Deploying Machine Learning models with MLOps automation
Reading Time: 5 minutes

The last few years have seen growing acceptance and adoption of ML and its increasing impact on other technological advancements. The majority of companies however, are often stuck at the quagmire of productionizing ML in line with business outcomes. In fact, most artificial intelligence (AI) projects are stifled by the slow progress of ML proofs of concepts to the production stage. No wonder, only 13% of all data science projects or in other words one out every 10 projects is actually productionized.
It goes without saying that companies are lacking capability when it comes to driving ML models to production. It is therefore paramount for enterprises to expedite and simplify their ML initiatives to achieve business objectives successfully.
The Conventional Challenges: The Inability to Operationalize ML
While machines are being prepped to assume greater responsibilities across AI/ML-enabled operations, the truth is that many functionalities still rely on manual intervention. For one, data scientists are continuing to work in silos, detached from DevOps and engineering teams and are reliant on development processes that need to be manually converted to ML-ready pipelines. This also implies that the entire process has to be repeated every time there is a change in the logic pertaining to model training and data preparation. This often results in delayed deployment and resource-intensive processes. In some cases, it may also create a clear divide between the available technological innovations and business outcomes.
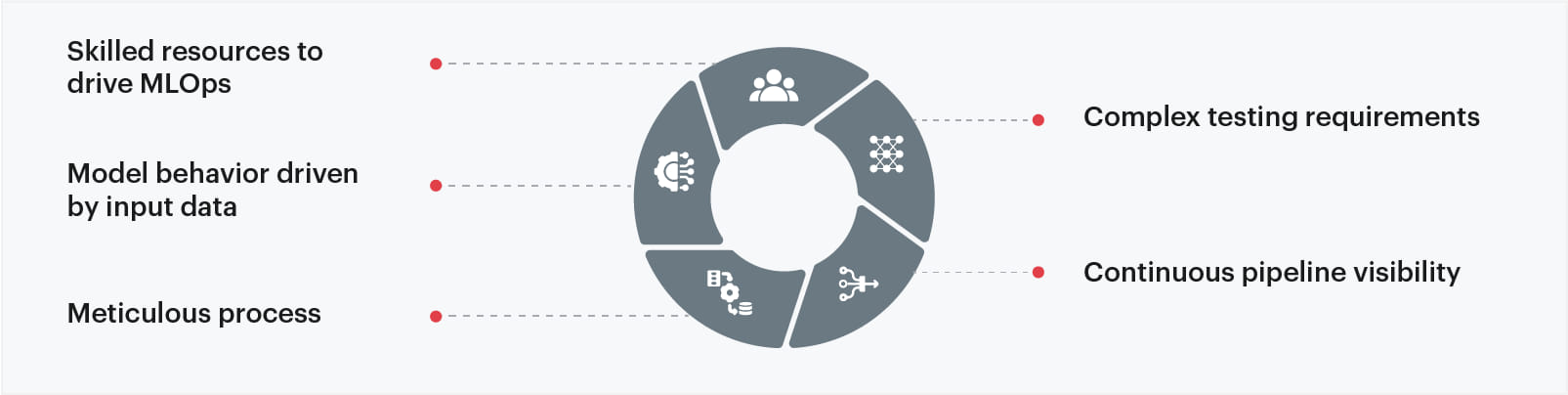
To operationalize ML, there has to be a greater emphasis on continuous integration and continuous delivery, (CI/CD), code, and metadata versioning. In fact, a good start is to follow the DevOps philosophy, which focuses on the perpetual delivery of large-scale software systems and apply it to ML systems. However, while software and ML-based systems have certain similarities, some pertinent challenges arise from the dissimilarities. Here are some of them:
- Skilled resources to drive MLOps: To drive ML operations (MLOps), enterprises require specifically-skilled resources, such as data engineers and data scientists. There is high demand for these roles and they traverse a number of complex functions, such as model development, data assessment, and analysis, and explore ML use cases that can then play a crucial part in developing the logic that makes machines function more independently in an operational environment.
- Model behavior driven by input data: Unlike software, ML is not only code but code + data. The artifact that goes into production by applying an ML model (based on an Algorithm) on a training dataset will affect the model in production. So, the behavior of the model is also dependent on the input data at the prediction time which cannot be controlled in any way.
- Meticulous process: Unlike software development, ML engineering requires more of an experimental approach. It requires thorough scoping, modeling, algorithm development, use of various features and configurations to identify what works the best, and proactively recognizing the appropriate problem-solving techniques. Currently, this development stage is tedious, long drawn out, and reliant on manual intervention.
- Complex testing requirements: Testing software systems have become simpler and linear over the last few years, especially when it comes to integration and unit testing. However, with ML, there are various other considerations for holistic testing. Apart from the basic steps of software testing, ML-specific testing also includes data and model validation, and trained model quality evaluation.
- Continuous pipeline visibility: When it comes to deployment, ML systems require multi-step pipelines that are critical for automated retraining and deployment. This step is still highly complex in today’s scenario as it needs various manual steps in the process to be automated before data scientists and engineers deploy the ML models. This leads to further productionizing challenges borne from poor coding and evolving data profiles. Continuous tracking of performances is essential to evaluate the deviations from expectations and is fed back to the system to improve the performances.
MLOps: Leveraging the Power of Automation to Build Truly Intelligent Machines
For data-driven enterprises today, the journey begins with strategic understanding and adoption of AI/ML. It is crucial for enterprise leadership to take stock of the organizational infrastructures, objectives, and pain points before embarking on the MLOps journey. The following is a step-by-step guide that companies can follow to drive successful MLOps automation.
- Running experimental codes to create a workable model: Upon successful adoption of ML and applying it to the existing use cases, most of the development and deployment steps of the ML model will initially be manual. Data scientists and engineers begin to develop and then serve the model as a prediction service. Initially, script-driven and interactive processes are manually driven by the data experts, thereby assessing, analyzing, and developing experimental codes to create a workable model. At this stage, there is minimal emphasis on CI/CD and performance evaluation. The focus is on the deployment of a trained model as a prediction service.
- Data pipeline automation: As the MLOps journey progresses and a model is established, the focus turns to ML pipeline automation. At this stage, data collection, analysis, and validation are automated, meaning that continuous training of the model results in continuous delivery. The speed of experimentation intensifies with the extent of applying their outcomes in the production environment. DevOps is unified, codes for components and pipelines are modularized, resulting in codes becoming reproducible and components becoming independent in the runtime environment. As model deployment is automated, there is a continuous delivery of prediction services for new models. Once the whole training pipeline is deployed, it serves the trained model automatically and continuously. Some of the additional highlights of this stage of MLOps are data and model validation, a repository of features, metadata management, and ML pipeline triggers.
- Shifting the pipeline to the production environment: For the ML pipeline to be applied to the production environment with reliable and continuous updates, the CI/CD system has to be seamlessly automated. With a lightning-fast and automated CI/CD system, the data experts can churn fresher ideas around model architecture, features development, and hyperparameters, making the development, testing, and deployment of new pipeline components in production seamless. The automated CI/CD of the ML pipeline enables perpetual experimentations around the ML algorithms to then aid in developing source codes. Continuous pipeline integration and delivery offer new components in the production environment, which ensures newer implementations. Automated triggers help execute the pipeline in production and continually implement that trained model in the environment. Finally, the real-time performance of the model is monitored, and depending on the data-driven insights, iterative steps can be taken.
As enterprises look to the future, MLOps will be a key enabler of their data analytics pursuits. Strategic AI/ML programs, onboarding of skilled and creative data scientists and ML engineers, and innovation-mindedness will be key tenets of their journeys as they aim at unlocking business value at scale.
About the Author
Nitin is Engineering Manager at Sigmoid and has a decade of experience working with Big Data technologies. He is passionate about solving business problems across Banking, CPG, Retail, and QSR domains through his expertise in open source and cloud technologies.
Featured blogs







Featured blogs