---
# Rehydrate bulk archived data in Azure storage using PowerShell Script
**URL:** https://www.sigmoid.com/blogs/rehydrate-bulk-archived-data-in-azure-storage-using-powershell-script/
Date: 2022-12-28
Author: Sigmoid
Post Type: post
Summary: Azure blob storage provides data to be stored in three different tiers for cost optimization related to different use cases. There are...Read More...
Categories: Cloud Transformation
Featured Image: https://www.sigmoid.com/wp-content/uploads/2022/12/powershell-script.jpg
---
Azure blob storage provides data to be stored in three different tiers for cost optimization related to different use cases. There are three types of tiers in azure which helps organize our data based on our frequency of use case: Hot, Cool and Archive. It is to be noted that the access tier option is only available for Block Blobs. However, hot and cool tier have data that is online and can be accessed frequently and infrequently respectively but the data that is moved to the archive tier is offline which means it can’t be read or modified. In order to read or download a blob that is in the archive tier, it needs to be moved to the online tier, hot or cool and this process is called rehydration. If we want to rehydrate some selected data we can simply try using the console but if there is bulk data that is in archive it is not possible to manually rehydrate it from the console.
In this blog, we will be discussing how to rehydrate the bulk archived data. It is to be noted that a Lifecycle Management Rule can move objects from hot to cool, from hot to archive, or from cool to archive **but not from Archive to cool or hot**. Hence, a Lifecycle Management Rule will not make this work.
**Prerequisite**: An Azure Virtual Machine with powershell and as module installed with your azure account logged in.
Now switch to powershell terminal using command pwsh and create a file using vim cool.ps1 and paste the following script below and save the file.
Suppose we have a container raw/ that has multiple folders which has archive data. We will use the following PowerShell Script:
- Replace rgName with the resource group value of your storage account. accountName will have the name of the storage account. containerName will have the name of the container under which you have archived blobs.
- Then we will get the context of the storage account within the resource group specified.
- Then we will be listing all the blobs in the container and if the access tier of those blobs is Archive it will be changed to cool by SetAccessTier operation.
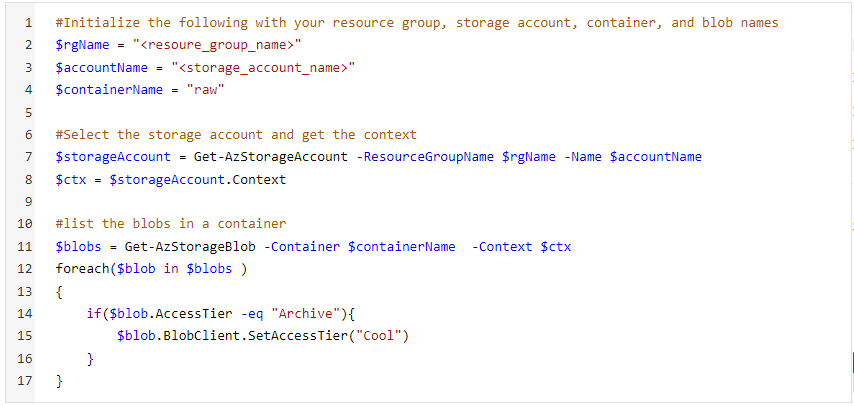
Rehydrating script in PowerShell
If you have multiple folders under the raw container, you can modify your script with something like the following:
Specify folders under your container in FolderName variables. A “*” would indicate that you are specifying all folders or blobs under that container or folder.
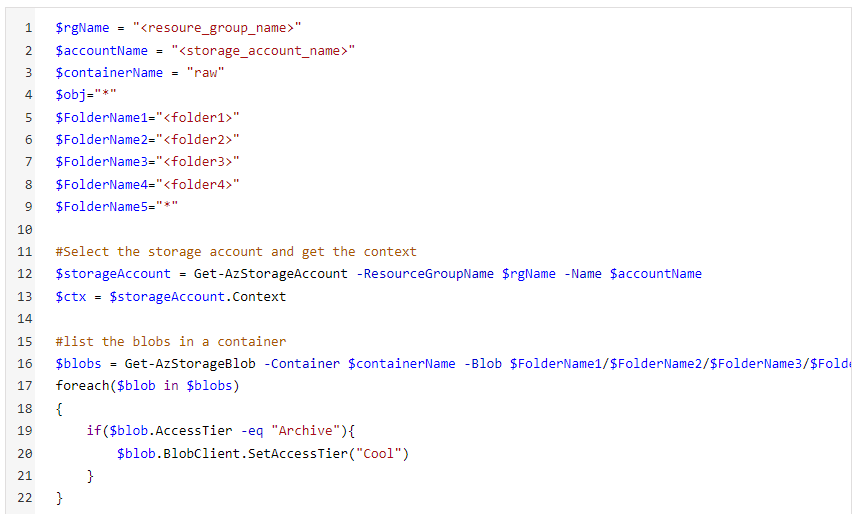
Rehydrating script with folder structure in PowerShell
- After saving the file, run a background job using the command:
- This will return the following output:

- You can get status of the job by running command: Get-Job
- To check output of Job use the following command:

You will get something like this:
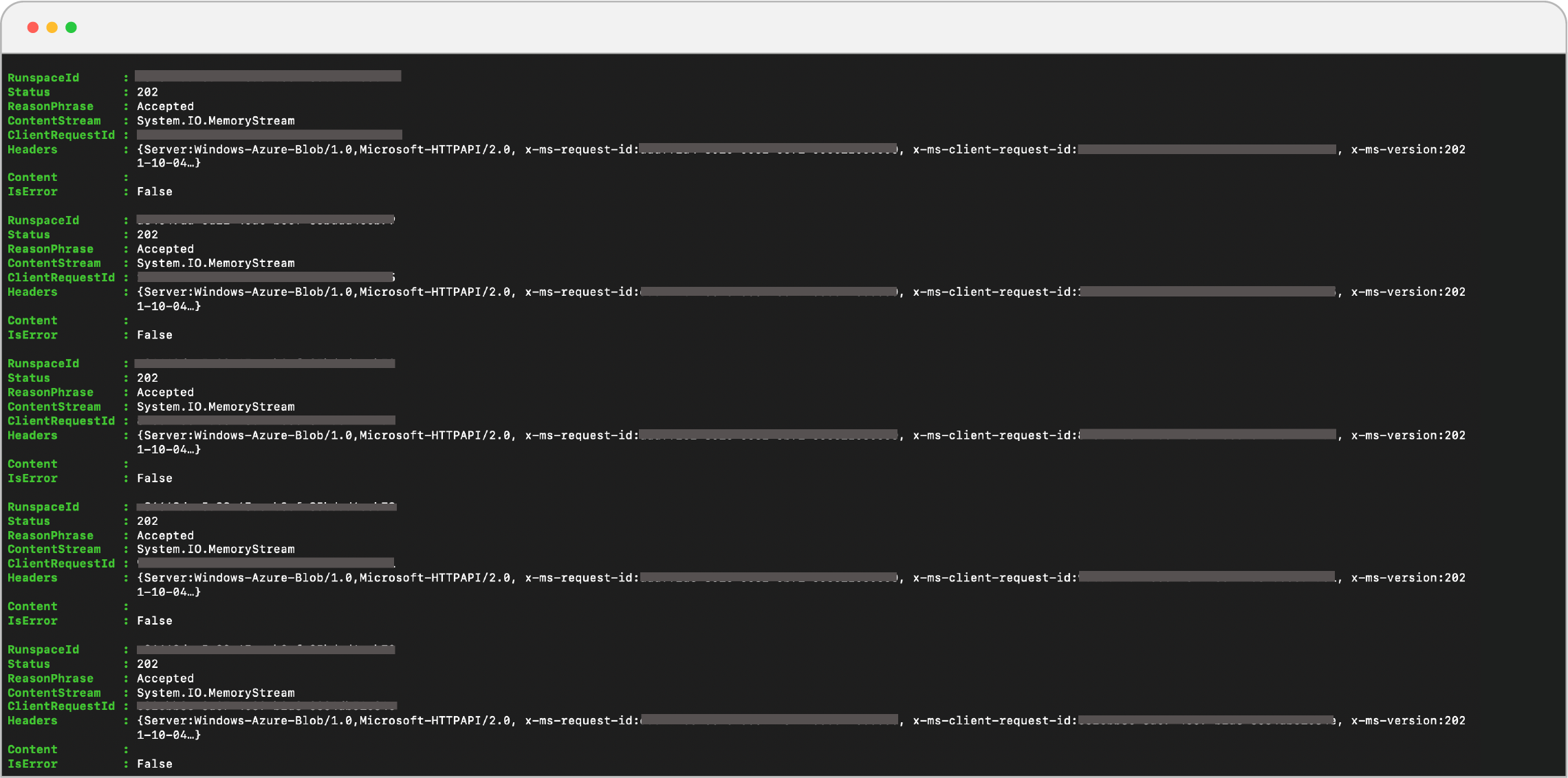
Output of Rehydrating script.
- Now go to the console, under archive status, you will notice that blobs are now rehydrating!!
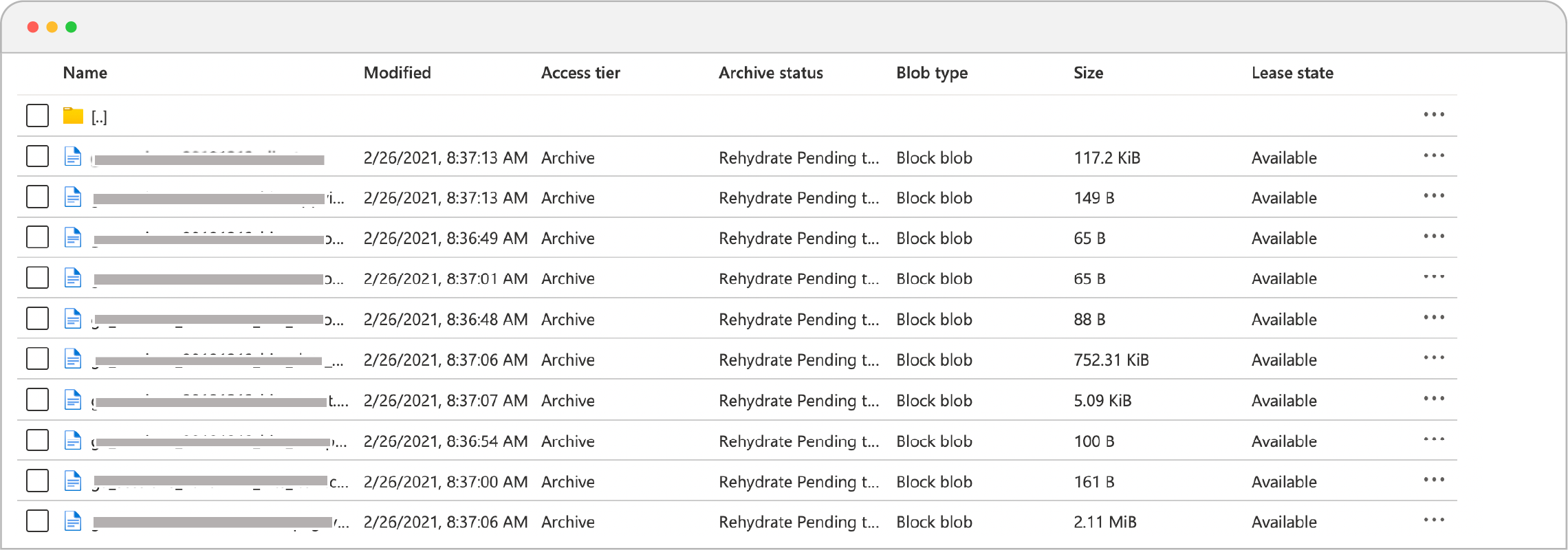
Rehydration Pending Status in Console.
**Note:** It can take several hours to rehydrate a blob from the Archive tier. Since we are not setting any priority then Standard priority is selected as default. A high priority rehydration is faster but it is costlier than standard-priority rehydration. It is recommended to select a high priority rehydration when data is needed to be restored in case of an emergency.
## About the Author
Prajna Bahuguna is a [DataOps Engineer](/data-devops/) at Sigmoid. She is a DevOps enthusiast who is always curious to learn about innovative solutions using Cloud, Python and DevOps practices. In her leisure time she enjoys doing artwork and mobile photography.
## Featured blogs
[lc_get_posts post_type="post"
posts_per_page="4" orderby="date" output_view="lc_get_posts_mycustom_view" output_number_of_columns="4"
output_wrapper_class="row" output_article_class="shadow" output_hide_elements="Excerpt"
output_excerpt_length="0" output_excerpt_text="Read More" output_heading_tag="span"
output_featured_image_format="thumbnail" output_featured_image_class="card-img-left" ]
## Share
[addtoany]
Subscribe to get latest insights
## Talk to our experts
Get the best ROI with Sigmoid’s services in data engineering and AI
---
## Categories
- Cloud Transformation
---
## Navigation
- [Company](/about-sigmoid)
- [Newsroom](/newsroom)
- [Life at Sigmoid](/careers)
- [Takshashila](/takshashila)
- [Contact Us](/contact-us)
- [AI Strategy Blueprint your AI advantage](/enterprise-ai-strategy/)
- [Generative AI Drive innovation with Generative AI](/generative-ai/)
- [Responsible AI Build trust with ethical AI practices](/responsible-ai-in-enterprise/)
- [Agentic AI Reshape business with scalable agentic systems](/agentic-ai-solutions/)
- [AI Managed Services Ensure reliable AI performance](/ai-managed-services/)
- [Advanced Analytics Transform your business with data-driven insights](/advanced-data-analytics-solutions/)
- [Start Assessment](/agentic-ai-readiness-index/)
- [Data Strategy Strong data foundations for scalable AI](/data-analytics-strategy/)
- [Data Management Leverage data as a strategic asset](/ai-data-management-services/)
- [Data Ops Automate data for speed and quality](/data-devops/)
- [Data Engineering Deliver insights faster with scalable pipelines](/data-engineering/)
- [Cloud Transformation Modernize data to maximise efficiency](/cloud-migration/)
- [Download Whitepaper](/ebooks-whitepapers/building-data-products-in-a-data-mesh-to-drive-business-value/)
- [Data Modeling Structure data for better decisions](/data-modeling-services/)
- [Data Visualization Transform data into actionable stories](/data-visualization-service/)
- [BI Migration Enhance decision making with modern BI tools](/bi-migration/)
- [Data Observability Build trust with healthy, accurate data](/data-observability/)
- [Automated Insights Make smarter decisions with auto-generated insights](/automated-insights/)
- [Download Whitepaper](/ebooks-whitepapers/power-bi-hacks/)
- [CPG & Retail End-to-end analytics for planning, operations, and commercial excellence](/industries/cpg-analytics/)
- [Life Sciences Trusted intelligence across clinical, commercial, and operational workflows](/industries/life-sciences/)
- [Financial Services AI-powered analytics for risk, compliance and customer experience](/industries/banking-financial-analytics-services/)
- [Read case study](/case-studies/data-clean-room-enables-real-time-insights-to-improve-operational-efficiency/)
- [MediaIQ Advanced platform for in-flight marketing measurement](/accelerators/sigmoid-mediaiq-multi-touch-attribution-tool/)
- [CampaignIQ AI-driven platform for optimized campaign budget allocation](/accelerators/sigmoid-campaigniq/)
- [AssistBot GenAI email assistant that automates human-like responses](/accelerators/sigmoid-assistbot-for-ai-email-assistant/)
- [CreativeBot GenAI tool for personalized and brand-aligned creative design](/accelerators/sigmoid-creativebot/)
- [SocialBot GenAI platform to analyze digital conversations and trends](/accelerators/#marketing|socialbot)
- [DemandIQ Predict trends accurately and optimize inventory management](/accelerators/sigmoid-demandiq/)
- [NetworkIQ Track and optimize logistics operations in real-time to quickly address disruptions](/accelerators/sigmoid-networkiq/)
- [SupplyIQ End-to-end platform to optimize supply chain operations](/accelerators/sigmoid-supplyiq/)
- [ProcurementIQ Automated procurement operations for maximum savings, compliance and efficiency](/accelerators/sigmoid-procurementiq/)
- [RapidML Accelerated deployment for machine learning models](/accelerators/sigmoid-rapidml/)
- [DataGuard Comprehensive platform for proactive data quality management](/accelerators/data-quality-tool-sigmoid-dataguard/)
- [CloudPulse Cloud cost optimization platform with multi-cloud management](/accelerators/sigmoid-cloudpulse/)
- [RAPID GenAI foundation with built-in governance and cost clarity](/accelerators/sigmoid-rapid/)
- [AnalyticsBot GenAI based platform to streamline decision-making in analytics](/accelerators/sigmoid-analyticsbot/)
- [DataConnect Seamlessly ingest, integrate and harmonize data from diverse sources](/accelerators/sigmoid-dataconnect/)
- [Reconica AI-powered data harmonization and reconciliation engine](/accelerators/sigmoid-reconica/)
- [ConverseBot GenAI driven insights generation for automated insights from reports](/accelerators/#sales|conversebot)
- [iNRM Cross-lever revenue growth optimization platform](/accelerators/sigmoid-inrm/)
- [AssortmentIQ Optimize shelf layouts and assortment mix at scale with AI-based insights](/accelerators/sigmoid-assortmentiq/)
- [Read Whitepaper](/ebooks-whitepapers/building-agentic-ai-chatbots-for-business-process-transformation/)
- [Listen Podcast](/events/podcast/how-jack-in-the-box-is-redefining-personalization-and-supply-chain-with-ai/)
- [Blogs](/blogs/)
- [White Papers](/ebooks-whitepapers/)
- [Case Studies](/case-studies/)
- [Podcast](/events/podcast/#Podcasts)
- [Read Blog](/blogs/the-genai-adoption-triad-responsibility-ethics-and-explainability/)
- [ConverseBot](/accelerators/#sales|conversebot/)
---
## Footer Links
- [Talk to our AI experts](/contact-us/)
- [AI Strategy](/enterprise-ai-strategy/)
- [Agentic AI](/agentic-ai-solutions/)
- [Generative AI](/generative-ai/)
- [AI Managed Services](/ai-managed-services/)
- [Responsible AI](/responsible-ai-in-enterprise/)
- [Advanced Analytics](/advanced-data-analytics-solutions/)
- [Data Strategy](/data-analytics-strategy//)
- [Data Engineering](/data-engineering/)
- [Data Management](/ai-data-management-services/)
- [Cloud Transformation](/cloud-transformation/)
- [Data Ops](/data-devops/)
- [Data Visualization](/data-visualization-service/)
- [Automated Insights](/automated-insights/)
- [BI Migration](/bi-migration/)
- [Data Modeling](/data-modeling-services/)
- [Data Observability](/data-observability/)
- [CPG & Retail](/industries/cpg-analytics/)
- [Financial Services](/industries/banking-financial-analytics-services/)
- [Life Sciences](/industries/life-sciences/)
- [Case Studies](/case-studies/)
- [Thought Leadership](/ebooks-whitepapers/)
- [Blogs](/blogs/)
- [Company](/about-sigmoid/)
- [Newsroom](/newsroom/)
- [Accelerators](/accelerators/)
- [Careers](/careers/)
- [Privacy Policy |](/privacy-policy/)
- [Cookie Policy](/cookie-policy/)