---
# How Hadoop redefined Big Data Processing
**URL:** https://www.sigmoid.com/how-hadoop-handles-data-processing/
Date: 2024-04-16
Author: Sigmoid
Post Type: page
Summary: How Hadoop handles Data Processing Chapter- 1 Introduction Chapter- 2 HDFS Chapter- 3 MapReduce with Hadoop Chapter- 4 Hadoop 2.0 Chapter- 5...Read More...
---
# How Hadoop handles Data Processing
[Chapter- 1 Introduction](#chapter-1)
[Chapter- 2 HDFS](#chapter-2)
[Chapter- 3 MapReduce with Hadoop](#chapter-3)
[Chapter- 4 Hadoop 2.0](#chapter-4)
[Chapter- 5 Conclusion](#chapter-5)
[Chapter- 6 About the Author](#chapter-6)
## Introduction
In 2006, Yahoo! embarked on a groundbreaking endeavor, birthing their own rendition of a distributed processing framework known as Hadoop that was meticulously crafted entirely in JAVA. The genesis of its name, "Hadoop," offers a whimsical insight into its origins, stemming from the toy elephant of Doug Cutting's son, one of the creators of Hadoop.

The two foundational components of Hadoop - HDFS (Hadoop Distributed File System) and MapReduce - ushered in a new era of data processing prowess. As we delve into HDFS & MapReduce, we uncover a paradigm shift in architecture that is different from the structures observed in Google’s take on file storage and processing in 2003. Let’s embark on a journey through Hadoop, unraveling how it takes a new approach to data retrieval and processing.
## HDFS
In HDFS, the architecture features Name Nodes, Secondary Name Nodes, and Data Nodes instead of the Master, Shadow Master, and Chunk Server as in GFS. The data retrieval process remains consistent across GFS and HDFS. Initially, the client connects to the Name Node, requesting data or a file. The Name Node, equipped with a metadata table detailing file locations on Data Nodes, responds to the client's inquiry. Subsequently, the client accesses the data from the respective Data Node.
### Did you know ?
#### Difference in nomenclature between
GFS
HDFS
Master
Name node
Shadow master
2ndary name node
Chunk server
Data node
Chunk
Block
C++
Java
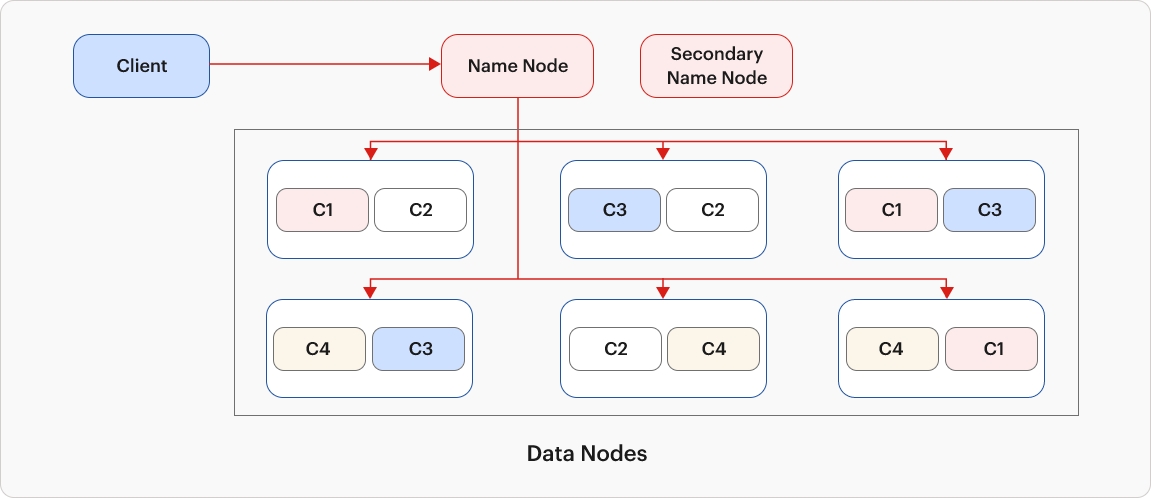
Additionally, HDFS operates with a default replication factor of 3, employing blocks of 128 MB each. Periodically, the Name Node actively monitors the vitality of Data Nodes through regular heartbeat checks.
## MapReduce with Hadoop
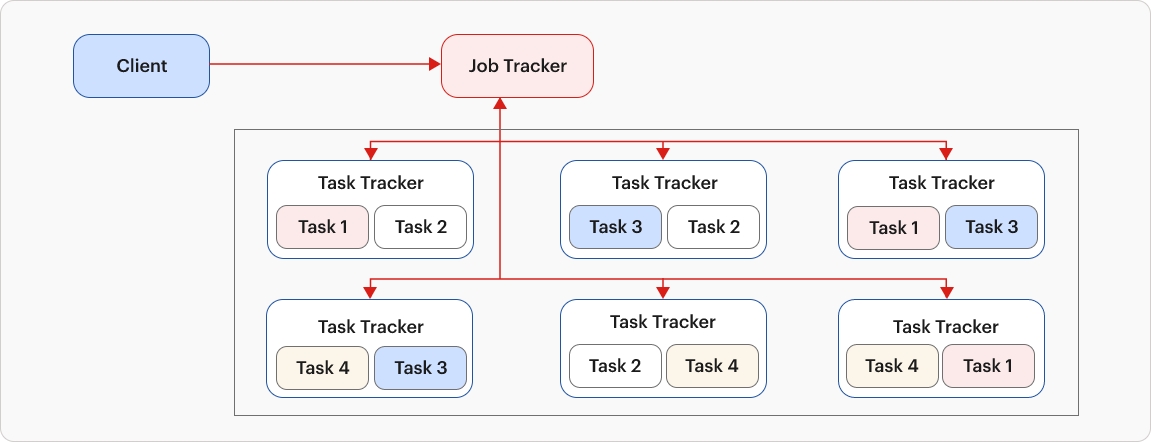
Hadoop's implementation of MapReduce is significantly different from Google's MapReduce. Hadoop utilizes a Job Tracker within the NameNode to oversee ongoing tasks and coordinate the scheduling of new tasks. Each DataNode hosts a Task Tracker, responsible for transmitting the status of the currently executing task to the Job Tracker. Moreover, processing occurs within Java Virtual Machines (JVMs) as a runtime environment. This architecture is depicted below.
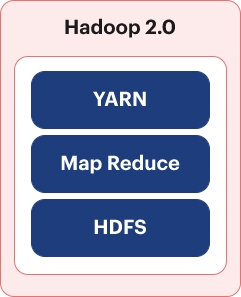
## Hadoop 2.0
Introduced in 2015, Hadoop 2.0 marked a significant milestone with the integration of YARN (Yet Another Resource Negotiator) to tackle the strain on the JobTracker in Hadoop 1.0. The Job Tracker bore the brunt of scheduling and monitoring tasks, while the TaskTracker simply oversaw the execution of mappers and reducers locally and reported back to the JobTracker. As cluster sizes expanded beyond 4,000 DataNodes, the JobTracker began to encounter bottlenecks.
YARN solves this issue with three key components: the Resource Manager, Node Manager, and Application Master. In Hadoop 2.0, monitoring responsibilities were removed from the JobTracker, leaving it solely responsible for scheduling tasks. Consequently, the JobTracker was rebranded as the Resource Manager, while the TaskTracker was renamed the Node Manager.
When a client submits a request to the Resource Manager, it initiates the creation of a container in one of the Node Managers. Within this container, the Application Master is created.
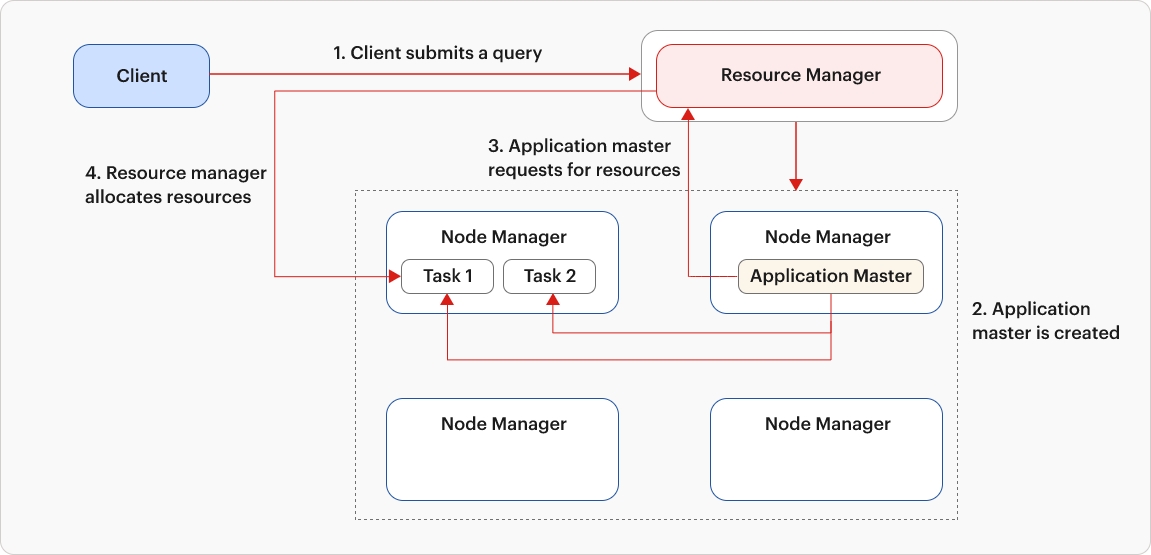
Subsequently, the Application Master communicates with the Resource Manager to request the necessary resources for executing the tasks. Upon allocation of the container by the Resource Manager, the Container ID and Node Manager information are conveyed to the Application Master. The Application Master then proceeds to the designated Node Manager to execute the tasks within the allocated containers. Throughout this process, the Application Master assumes responsibility for monitoring the tasks until their completion. In the event of task failure, it is the duty of the Application Master to facilitate their re-execution.
## Conclusion
The narrative of Hadoop transcends mere technological innovation; it encapsulates a saga of ingenuity and adaptation. From its humble beginnings in 2006 to the monumental strides witnessed in Hadoop 2.0, this distributed processing framework has evolved to surmount challenges and redefine data processing efficiency. As we bid adieu to the era of JobTrackers and embrace the dawn of Resource Managers and Node Managers, one thing remains abundantly clear: the legacy of Hadoop persists as a testament to ingenuity. So, let us continue our journey of exploration and innovation, as we navigate the ever-expanding horizons of data-processing with our blog on Apache Spark, [Apache 'Spark'ing innovation in Data Processing optimization](/apache-sparking-innovation-in-data-processing-optimization/)!
## About the Author
Ashish Chouhan, an Associate Software Development Engineer at Sigmoid, is a budding data engineer in the industry. His experience includes distributed computing systems such as Apache Spark, cloud-based platforms like Azure and AWS, and various data warehousing solutions. He is passionate about architecting and refining data pipelines, and shows great interest to apply his knowledge to projects that require robust data engineering solutions.
---
## Navigation
- [Company](/about-sigmoid)
- [Newsroom](/newsroom)
- [Life at Sigmoid](/careers)
- [Takshashila](/takshashila)
- [Contact Us](/contact-us)
- [AI Strategy Blueprint your AI advantage](/enterprise-ai-strategy/)
- [Generative AI Drive innovation with Generative AI](/generative-ai/)
- [Responsible AI Build trust with ethical AI practices](/responsible-ai-in-enterprise/)
- [Agentic AI Reshape business with scalable agentic systems](/agentic-ai-solutions/)
- [AI Managed Services Ensure reliable AI performance](/ai-managed-services/)
- [Advanced Analytics Transform your business with data-driven insights](/advanced-data-analytics-solutions/)
- [Start Assessment](/agentic-ai-readiness-index/)
- [Data Strategy Strong data foundations for scalable AI](/data-analytics-strategy/)
- [Data Management Leverage data as a strategic asset](/ai-data-management-services/)
- [Data Ops Automate data for speed and quality](/data-devops/)
- [Data Engineering Deliver insights faster with scalable pipelines](/data-engineering/)
- [Cloud Transformation Modernize data to maximise efficiency](/cloud-migration/)
- [Download Whitepaper](/ebooks-whitepapers/building-data-products-in-a-data-mesh-to-drive-business-value/)
- [Data Modeling Structure data for better decisions](/data-modeling-services/)
- [Data Visualization Transform data into actionable stories](/data-visualization-service/)
- [BI Migration Enhance decision making with modern BI tools](/bi-migration/)
- [Data Observability Build trust with healthy, accurate data](/data-observability/)
- [Automated Insights Make smarter decisions with auto-generated insights](/automated-insights/)
- [Download Whitepaper](/ebooks-whitepapers/power-bi-hacks/)
- [CPG & Retail End-to-end analytics for planning, operations, and commercial excellence](/industries/cpg-analytics/)
- [Life Sciences Trusted intelligence across clinical, commercial, and operational workflows](/industries/life-sciences/)
- [Financial Services AI-powered analytics for risk, compliance and customer experience](/industries/banking-financial-analytics-services/)
- [Read case study](/case-studies/data-clean-room-enables-real-time-insights-to-improve-operational-efficiency/)
- [MediaIQ Advanced platform for in-flight marketing measurement](/accelerators/sigmoid-mediaiq-multi-touch-attribution-tool/)
- [CampaignIQ AI-driven platform for optimized campaign budget allocation](/accelerators/sigmoid-campaigniq/)
- [AssistBot GenAI email assistant that automates human-like responses](/accelerators/sigmoid-assistbot-for-ai-email-assistant/)
- [CreativeBot GenAI tool for personalized and brand-aligned creative design](/accelerators/sigmoid-creativebot/)
- [SocialBot GenAI platform to analyze digital conversations and trends](/accelerators/#marketing|socialbot)
- [DemandIQ Predict trends accurately and optimize inventory management](/accelerators/sigmoid-demandiq/)
- [NetworkIQ Track and optimize logistics operations in real-time to quickly address disruptions](/accelerators/sigmoid-networkiq/)
- [SupplyIQ End-to-end platform to optimize supply chain operations](/accelerators/sigmoid-supplyiq/)
- [ProcurementIQ Automated procurement operations for maximum savings, compliance and efficiency](/accelerators/sigmoid-procurementiq/)
- [RapidML Accelerated deployment for machine learning models](/accelerators/sigmoid-rapidml/)
- [DataGuard Comprehensive platform for proactive data quality management](/accelerators/data-quality-tool-sigmoid-dataguard/)
- [CloudPulse Cloud cost optimization platform with multi-cloud management](/accelerators/sigmoid-cloudpulse/)
- [RAPID GenAI foundation with built-in governance and cost clarity](/accelerators/sigmoid-rapid/)
- [AnalyticsBot GenAI based platform to streamline decision-making in analytics](/accelerators/sigmoid-analyticsbot/)
- [DataConnect Seamlessly ingest, integrate and harmonize data from diverse sources](/accelerators/sigmoid-dataconnect/)
- [Reconica AI-powered data harmonization and reconciliation engine](/accelerators/sigmoid-reconica/)
- [ConverseBot GenAI driven insights generation for automated insights from reports](/accelerators/#sales|conversebot)
- [iNRM Cross-lever revenue growth optimization platform](/accelerators/sigmoid-inrm/)
- [AssortmentIQ Optimize shelf layouts and assortment mix at scale with AI-based insights](/accelerators/sigmoid-assortmentiq/)
- [Read Whitepaper](/ebooks-whitepapers/building-agentic-ai-chatbots-for-business-process-transformation/)
- [Listen Podcast](/events/podcast/how-jack-in-the-box-is-redefining-personalization-and-supply-chain-with-ai/)
- [Blogs](/blogs/)
- [White Papers](/ebooks-whitepapers/)
- [Case Studies](/case-studies/)
- [Podcast](/events/podcast/#Podcasts)
- [Read Blog](/blogs/the-genai-adoption-triad-responsibility-ethics-and-explainability/)
- [ConverseBot](/accelerators/#sales|conversebot/)
---
## Footer Links
- [Talk to our AI experts](/contact-us/)
- [AI Strategy](/enterprise-ai-strategy/)
- [Agentic AI](/agentic-ai-solutions/)
- [Generative AI](/generative-ai/)
- [AI Managed Services](/ai-managed-services/)
- [Responsible AI](/responsible-ai-in-enterprise/)
- [Advanced Analytics](/advanced-data-analytics-solutions/)
- [Data Strategy](/data-analytics-strategy//)
- [Data Engineering](/data-engineering/)
- [Data Management](/ai-data-management-services/)
- [Cloud Transformation](/cloud-transformation/)
- [Data Ops](/data-devops/)
- [Data Visualization](/data-visualization-service/)
- [Automated Insights](/automated-insights/)
- [BI Migration](/bi-migration/)
- [Data Modeling](/data-modeling-services/)
- [Data Observability](/data-observability/)
- [CPG & Retail](/industries/cpg-analytics/)
- [Financial Services](/industries/banking-financial-analytics-services/)
- [Life Sciences](/industries/life-sciences/)
- [Case Studies](/case-studies/)
- [Thought Leadership](/ebooks-whitepapers/)
- [Blogs](/blogs/)
- [Company](/about-sigmoid/)
- [Newsroom](/newsroom/)
- [Accelerators](/accelerators/)
- [Careers](/careers/)
- [Privacy Policy |](/privacy-policy/)
- [Cookie Policy](/cookie-policy/)