Best practices for snowflake implementation
1. Introduction
Businesses that thrive on advanced analytics are continuously improving the way they manage increasing volumes of data. Often the prime factor for business success – effective data management, has been a cornerstone of holistic enterprise growth and development.
Even before analytics can yield effective business outcomes, the underlying data has to be hosted and managed effectively. Snowflake enables every organization to mobilize their data with Snowflake’s Data Cloud. It allows for data storage, processing, and analytic solutions and offers enterprises a single-stop cloud-data warehouse solution.
2. The architecture
Snowflake is built on top of existing public cloud infrastructure and is ideal for organizations unwilling or unable to dedicate resources towards setup, maintenance, and support in-house servers. But perhaps, the most defining factor that sets Snowflake apart is its data sharing capabilities and architecture. Furthermore, organizations are able to share secure and governed data quickly and in real time with the sharing functionality.
Snowflake also offers flexibility in terms of organizational requirements. The ability to decouple storage and compute functions means they can choose which function to focus on instead of paying for bundles. Overall there are three, independently scalable layers of Snowflake architecture:
Database storage: Runs independently of compute resources and manages data storage, organization, metadata, statistics, compression, structure, and file sizes automatically on all stored structured and semi- structured data.
Compute layer: Consists of virtual warehouses that can access all data in the storage layer and execute query specific data processing. This enables automatic and non-disruptive scaling.
Cloud services: This eliminates the need for manual data warehouse tuning and management by coordinating the entire system using ANSI SQL. Services include:
- Access control
- Query optimization and parsing
- Metadata management
- Infrastructure management
- Authentication
Here’s a diagrammatic overview of the overall system architecture on Snowflake and the most common data pipeline flow on Snowflake
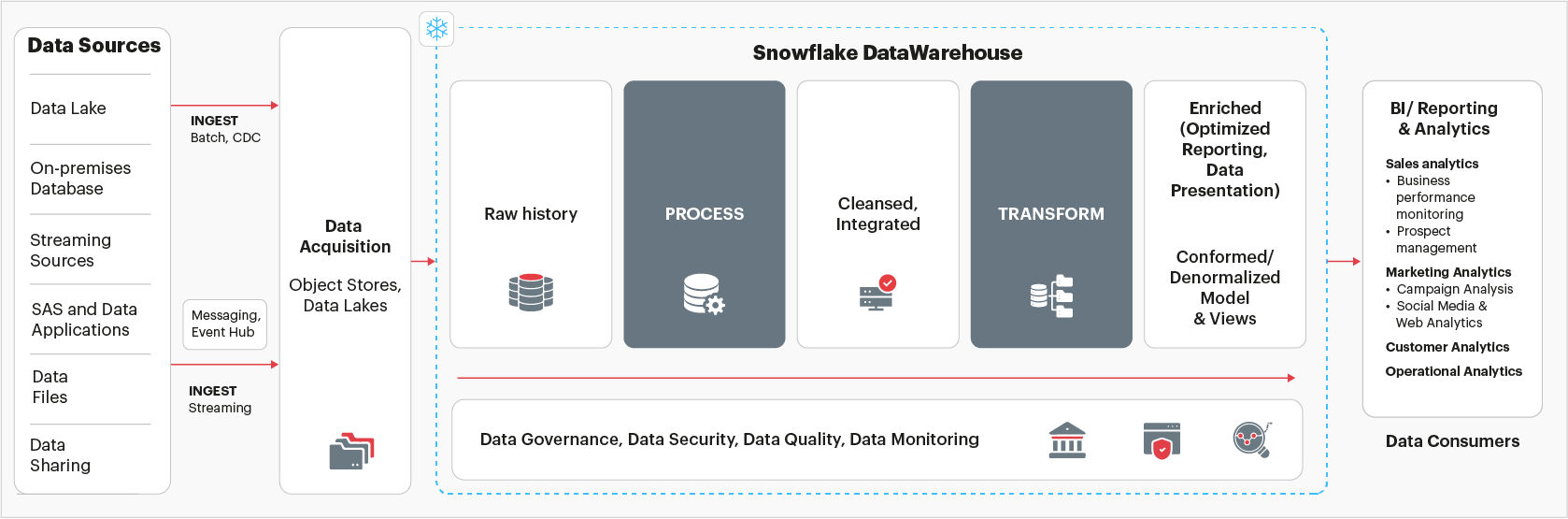
Fig 1: System architecture on Snowflake
3. The implementation journey
As with all changes, there are a few caveats that businesses will do well to account for before plunging into a full-fledged Snowflake implementation and get the most out of it. Here are the key considerations:
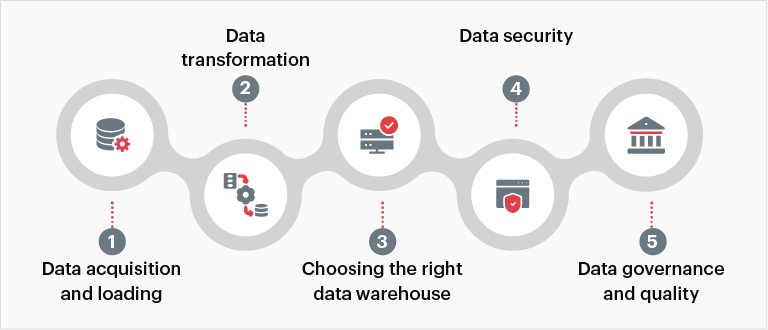
Fig 2: Key considerations when implementing Snowflake
1. Data acquisition and loading
Efficient data loading is paramount especially since 94% of all workloads are processed in cloud data centers as of 2021. Faster data loading can not only mean getting faster business value, it also saves valuable organizational resources. Businesses can look into tools that simplify bulk loading, running complex queries, and parallel data loading through multiple threads to achieve faster data loading.
2. Data transformation
After loading the data in the Snowflake landing table, companies can leverage several tools to clean, enrich and transform the data. For instance,
- ETL tools: With ETL tools, companies often have the liberty to leverage the existing data engineering team and its skillset. With this approach, companies need to follow the “push-down” principle where the ETL tools run the search queries on the data pushed to Snowflake to drive maximum advantage from the architecture that is scaled up.
- Stored procedures: Besides JavaScript API, Snowflake is expected to soon launch a procedural language referred to as Snowflake Scripting which includes support for dynamic SQL, cursors and loops. These features in cominationation with functions like Java User Defined Functions and External Functions can be leveraged to create high-end data transformation logic in Snowflake.
- Tasks & streams: An effective yet simple method of implementing change data capture (CDC) in Snowflake is through Streams. Companies can combine Snowflake Tasks and Streams on the ingested data to achieve near real-time processing.
- Java and Spark on snowflake: By leveraging Snowflake API which has been recently released Data engineers and scientists can now load data using InteliJ, SBT, Visual Studio, Scala and Jupiter where Spark DataFrames are translated and executed automatically as Snowflake SQL.
- Transient tables: Companies can break down complex pipelines into smaller steps to write intermediate results to transient tables. This can make it easier for data teams to test and debug the ingested data.
3. Choosing the right data warehouse
While selecting an effective and efficient warehouse companies can experiment with diverse query types and warehouse sizes to determine the right combination that caters to specific workload and query needs. Companies need not essentially focus on the size of the warehouse. Snowflake runs on a per-second billing mode and so companies can leverage larger warehouses depending on the requirement and suspend usage when they are not in use.
4. Data security
Companies need to ensure that during Snowflake implementation data is safeguarded both at transit or rest. This should be aligned with the overall data lake security strategy that takes into account both current and future threats across layers such as physical infrastructure, access controls, external network interfaces and data storage.
5. Data governance and quality
The incredible scalability that Snowflake offers can also hamper the data quality – in excessive amounts and of non-validated low quality. It is critical to ensure that the data going into the pipelines are managed and validated to gain valuable, trustworthy, and actionable insights at the end of the process. Here, enterprises might consider leveraging data validator tools that can not only define data quality rules visually but also enable them to follow up on data issues while providing insights into failure. Maintaining pipeline data quality can reduce process complexity and help counter costs as well.
Looking to migrate to Snowflake?
4. The data engineering best practices
To make best use of Snowflake and optimize data, here are seven important considerations:
- Evaluate virtual warehouse options
- Select the right warehouse sizing
- Optimize cost for resources, compute & storage
- Set up robust network security policy
- Split user authentication based on system defined roles
- Develop watertight security & access controls
- Streamline data loading & enhance query performance
Let us take a detailed look at each of the considerations and how the data engineering best practices can lead to Snowflake success.
4.1- Evaluate virtual warehouse options
Virtual warehouses are a cluster of compute resources in Snowflake providing required resources to execute SQL SELECT statements and perform DML operations. It is important to execute relatively homogeneous queries (size, complexity, data sets, etc.) in the same warehouse. The best practices also include experimenting with different warehouse sizes before deciding on the size that suits the requirements and the usage of “auto-suspend” and “auto-resume” features depending on the workloads to save costs. Warehouse suspension and resumption take time, which is noticeable for larger warehouses. It is therefore necessary to keep the warehouse running if the enterprise needs an immediate response.
Some of the other considerations are:
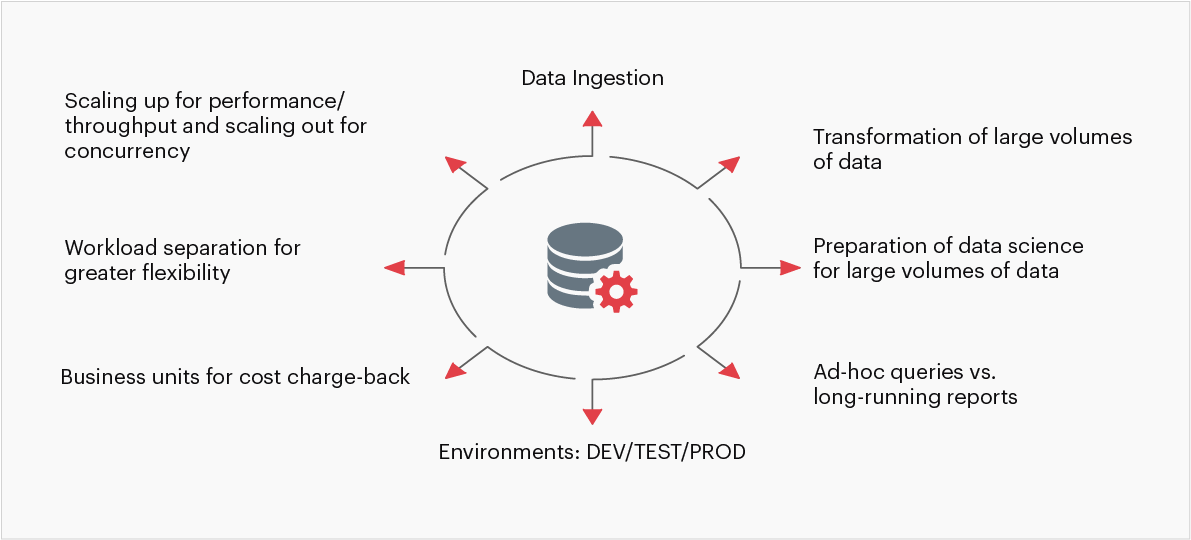
Fig 3 Evaluation criteria for selecting the right type of data warehouse
4.2- Select the right warehouse sizing
For the virtual warehouse to function on optimal level and provide desired outcomes, the size of the warehouse must be intelligently ascertained. For that, the warehouse must be aligned with the workload. Here is a look at the various sizes of warehouses:
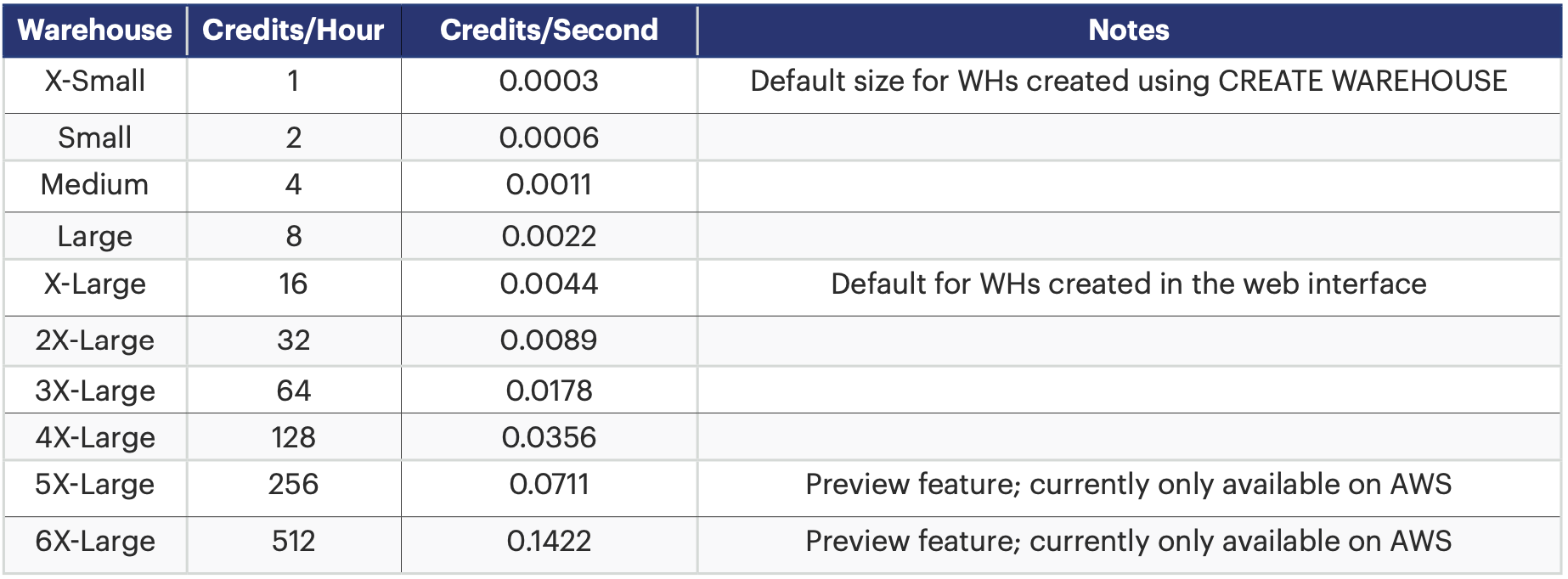
Table 1: Snowflake warehouse sizing
For warehouse sizing success, here are the three things that enterprises must do:
- Right sizing: Recognizing workload patterns, linear performance improvements, gradually increasing warehouse size
- Scaling up and out: Improving individual query performance and data load performance concurrency, improving session/query concurrency and identifying the right cluster size to avid queuing
- Automating suspend/resume: Offering on-demand, end-user workloads and suspending idle time settings, programmatically suspending/resuming scheduled jobs where process orchestration is controlled
Here is a snapshot of warehouse alignment with workloads:
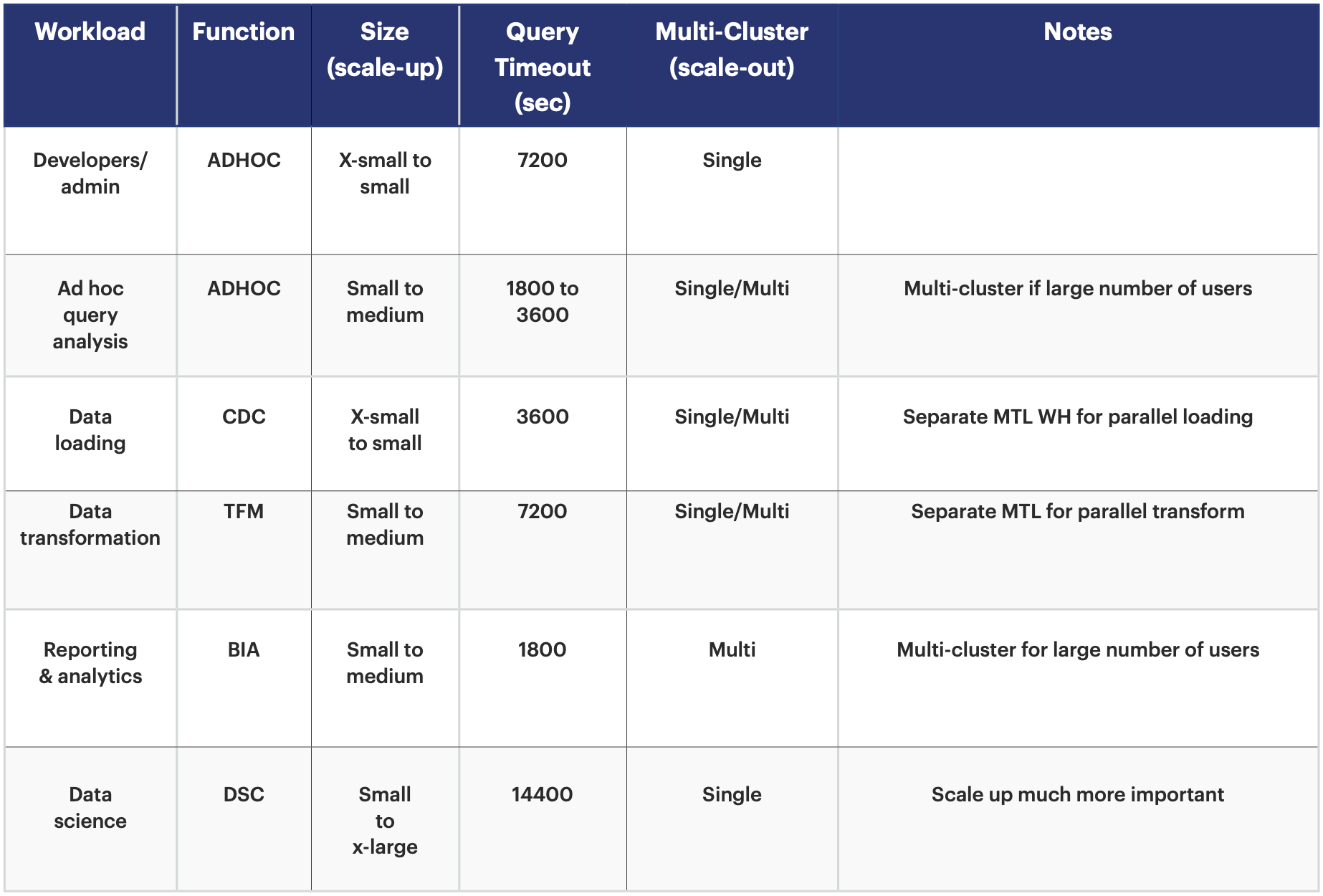
Table 2: Snowflake warehouse alignment with workloads
4.3- Optimize cost for resources, compute & storage
In order to optimize costs, here are the key areas of consideration:
Resources: The resource monitors include aligning with team-by-team warehouse separation for granular cost governance, setting it on account level if team-by-team quotas are not needed, leveraging tiered triggers with escalating actions, and enabling proactive notifications.
Compute: The resource monitors and viewing usage
Storage: There are two types of storage:
- Time-travel storage: The focus areas include dimensional tables, persistent staging areas, materialised relationships, derivations, and other business rules. The action points include detection of high churn, verification of retention period on all large or high churn tables, reduction of retention period if data can be regenerated/reloaded and time/effort to do so is within acceptable boundaries/SLAs, and use of periodic zero copy cloning.
- Failsafe storage: The focus areas include staging tables, intermediate result tables, increased responsibilities for developers, analysts and data scientists, and tool materialised results. The action points include following permanent tables with full CDP() lifecycle, not using failsafe for temporary/transient tables, utilizing temporary tables for session-specific intermediate results in complex data processing workflow, dropping temporary tables as soon as the session ends, utilizing transient tables for staging where the truncate/reload operations occur frequently, and considering designation databases/schemas as transient to simplify table creation.
4.4- Set up robust network security policy
Network security policies play a crucial role in enterprise success. For robust security, here are the four areas to consider:
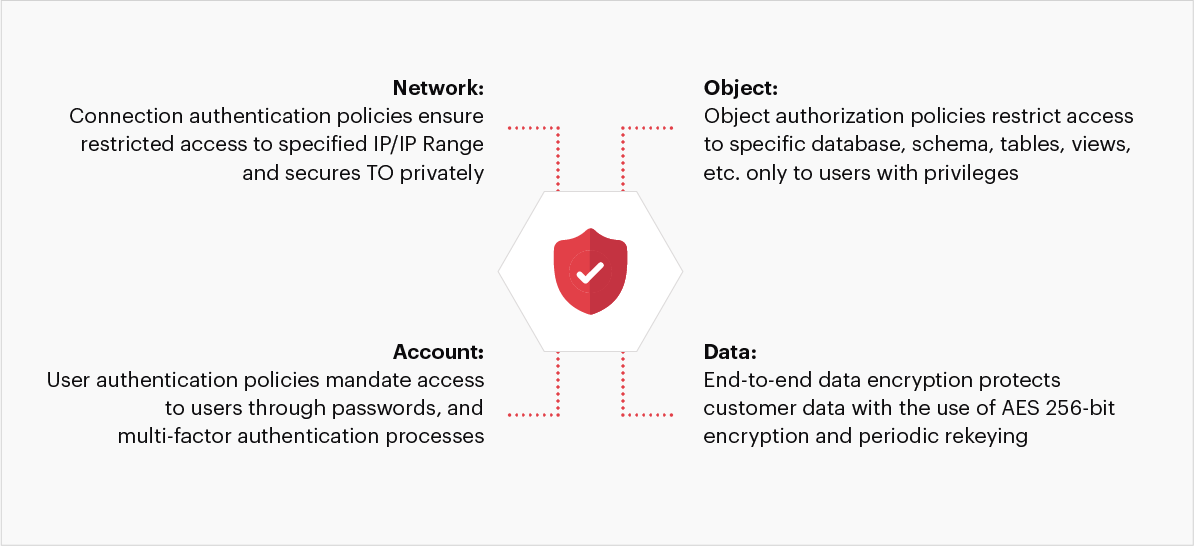
Fig 4: Key components of network security
4.5- Split user authentication based on system defined roles
User authentication relied on role management of administrators, developers and DevOps flow, end users, and service accounts. To make the process seamless and extensible, user authentication is demarcated as per the following system defined roles:
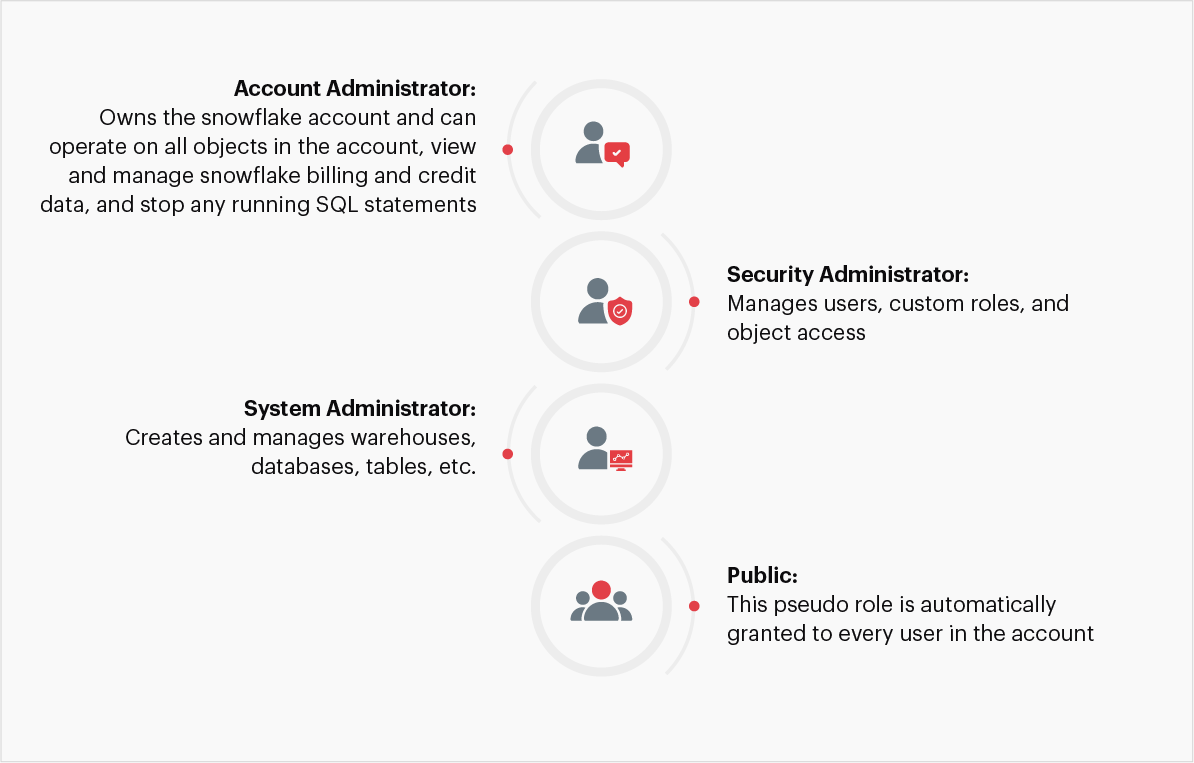
Fig 5: Role based access controls
4.6- Develop watertight security & access controls
For watertight security and access controls, the four key concepts are securable objects, privileges, roles, and users. The aligned best practices include use of schema-level grants, creation of current and future grants, and use of managed access schemas. Here is a snapshot of the role-based access architecture:
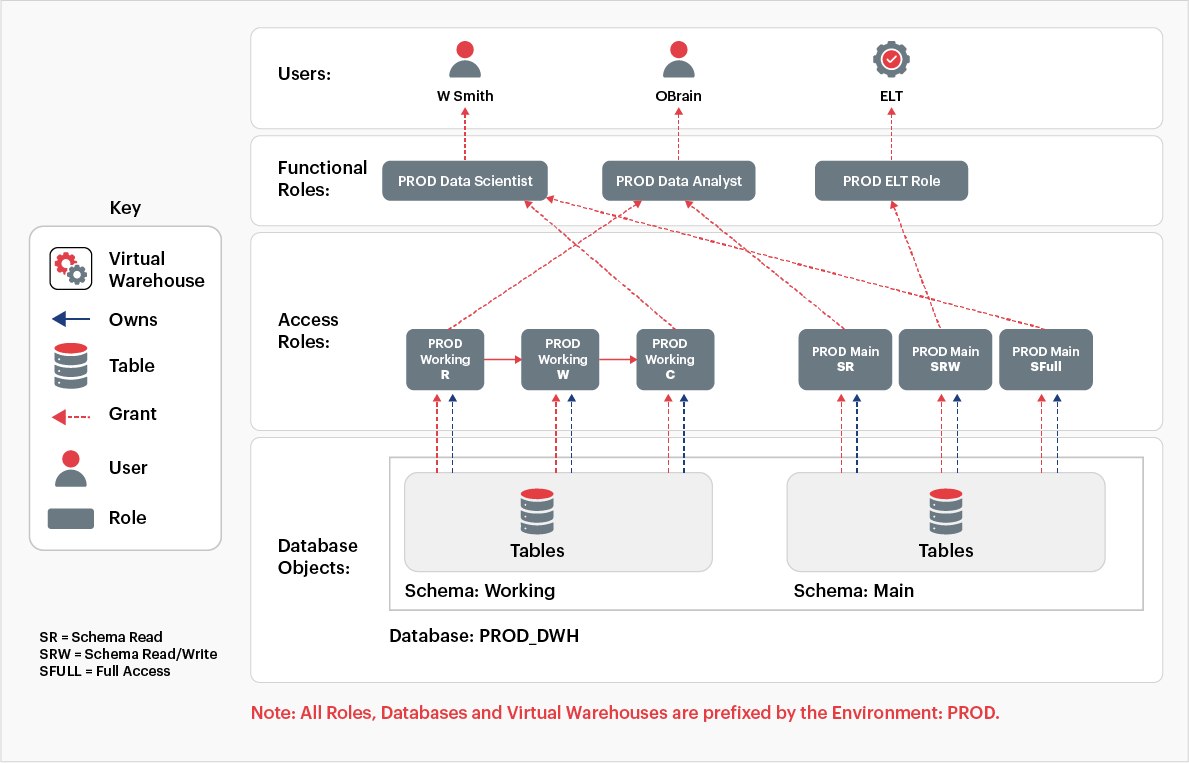
Fig 6: Role based access architecture
The securable objects sequence looks like this:
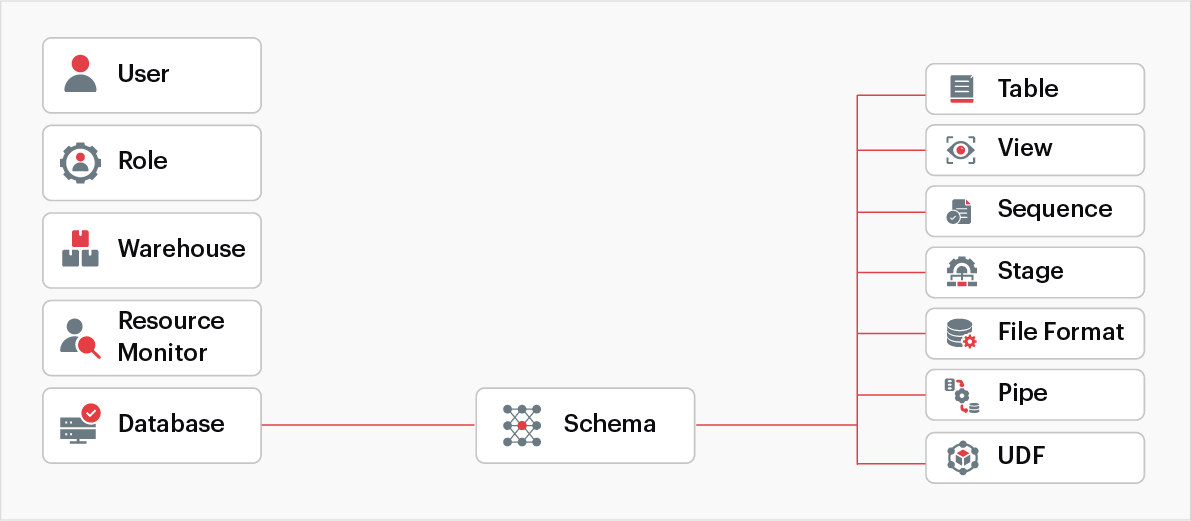
Fig 7: Securable objects
The system-defined roles that aid role-based access controls are as follows:
Account administrator: This administrator owns the Snowflake account and can operate on all account objects. This role is granted only to a limited number of users.
Security administrator: This administrator can manage, modify, and monitor any user, role, or session, and can modify or revoke any grant.
System administrator: This administrator has the privileges to create warehouses, databases, and other objects, and grant those same privileges to custom roles. Snowflake recommends assigning custom roles to the system administrators and their descendants.
User administrators: This administrator can create users and roles in the account and grant those same privileges to other custom roles.
Public: This pseudo-role that is automatically granted to every user and every role in the account, and it can own securable objects. Objects owned by public are available to every other user and role.
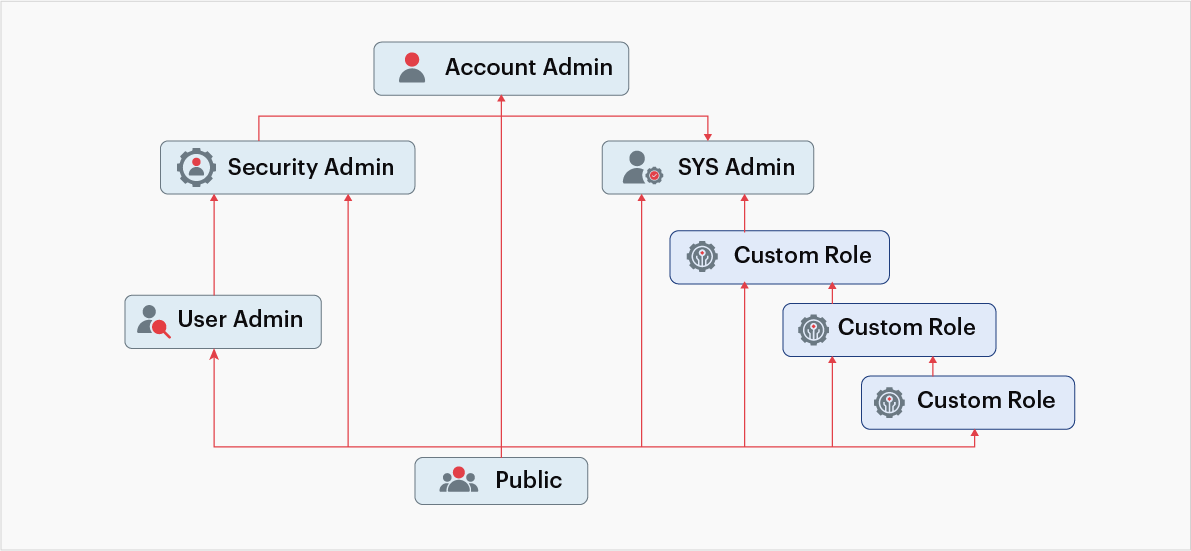
Fig 8: System defined roles (Adapted from Snowflake documentation)
4.7- Streamline data loading & enhance query performance
4.7.1- Data loading
The multi-stage process of landing the data files is initiated in cloud storage and is then loaded to a landing table before transforming the data. Breaking the overall process into predefined steps makes it easier to orchestrate and test. Here are some of the notable best practices:
Focus on the ingestion pattern:
- Use bulk loading to get the data into tables in Snowflake. Leverage the scalable compute layer to do the bulk of the data processing
- Delete from internal stages files that are no longer needed to get an improvement in performance in addition to saving on costs
- Snowpipe in micro-batching scenarios
- Isolate load and transform jobs from queries to prevent resource contention. Dedicate separate warehouses for loading and querying operations to optimize performance for each
Prioritize file sizing:
- It is important to optimize the number of parallel loads into Snowflake. It is recommended to create compressed data files that are roughly 10 MB to 100 MB in size.
- Aggregate the smaller files to reduce processing overhead.
- Split the large files into a number of smaller files for faster load. This allows you to distribute the load between servers in the active Snowflake warehouse.
Prepare delimited text files:
- Files must have data in ASCII format only. The default character set is UTF-8. However, additional encodings can be mentioned using ENCODING file format option.
- Within the files, records and fields should be delimited by different characters. Note, that both should be a single (necessarily not same) character. Pipe (|), caret (^), comma (,), and tilde (~) are common field delimiters. Often the line feed (n) is used as a row delimiter.
- Fields that have delimiter should be enclosed in single or double quotes. If the data being loaded contains quotes, then those must be escaped.
- Fields that have carriage returns (r n) should be enclosed in single or double quotes too. In windows system, carriage returns are commonly introduced along with a line feed character to mark the end of a line.
- Each row should have the same number of columns.
4.7.2- Query performance
For enhanced query performance, here are the key considerations and best practices:
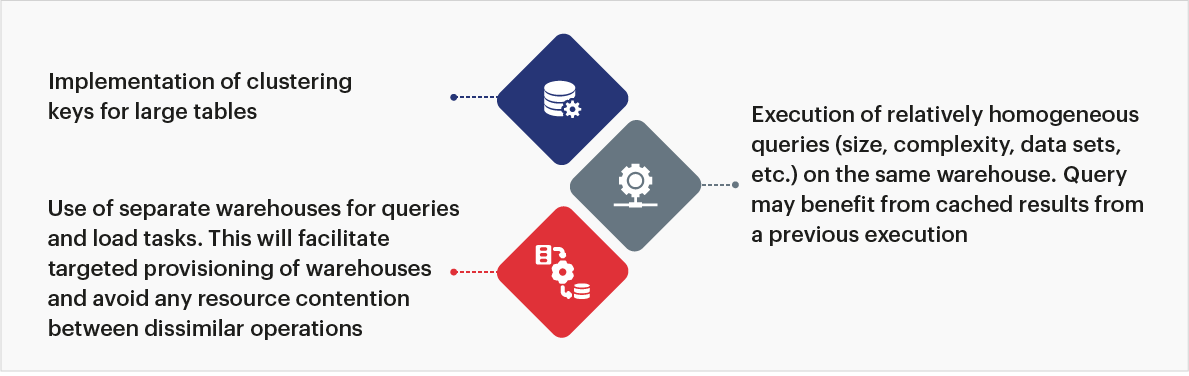
Fig 9: Best practices for query performance
Conclusion
Today, it is easy to use inappropriate tools and options amidst a sea of choices. However, organizational data teams must adhere to guidelines and best practices to ensure that the implementation of Snowflake is seamless and successful. It is critical for enterprises to avoid major errors or lapses in judgment at the onset or address them quickly. Otherwise, down the line, it can turn out to be substantially onerous, and a time-, resource-, and cost-intensive task, derailing the original business goals and expected outcomes.
On the other hand, carefully considering and following the outlined implementation guidelines can help propel a business towards a successful Snowflake implementation. And owing to its modern, future facing attributes, leveraging a virtual warehouse like Snowflake can not only guide a business through present market challenges but also ensure future resilience and progress.