services AI-powered analytics for risk, compliance and customer experience](/industries/banking-financial-analytics-services/)
- [Read case study](/case-studies/data-clean-room-enables-real-time-insights-to-improve-operational-efficiency/)
- [MediaIQ Advanced platform for in-flight marketing measurement](/accelerators/sigmoid-mediaiq-multi-touch-attribution-tool/)
- [CampaignIQ AI-driven platform for optimized campaign budget allocation](/accelerators/sigmoid-campaigniq/)
- [AssistBot GenAI email assistant that automates human-like responses](/accelerators/sigmoid-assistbot-for-ai-email-assistant/)
- [CreativeBot GenAI tool for personalized and brand-aligned creative design](/accelerators/sigmoid-creativebot/)
- [SocialBot GenAI platform to analyze digital conversations and trends](/accelerators/#marketing|socialbot)
- [DemandIQ Predict trends accurately and optimize inventory management](/accelerators/sigmoid-demandiq/)
- [NetworkIQ Track and optimize logistics operations in real-time to quickly address disruptions](/accelerators/sigmoid-networkiq/)
- [SupplyIQ End-to-end platform to optimize supply chain operations](/accelerators/sigmoid-supplyiq/)
- [ProcurementIQ Automated procurement operations for maximum savings, compliance and efficiency](/accelerators/sigmoid-procurementiq/)
- [RapidML Accelerated deployment for machine learning models](/accelerators/sigmoid-rapidml/)
- [DataGuard Comprehensive platform for proactive data quality management](/accelerators/data-quality-tool-sigmoid-dataguard/)
- [CloudPulse Cloud cost optimization platform with multi-cloud management](/accelerators/sigmoid-cloudpulse/)
- [RAPID GenAI foundation with built-in governance and cost clarity](/accelerators/sigmoid-rapid/)
- [AnalyticsBot GenAI based platform to streamline decision-making in analytics](/accelerators/sigmoid-analyticsbot/)
- [DataConnect Seamlessly ingest, integrate and harmonize data from diverse sources](/accelerators/sigmoid-dataconnect/)
- [Reconica AI-powered data harmonization and reconciliation engine](/accelerators/sigmoid-reconica/)
- [ConverseBot GenAI driven insights generation for automated insights from reports](/accelerators/#sales|conversebot)
- [iNRM Cross-lever revenue growth optimization platform](/accelerators/sigmoid-inrm/)
- [AssortmentIQ Optimize shelf layouts and assortment mix at scale with AI-based insights](/accelerators/sigmoid-assortmentiq/)
- [Read Whitepaper](/ebooks-whitepapers/building-agentic-ai-chatbots-for-business-process-transformation/)
- [Listen Podcast](/events/podcast/how-jack-in-the-box-is-redefining-personalization-and-supply-chain-with-ai/)
- [Blogs](/blogs/)
- [White Papers](/ebooks-whitepapers/)
- [Case Studies](/case-studies/)
- [Podcast](/events/podcast/#Podcasts)
- [Read Blog](/blogs/the-genai-adoption-triad-responsibility-ethics-and-explainability/)
- [ConverseBot](/accelerators/#sales|conversebot/)
## Tags
- Cloud Transformation
---
## Footer Links
- [Talk to our AI experts](/contact-us/)
- [AI Strategy](/enterprise-ai-strategy/)
- [Agentic AI](/agentic-ai-solutions/)
- [Generative AI](/generative-ai/)
- [AI Managed Services](/ai-managed-services/)
- [Responsible AI](/responsible-ai-in-enterprise/)
- [Advanced Analytics](/advanced-data-analytics-solutions/)
- [Data Strategy](/data-analytics-strategy//)
- [Data Engineering](/data-engineering/)
- [Data Management](/ai-data-management-services/)
- [Cloud Transformation](/cloud-transformation/)
- [Data Ops](/data-devops/)
- [Data Visualization](/data-visualization-service/)
- [Automated Insights](/automated-insights/)
- [BI Migration](/bi-migration/)
- [Data Modeling](/data-modeling-services/)
- [Data Observability](/data-observability/)
- [CPG & Retail](/industries/cpg-analytics/)
- [Financial Services](/industries/banking-financial-analytics-services/)
- [Life Sciences](/industries/life-sciences/)
- [Case Studies](/case-studies/)
- [Thought Leadership](/ebooks-whitepapers/)
- [Blogs](/blogs/)
- [Company](/about-sigmoid/)
- [Newsroom](/newsroom/)
- [Accelerators](/accelerators/)
- [Careers](/careers/)
- [Privacy Policy |](/privacy-policy/)
- [Cookie Policy](/cookie-policy/)