A guide to cloud data warehouse
- Chapter- 1 Introduction
- Chapter- 2 Introduction to cloud data warehouse
- Chapter- 3 CDW vs Data lake
- Chapter- 4 Advantages of cloud adoption
- Chapter- 5 Steps for successful cloud adoption
- Chapter- 6 Organizational capabilities for cloud data warehouses
- Chapter- 7 Top ELT/ETL tools for cloud data migration
- Chapter- 8 Building a cloud data warehouse
- Chapter- 9 Data migration strategy and planning
- Chapter- 10 Framework for optimizing cloud data warehouses
1. Introduction
Modern day businesses require faster access to consumable data for decision making, actioning upon real-time insights and driving successful analytics initiatives. As the expectations for on-demand data exploded, data warehousing teams increasingly realized the need to upscale the traditional warehouses, thus shifting to cloud storage. Cloud data migration and warehousing has become critical for businesses owing to its scalability and cost-effectiveness. There is an evident sign of more businesses investing in the cloud data warehouses, such that the market is expected to grow by USD 10.42 billion in value by 2026.
Empowering business users with real-time decision support systems relies on a high-performance and adaptable data infrastructure which seamlessly integrates with multiple data sources. Cloud data warehouses (CDW) offer a host of benefits including higher elasticity, enhanced governance, better resilience, and end-to-end data management at much lower operating costs than on-premise infrastructure.
Adopting a cloud migration strategy and transitioning to a cloud data warehouse calls for a methodical, well-planned approach that mitigates implementation risks and enables businesses to derive greater value and achieve higher ROI from data. The whitepaper discusses how companies can embark on a cloud-first data strategy to store and manage data in the cloud.
2. Introduction to cloud data warehouse
Today businesses are harnessing large streams of data, faster than ever before. Thanks to the proliferation of advanced data analytics and business intelligence tools, companies now have the means to quantify the impact of every campaign they run, identify process improvement opportunities, nurture customer engagement across their purchase journey, drive loyalty and ensure exceptional customer experience.
The abundance of data pipelines consisting of performance, customer, competitive and process-oriented data has made it easier for companies to drive actionable decision making. However, this data boom also poses a serious challenge for companies. With time the size of their data sets can quickly outgrow the capability of their native systems to store and process the data.
Traditionally data warehouses served as a preferred architecture for companies to collate, organize and access enterprise data hosted on servers on-premise. But, finite storage capacity, cost of ownership, higher latency and the need for constant maintenance didn’t make conventional data warehouse solutions a sustainable data storage option. Hence, the next logical data storage innovation happened in the cloud.
With time as business expectations for on-demand data exploded, data warehousing teams increasingly shifted their data storage efforts to the cloud. The need to seamlessly harvest data from diverse sources and presenting it in an easily consumable format to decision-makers has made adopting cloud migration strategy indispensable today.
For the cloud data migration process to be successful, companies need to ensure that they have the right data integration and data management capabilities.
What is a cloud data warehouse?
A cloud data warehouse serves as a foundation of a structured analytics infrastructure. It is essentially a central repository of data that can be analyzed for actionable decision-making. In order to recalibrate legacy on-premise data warehouses and make them fit for the advanced analytics ecosystem, companies need to think about transitioning from on-premise to cloud data management practices.
3. CDW vs Data lake
While both data lakes and data warehouses are commonly used to store large amounts of data, the words are not synonymous. A data lake is a large pool of unstructured data which is not well defined. On the other hand, a data warehouse is a repository of filtered data that has already been processed for a particular purpose. The table below illustrates some of the key differences to keep in mind.
| Parameters | Data warehouses | Data lakes |
|---|---|---|
|
Structure of data |
Processed – Requires comparatively lesser storage |
Raw – Often requires larger storage capacity |
|
Purpose |
Being utilized – All data is stored with specific utilization in mind |
Undetermined – Raw data flows with either a purpose in mind or simply for storage |
|
Users |
Business professionals – Most employees can read and use the processed data to be used for charts, tables, spreadsheets, and more |
Data scientists/ Experts – Needs specialized tools to translate raw data for specific business usage |
|
Accessibility |
Data is well structured but with limitations that make data manipulation cumbersome and costly |
Accessing and changing data is easier and faster due to a lack of structure and fewer limitations |
4. Advantages of cloud adoption
A well-thought out cloud data warehouse strategy can help companies reap multiple benefits such as:
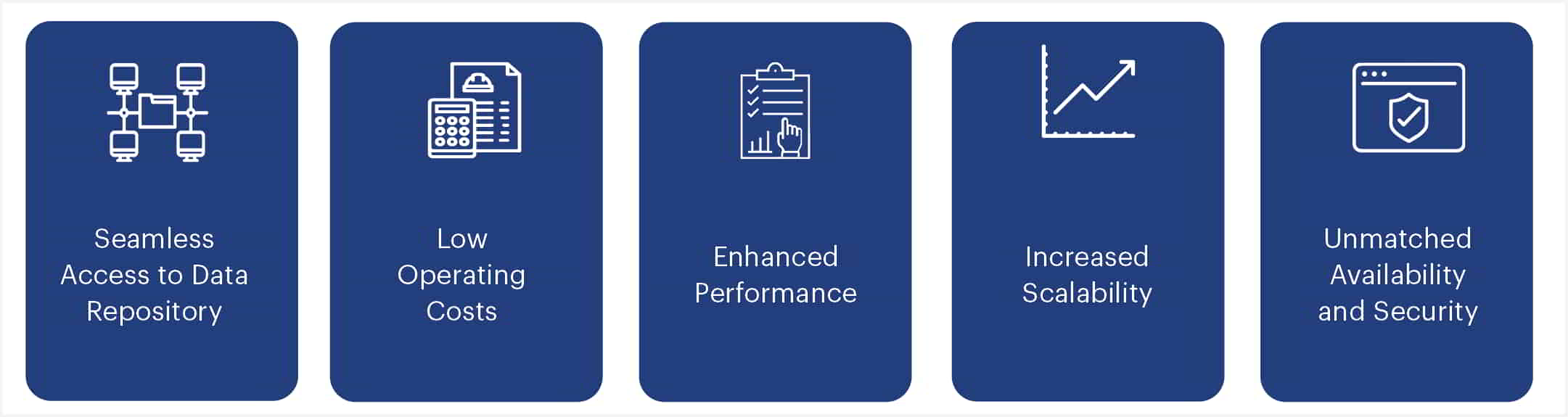
Fig.1 : Advantages of a Robust Cloud Data Warehouse Strategy
- Seamless access to the data repository: Cloud data warehouses offer seamless remote access from anywhere which means that administrators can troubleshoot from home or anywhere outside of their work hours if required. Remote access capabilities also provide companies with the opportunity to hire staff across locations, thereby opening up talent pools that were previously unexplored. Cloud data warehousing provides self-service options and thus for its provisioning, companies do not need to rely on specialized employees.
- Low operating costs: Purchasing and maintaining an on-premise data center can be a costly affair. Companies need to ensure that the area housing a data center is cooled and that there is proper insurance coverage and availability of expert staff who can help with maintenance and troubleshooting 24X7. Cloud data warehousing, on the contrary, allows a company to achieve the same level of data management competency by only paying for the storage and computing power required. Today, the availability of flexible cloud data services such as Snowflake provides users with the liberty to purchase compute and storage separately depending on the requirements.
- Enhanced performance: Cloud data service providers mainly differentiate on the grounds of providing the most efficient compute and storage power for a fraction of the cost that would be incurred to replicate the same power on-premises. In the cloud data warehousing model, all upgrades are routinely performed automatically, so companies can have the latest capabilities at their disposal without experiencing downtimes while upgrading to the latest versions.
- Increased scalability: Opting for a cloud data services subscription can be as simple as opening an account with big providers like AWS Redshift, Microsoft Azure, Snowflake, and Google BigQuery. The subscription is often customizable and companies can easily scale their storage and computing capabilities based on requirements.
- Unmatched availability and security: While on-premise data warehouses historically have high uptime, they are not completely immune to costly outages, downtimes, and failures. Additionally, human errors and phishing attempts can also render an on-premise data warehouse vulnerable, making service unavailability and security a major pain point for companies. All major CDW companies focus on reliability features, such as data replication across regions and data centers to ensure constant service uptime and security.
5. Steps for successful cloud adoption
There are certain aspects which companies must consider while transitioning from a traditional data warehouse to a cloud data warehouse.
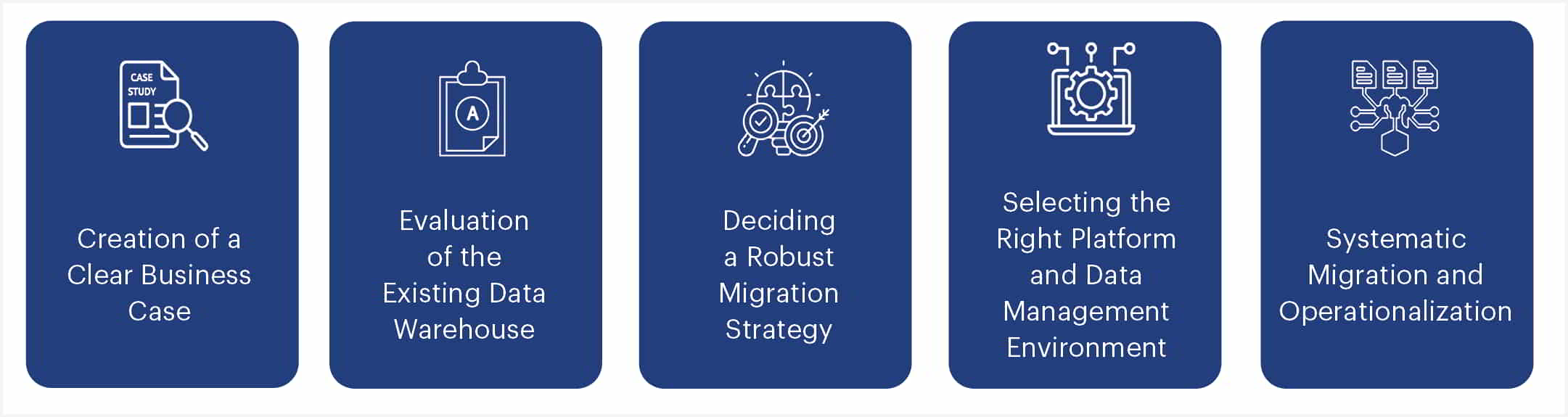
Fig. 2: Steps to consider while adopting cloud
- Creation of a clear business case: While deciding on a cloud migration strategy, companies need to determine what exact value they are looking to derive from the transition – is it cost savings, enhanced data capacity, greater agility, or faster query performance? A clear business case can help determine a seamless and successful migration strategy.
- Evaluation of the existing data warehouse: Companies should implement a robust enterprise data cataloging solution to get a clear picture of the data stored in the on-premise data warehouse and determine the data governance and data lineage across systems.
- Deciding a robust cloud migration strategy: There are three key options when it comes to migration strategies – lift and move on-premise warehouse to the cloud “as-is”, incrementally shift on-premise data warehouse to cloud, or develop a new cloud data warehouse from scratch. In order to derive the quickest value, companies should consider transitioning incrementally to the cloud while focusing on key use cases.
- Selecting the right platform and data management environment: Before moving to the cloud, a company needs to decide whether it wants to manage the infrastructure in-house (IaaS) or let the cloud service provider do so (PaaS). Cloud data management services and tools that encompass both on-premise and cloud can help businesses minimize disruption while shifting data incrementally between on-premises and cloud environments.
- Systematic migration and operationalization: In order to derive the best results, companies need to clearly define the test and acceptance standards at the initial migration phase. There should also be an adequate focus on planning the testing cycles and executing the migration process to shift ETL, Schema, metadata, data, applications, and users.
6. Organizational capabilities for cloud data warehousing
The transition to cloud data warehousing necessitates a methodical, well-planned approach along with some data management practices.
- Data visibility catalog: An intelligent data catalog can help companies reduce the time it takes to find the right data to transfer. Its downstream dependency recognition and lineage mapping also aid in lowering the risks associated with the “lift and shift” approach.
- Strong connectivity architecture: A robust integration architecture can connect and automate all of the data sources and applications needed, regardless of whether they are on-premises or in the cloud.
- Security and data compliance: It is critical to incorporate the appropriate degree of security into the cloud architecture at all levels, both technological and operation.
Need for a well-planned data strategy
Redundancies and inaccuracies are all typical issues when data is migrated from one system to another. When data migration occurs, advanced systems may view some data as a flaw, whereas older systems may perceive it as a useful data point. Some of the most common challenges and strategies to solve these are:
- Data complexity: The more data is migrated, the more conflicting data formats and variations can be found. Data formatted by an old system might not be accepted in the newer system due to different attributes. To resolve this, an automatic data integration solution needs to be used.
- Data quality: The format of data in the legacy system might be different from the new system where it is migrated and so data migrated could be corrupted or lost. One way to avoid this is to know exactly how many records are migrated into the new structure. If this number is not matched by the migrated results, it must be examined. Another option is to use commercial tools that can aid in monitoring the accuracy of each field of data.
- Data access: Data migrations could take significant time sometimes and that means there would not be accessibility to some data which can cause business interruptions. The strategy to overcome this issue is to retain the old data warehouse where all the original data is stored until all the data has been migrated.
- Charges for data migration: Data can be transferred to the cloud easily but certain vendors charge higher for moving the same data back to on-prem or to other service providers. Care needs to be taken to evaluate current and future business use and vendors need to be chosen accordingly.
- Security: While the companies offering cloud warehouse solutions do have all forms of security in place the firms using the public cloud should have their own formal cloud security and governance plan to keep the cloud usage regulated. It is a possibility that issues could start from the ground level and have a further impact on the public cloud platform.
- Costs: Moving to the cloud is cost-effective but without proper usage of the servers and other infrastructure, the cloud spend could spiral. A cloud management team would be the best way to keep usage and spend in check.
- Skilled resources: Data warehouses are complex to implement and for doing that skilled resources are required. Acquiring resources with the right skillset could be hard to acquire due to a gap in demand and supply, but can help in seamless management and migration of data over cloud warehouses.
7. Top ELT/ETL tools for cloud data migration
ETL (extract, transform, load) is a critical procedure in the entire cloud data migration strategy through which companies collate data from diverse sources and load it in the centralized cloud data warehouse. During the ELT/ETL process, relevant data is extracted from source files such as spreadsheets or databases and then processed and transformed to comply with the data standards of the cloud warehouse. This transformed data is finally loaded in the data warehouse.
ELT/ETL for data warehouse and analytics is an indispensable component. However, the best ELT/ETL tools vary on the basis of use cases and unique business requirements. Here is an indicative list of some of the latest ELT/ETL tools that companies can consider:
| Tool | Description | Features |
|---|---|---|
|
|
A distributed open-source platform used for querying, processing, and analyzing big data. The platform is infinitely scalable which makes it an ideal choice for even big tech giants like Apple, Microsoft, and Facebook. |
|
|
|
Creates a single, robust data warehouse by integrating data from SaaS services and data warehouses like Redshift, Snowflake, Azure, and BigQuery. It supports a wide range of data sources, with multiple SaaS sources and allows native custom integrations. |
|
|
|
An enterprise cloud data management solution that supports end-to-end data integration lifecycle. Being database-neutral it allows seamless compatibility while working with different sources of data, including SQL and non-SQL data repositories. |
|
|
|
Built for cloud data integration & transformation, it uses interactive UI and SQL and integrates with most new-age cloud databases and analytics platforms. |
|
|
|
A data management and analytics platform that helps to automate the process of collecting data from diverse data sources and ingesting it to data warehouses for seamless reporting. |
|
|
|
Data management through monitoring, profiling, and integrating data. The platform is compatible with both cloud and on-premise data sources and it comes embedded with many pre-built integrations. |
|
|
|
A cloud-based extract, load, transform (ELT) and ETL data integration platform that simplifies the process of integrating diverse data sources. It provides BI teams with an intuitive interface for building data pipelines |
|
8. Building a cloud data warehouse
Worldwide, spending by businesses on cloud computing and storage infrastructure is forecast to top $1 trillion in 2024. Going forward, cloud storage or cloud data warehouse is clearly going to play a critical role in enterprise cloud transformation strategy. While the move to cloud sure looks like a safe bet, business intelligence teams must keep a few important things in mind before jumping on the bandwagon, such as:
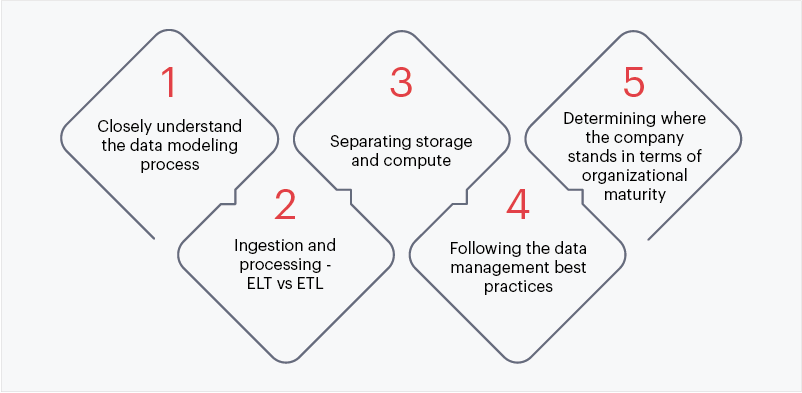
Fig. 3: Considerations before moving to the cloud
i) Closely understand the data modeling process
As a process, data modeling requires the business intelligence team to closely evaluate data process and storage. Data modeling techniques ideally include methods that govern data representation patterns, the preparation of data models, and communication of business requirements. The techniques essentially depend on some formalized workflows that include a sequence of objectives to be performed in an iterative manner, such as:
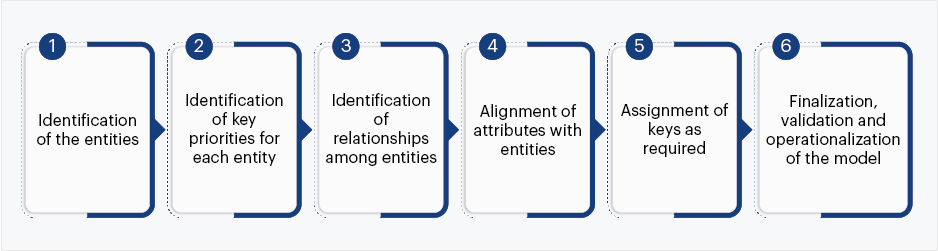
Fig. 4: Key steps in data modeling process
In cloud data warehouse architecture optimizing data retrieval speeds for generating analytics is the key. And this is where dimensional data models help create a difference. While Entity-relationship (ER) data models and relational data models emphasized efficient data storage practices, dimensional models focus on enhancing redundancy in order to make it easier for business intelligence teams to easily locate relevant data for retrieval and reporting purposes.
The two most popular dimensional data models include the star schema and the snowflake schema. In a star schema, data is cataloged as dimensions (reference information) and facts (measurable items). Here each fact is mapped with its related dimensions in a pattern that represents a star. The snowflake schema is similar to the star schema but it involves multiple layers of associated dimensions that make the entire pattern quite complex.
What are the benefits of star schema?
Star schema model offers the following benefits:
- Simpler queries: In this model, all the data is linked through the fact table and the multiple dimension tables serve as a single table for information. This makes queries comparatively simpler and easier to perform.
- Seamless business data reporting: Star Schema makes the process of retrieving business reports simple through period-over-period and as-of-as reports.
- High-performing queries: Star Schema removes the barriers in a normalized schema which enhances query speed and performance of read-only commands.
Challenges
The challenges of star schema include:
Star schema models can fail to enforce robust data integrity simply because of its denormalized architecture. Although there are countermeasures to stop anomalies from taking place, a quick update or insert command is enough to cause small data incongruities.
This data model is developed and optimized to cater to specific analytical needs and as denormalized data sets, star schema is suited for only simple queries.
What are the benefits of snowflake schema?
Snowflake schemas deliver the following benefits:
- Compatibility with OLAP database modeling tools: Some OLAP database management tools that data scientists leverage for data modeling and analysis are designed to be compatible with snowflake schema.
- Reduces disk space requirements: Data normalization in snowflake schema significantly reduces disk space requirements. In this data model, data scientists essentially convert strings of non-numerical data into keys that are comparatively less taxing from a storage standpoint.
Challenges
The challenges of star schema include:
Snowflake data schemas create multiple layers of complexity in an attempt to normalize the star schema attributes. This complexity often results in complicated source queries. In this model, complex joins lower the processing speed of cube data which is not the case for star schema.
ii) Ingestion and processing – ELT vs ETL
Data transmission from multiple disparate sources to a cloud data warehouse is done through an extract-transform-load or an extract-load-transform workflow. Selecting the right workflow is extremely critical in cloud data warehouse design. In the ETL workflow, data transformation is done before loading considering that no further transformation is required for analyzing and reporting. ETL served as the preferred workflow until the proliferation of cloud data warehouses with better data processing capabilities. Cloud data warehouses do not need to completely transform data before loading and data can be transformed eventually on the basis of requirements.
This data warehousing model offers the following benefits:
- While developing the data flow structure there’s no need to define the transformation logic.
- Only the relevant data can be transformed, unlike the ETL flow where the entire data needs to be transformed.
- ELT serves as an ideal workflow to manage unstructured data sets as the purpose of the data is not known beforehand.
iii) Separating storage and compute
While cloud data warehousing allows companies to collect and store large amounts of raw, structured and unstructured data, the majority only manage to process a small portion of the data they collate. Given this, cloud deployments that combine compute and storage often end up investing in additional compute capacity which in most cases stay underutilized.
While mass storage has become cheaper with time, computation has remained expensive. By separating storage and compute, data teams will have the opportunity to scale storage capacity economically depending on the data load while also scaling distributed computing depending on the data processing needs.
iv) Following the data quality management best practices
Business intelligence teams need to implement stringent data governance measures while building cloud data warehouses in order to ensure data availability, integrity, security and usability. A meticulous data governance strategy can help data teams ensure that data is trustworthy and reliable across channels and is not mistreated. Over the years, efficient data governance has evolved as a critical requirement in enterprise cloud migration initiatives, given the need for organizations to comply with stringent data control and privacy regulations.
As a part of the data governance process, creating a strong data lineage can help BI teams better understand, document and visualize data from its origin to the consumption stage. Data lineage can also help in identifying errors, implementing quick changes within the data management process and carrying out systems migration to save time. Other best practices that can help BI teams reinforce their data lineage process are data cataloging and data archival. While the former helps data engineers capture data asset metadata through a data mapping framework, the latter helps in storing data through indexes and metadata, irrespective of how the data may have originally been stored during active use. Data archival also helps companies reduce the cost to a significant extent by shifting cold or infrequently used data in lower-tier storage systems such as AWS Glacier, Azure Archive Storage and so on.
v) Determining where the company stands in terms of organizational maturity
The majority of organizations today are investing in cloud storage solutions building a cloud data warehouse or data lake on Azure, AWS, Databricks or Snowflakes. However, not all of them stand at a similar point in the overall organizational maturity curve. Whether a company is attempting a cloud shift for the first time or whether it is looking to simply modernize the data storage infrastructure in the cloud, the journey can raise several questions.
Similar to forming a team or developing a process, a company may need to closely understand how well its cloud migration efforts are progressing. It needs to religiously adhere to the best practices, follow the established standards and procedures, review performance against those standards and implement corrective measures if there are deviations. A meticulously developed maturity model from cloud experts can help a company understand where it stands in terms of implementation and the measures needed in order to improve.
9. Data migration strategy and planning
Understanding different data types for migration
Closely understanding the types of data being stored can help companies devise an effective cloud data management strategy. The following are the main types of data that a company will need to manage during cloud migration exercise:

Fig. 5: Different data types for migration
- Structured data: Structured data is often stored within a database or some type of database management application. These applications have the ability to track the activity and usage of data and provide versioning back to the source lineage of the file if managed from the start.
- Unstructured data: Unstructured data makes up the majority of enterprise data and it is not usable until it is processed. There can be over 1000 types of unstructured data formats in the form of office documents, image files, application data files like .dll or .ini and log files.
- Semi-structured data: Semi-structured data is neither structured nor unstructured. Rather it is partially structured data. It is not confined by a rigid structure to fit into a table-like format and it contains markers and tags that can help data engineers separate semantic elements while enforcing hierarchies of records.
Embrace a multi-temperature data management approach
A multi-temperature data management approach typically refers to storing frequently accessed data on fast storage – hot data, compared to storing less-frequently accessed data on slower storage space – cold data. Developing this approach needs a set of KPIs involving the data’s ‘temperature’ to help make both business and operational decisions. For example, while it may be practical to assume that two-year-old data will be less frequently accessed than data which is a month old, understanding this frequency of data access in more detail can help companies trigger actionable business decisions. Identifying what data changed over a given period along with the frequency of change can go a long way in helping BI teams come up with strategic inputs for operational and other business decisions.
10. Framework for optimizing cloud data warehouses
While using a cloud data warehouse can be a cost-effective option, certain best practices need to be followed to optimize costs and resources. At Sigmoid we have developed the below framework to optimize cloud data warehouse.
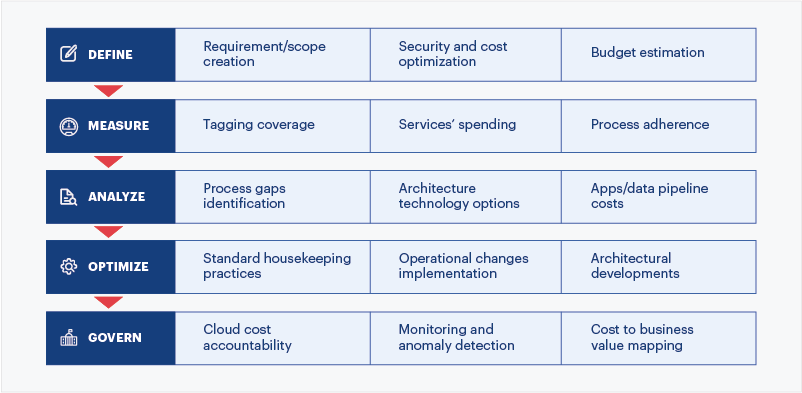
Fig.6: Framework for optimizing CDW
Define the current problems in areas such as uptime of data pipelines, performance and cost of data pipelines, analytics project requirements and current gaps in data organization to meet the project goals.
Measure insights pertaining to the data pipeline and infrastructure using proactive and reactive monitoring/logging. This then enables clear measurement of activities as part of data pipeline maintenance which includes:
1. Cloud infrastructure optimization
2. The frequency of recurring pipeline issues and their impact
3. Cost from incorrect/reprocessing data
4. Lag in data processing and process to meet requirements in terms of capability, capacity or feasibility
Analyze the process to determine data pipeline uptime, code releases, root causes of inflated costs, poor pipeline performance, and evaluation of options available to overcome these challenges.
Optimize the performance, uptime and costs by addressing the root causes. These root causes may not always be technical in nature but can also be process or people-related. Make optimization a recurring process rather than an unplanned one-off activity.
Control the improved system state in terms of cost, pipeline performance and uptime. Data engineering and DataOps teams should be accountable for the system state. Implement and improve monitoring/logging, cloud optimization and cost anomaly detection system to keep a close tab on undesired variations. Setup notifications for under and over-utilized resources.
Conclusion
Businesses now are looking beyond the time-and-money-saving opportunities of cloud migration. Rather, they are considering cloud data warehousing as a sustainable approach to become more innovative, agile and successful. While an increasing number of organizations are embracing cloud for their data analytics workloads, not all transition attempts will be smooth. There are several challenges to successful cloud migration such as pricing, security, complexity, cost management, performance issues, skills gap and data movement. Owing to the complexities involved, companies can consider working with cloud experts or providers who can advise on the right processes and technologies to go to market faster and also help mitigate implementation risks.