Build a winning data pipeline architecture on the cloud for CPG
Reading Time: 6 minutes

The CPG industry has historically had little exposure to consumer data. But, with the surge in digitization and a shift in customer buying behavior to online and direct-to-consumer sales, CPGs are generating customer and external data like never before. According to research, retail websites recorded 22 billion visits in June 2020 as compared to 16.07 billion global visits in January 2020.
This increased data traction by CPGs calls for managing data at scale and adopting new approaches for data management. While this might seem like an ideal scenario, preparing data and building a robust data pipeline architecture is a major challenge for CPGs.
Data Challenges for CPG
One of the first challenges that CPGs face is gathering, orchestrating, and managing customer data, which has traditionally been in the hands of retailers and distributors. According to a CGT study, most retailers do not share these datasets, including promotional, online sales, or pricing data.
Some of the data that CPGs have access to are:
- First-party data which are internal to the company such as ERPs and CRMs
- Second-party data from retailers and eCommerce companies
- Third-party data from aggregators like Nielsen, DunnHumby, ScanTrack, and Media spend data
- Open-source data such as weather data, environment data, COVID data, and more.
Despite petabytes of data flowing from several internal and external data sources, data ingestion, accessibility, and analyzing enterprise data becomes one of the most frustrating challenges for CPGs. With multiple data management systems across the CPG value chain such as supply chain and manufacturing, these data sources exist in silos.
Moreover, real-time access to insights is especially crucial for CPGs who have the huge potential to use it for product development and making optimized marketing decisions. Various stakeholders must have access to data in varying granularities.
Some of the other challenges are data security, data integrity, and manual maintenance. These limitations translate into long development cycles and bottlenecks to process data and extract meaningful information from it.
CPGs need to build a robust and scalable data infrastructure that integrates multiple data sources through agile cloud data warehousing practices that can be used for further analysis and empower decision-makers with real-time informed decision making support. Building data pipelines is a crucial first step in the process. With access to accurate and prepared datasets, data teams can build accurate models reaping huge benefits for the companies.
Data Pipelines
The typical requirement is to create an end-to-end solution to ingest high volumes of data at high speed, enabling data integration for fast and reliable processing and building scalable data pipelines with shorter querying for real-time insights. The steps are broken down in detail below.
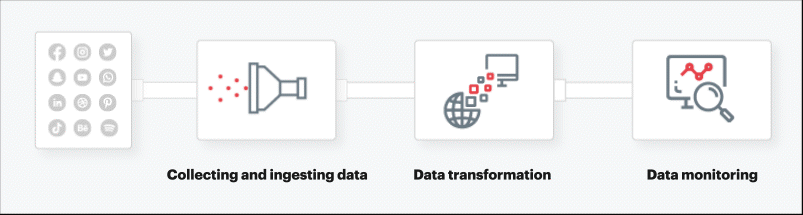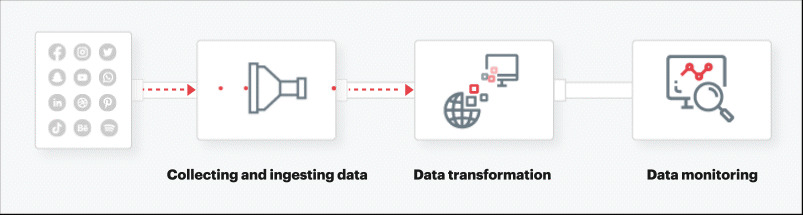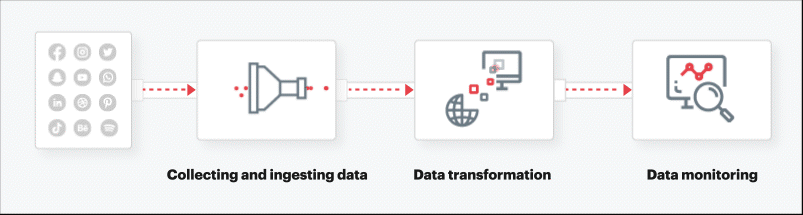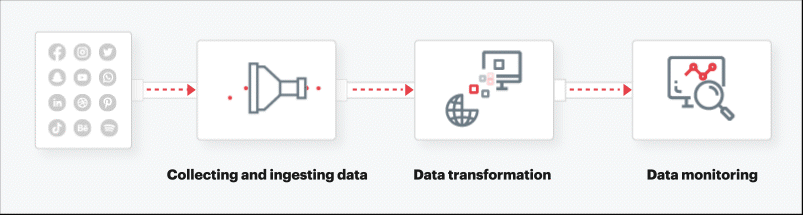
- Collecting and ingesting data
The first step in creating data pipelines for CPG is to collate and analyze data coming from every touchpoint for real-time processing. The data is ingested from the sources mentioned above. An extraction possesses reads from each data source using third-party API integration, internal database, and web scraping to perform multiple extractions.
While the data can be ingested in batches or in real-time, CPGs must prepare data for real-time processing to capitalize on the in-flow of continuous streaming data such as social media or from marketing campaigns such as views, clicks, and shares. While processing streaming data to extract insights, one common challenge that developers face is to handle duplicate data that could be in the form of source-generated duplicates, publisher-generated duplicates and more. Tools such as Apache Spark provide a mechanism to avoid duplicates and recover data after failures. Duplicates in-stream can also be removed with pass-through deduplication.
- Data transformation
Once the data is extracted from source systems, its structure or format may need to be adjusted through data transformation such as by database joins, unioning, etc. ELT allows transformations to take place before the data is loaded into the cloud data warehouse or data lakes. ELT process also works hand-in-hand with data lakes to accept both structured and unstructured data, and ingest an ever-expanding pool of raw data immediately, as it becomes available.
- Data monitoring
Data pipelines are complex systems consisting of software, hardware, and network components, and are subject to failures. To keep the pipeline operational developers must monitor it on a regular basis and resolve any problems that arise. Several other factors determine the success of a data pipeline — rate or throughput, fault-tolerance, latency, and idempotency to name a few.
- Rate, or throughput, is the amount of data that a pipeline can process within a set amount of time. With a continuous stream of data that CPGs are dealing with, developing pipelines with high throughput is a given.
- Fault-tolerant data pipelines are built to anticipate and mitigate the fundamental and most common faults such as downstream failures or network failure. Faults in the data pipeline can jeopardize critical CPG analytics initiatives. Keeping this in mind, CPG companies need to create distributed data pipeline architectures that offer immediate failover and alert data teams in case there is an application failure, node failure, or fault in some of the other services.
- Latency refers to the time needed for a single unit of data to travel through the pipeline. For effective data pipelines, low latency can be a deterrent in terms of both price and processing resources.
- Idempotency or re-runnability pertains to the re-application of a function, in this case, re-execution of a pipeline. Data pipeline may be needed to be retriggered in a variety of scenarios such as faulty source data, bugs in the transformation logic, or adding a new dimension to the data. Idempotence is important to maintain the operability of the pipeline.
Finally, the data can be fed into analytics tools for processing where it generates analysis, business intelligence, and real-time dashboard visualization that various stakeholders can leverage to optimize marketing campaigns or analyze trends.
Setting a layer of data governance ensures that companies have control over data integrity, data availability, security, and visibility while complying with regulatory compliance standards such as GDPR & COPPA.
Data Mesh for Modern CPG Data Architecture
As the data use case grows, there may be a need for a distributed framework to support domain-specific data consumers with each domain handling its own data pipelines. Data mesh is a type of data platform architecture that provides companies with more appetite for data to be ingested. It helps deal with the increased complexity of data pipelines, improve data observability and discoverability layer to understand the health of data assets across the life cycle.
A data mesh architecture is a modern approach that allows CPG businesses to manage the growing data at scale by providing flexibility, greater data experimentation, and innovation. A data mesh is designed to natively support collaborations between CPGs and their partners where internal and external data producers/consumers can freely exchange data.
Conclusion
Changing customer preferences and increased competition has called for consumer brands to invest in data modernization and analytics to align their strategies and business models with the evolving consumer trends and requirements. Creating a robust and modern data pipeline architecture will lay a foundation for the strategic plan that lies ahead for building a customer-centric strategy for CPGs in the coming years.
About the Author
Nandam is Engineering Manager at Sigmoid with a decade of experience working in Gaming and Big Data technologies. He is passionate about solving business problems across CPG, Retail, QSR and Metals and Mining domains through his expertise using open source and different cloud technologies.
Featured blogs







Featured blogs