---
# Enterprise Data Management Solution | Modern Data Engineering
**URL:** https://www.sigmoid.com/ebooks-whitepapers/data-engineering-overcome-challenges-in-enterprise-analytics/
Date: 2021-03-17
Author: Sigmoid
Post Type: page
Summary: How data engineering amplifies business value of advanced analytics Chapter- 1 Introduction Chapter- 2 Big data challenges Chapter- 3 What is data...Read More...
Featured Image: https://www.sigmoid.com/wp-content/uploads/2023/04/Data-Enginnering.jpg
---
# How data engineering amplifies business value of advanced analytics
[fluentform id="135"]
[Chapter- 1 Introduction](#chapter-1)
[Chapter- 2 Big data challenges ](#chapter-2)
[Chapter- 3 What is data engineering?](#chapter-3)
[Chapter- 4 Data as competitive advantage](#chapter-4)
[Chapter- 5 Data engineering – skill](#chapter-5)
[Chapter- 6 Winning DE team](#chapter-6)
[Chapter- 7 Data engineering with DataOps](#chapter-7)
## 1. Introduction
As per a Gartner survey, nearly a third of data and analytics leaders identified deploying their data and analytics efforts in existing business processes and applications as the most significant challenge.
The whitepaper discusses how well-defined [modern data engineering](/data-engineering/) processes create a robust foundation for consistently delivering insights at scale and overcome big data challenges that companies face such as managing data, creating [data pipelines](/etl-and-data-pipeline/), and more. Readers will learn more about:
- Importance of data management for enterprise analytics
- Impact of open source technologies in analytics
- Data processing cycle
- Differences between software and data engineering processes
- Building an efficient data engineering team
## 2. Big data challenges impede analytics
While organizations are eagerly adopting data-centric initiatives, many struggle with the processes and technology required to deploy models into production. As per a Gartner survey, nearly a third of data and analytics leaders identified deploying their data and analytics efforts in existing business processes and applications as the most significant challenge. The toughest challenge for AI and advanced analytics is not coding, but data management at scale. Writing ML code is just one small part of what goes into successful projects. The [success of an AI project](/blogs/mlops-for-effective-ai-strategy/) is determined by the efficacy of its data models.
According to research by Gartner, companies consider poor data quality to be responsible for an average of $15 million in lost earnings per year. On the other hand, [good quality data](/data-quality-management/) means better business decisions, better marketing, and more profitable relationships.
As data sources continue to diversify over time, organizations will need to find ways to implement their data efforts across business units and processes. They need to also focus on making the right data available to seamlessly transition from data experimentation to production process. And it is here that the emerging practice of advanced data engineering can help companies address critical data accessibility gaps. A machine learning (ML) project is bound to fail if it does not have [data engineering abilities](https://sigmoid-image.s3.amazonaws.com/wp-content/uploads/2022/04/27123219/BeginnersGuideToDE.pdf) on board from the outset.

Fig. 1: Data Management Challenges[1](#reference)
## 3. What is data engineering?
[Data engineering tools ](/data-engineering/)help build data infrastructure and prepare it for further analysis by data analysts and scientists. The major difference between data scientists vs data engineers is that the latter manage data so that it remains accessible and usable by others including data scientists. Data engineering tools drive building and operating the data infrastructure to prepare it for further analysis by data analysts and scientists. In short, it enables data users across the organization with clean, quality data they can trust, so they can drive better business insights and actions.
### Benefits of data engineering
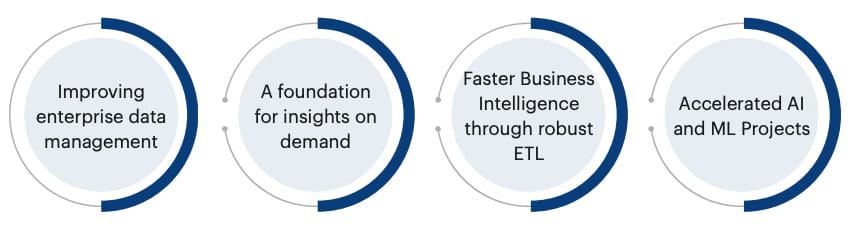
### Improving enterprise data management with analytics
At the most fundamental level, data engineering involves establishing a comprehensive data management framework. [Constructing data pipelines](/events/cloud-webinar/) is the core responsibility of data engineering. These pipelines extract data from many disparate sources and collect them into a single [data warehouse](/blogs/cloud-data-warehouse-is-the-future-of-data-storage/) that represents the data uniformly. A good data infrastructure mitigates issues such as
- Data corruption
- Latency
- Disparity in data sources
### A foundation for insights on demand
The ability to continuously improve processes, adapt to the fast-evolving technology landscape, and cater to ever-advancing analytics needs can be a daunting task for most businesses. With a plethora of environmental factors impacting the way organizations run on a daily basis, insights on demand become a must-have for every business function to respond in time. Dedicated data engineering teams have to their credit the knowledge of effortlessly handling petabytes of data every second and the means to overcome associated analytics and big data challenges. This allows the business to converge efforts on the bottom line without the dilemma of scaling technologies or teams that enable seamless flow of useful data to every system and everyone that needs it.
### Faster business intelligence through robust ETL
Data is only as good as its subjective interpretations. Data engineering is primarily concerned with gathering data, processing it, and making it available for comprehensive analyses and the creation of a unified picture. In many ways, this encapsulates the fundamentals of business intelligence (BI). The overall information management framework, however, is what distinguishes data engineering from BI. A well-executed data engineering practice, like BI, can have enterprise-wide positive effects.
Data engineering, for example, reinforces the data management cycle by combining data from multiple sources to create a data lineage. This not only makes information more accessible, but it also gives the data a more holistic context. This increases the likelihood of obtaining a smaller number of accurate subjective interpretations. As a result, the data management framework has a context-free data flow from beginning to end. Businesses are naturally better positioned to accelerate decision-making and, in the process, bolster their BI projects through [efficient data extraction, transformation, and loading (ETL) initiatives](/blogs/etl-on-cloud-transforming-big-data-analytics/) by leveraging data lineage information.
### Accelerated AI and ML projects
The success of an AI project is determined by the efficacy of its data models. These models, in turn, depend on the timely availability of reliable data.
According to the 2019 MIT Sloan Management Review, 70% of all enterprise AI initiatives fail[2](#reference). Another report revealed that the complexities of accessing and preparing data was the second most cited barrier to the success of AI projects[3](#reference).
Data engineers help data science teams and data analysts find the right data and make it available in their environment. They ensure that data is trusted, sensitive data is masked and data engineering pipelines are operationalized. This allows data scientists to spend less time on data preparation and channelize their efforts towards solving business problems.
Data engineering and AI thus share a symbiotic relationship. Data engineering acts as a critical enabler of AI and ML by helping create a clean, reliable corpus of data. On the other hand, embedding [AI and ML capabilities](/machine-learning-operationalization-mlops/) into the numerous layers of the data management framework can drive great improvements in areas like data ingestion and query performance.
In many ways, data engineering complements data science initiatives where it’s extremely critical to optimize the way models are developed. It is here that the data monitoring skills of data engineers become a critical requirement. Data engineers can leverage this skill to help data science teams identify and address issues faster. In short, by drawing on each other’s skills and strengths, data engineers and scientists can quickly transform a complicated data workflow into an effective feedback loop that continuously suggests ways to improve through usable insights.
Thomas H Davenport in his timeless HBR article: Competing on analytics[5](#reference) says – At a time when firms in many industries offer similar products and use comparable technologies, business processes are among the last remaining points of differentiation. And analytics competitors wring every last drop of value from those processes. So, like other companies, they know what products their customers want, but they also know what prices those customers will pay, how many items each will buy in a lifetime, and what triggers will make people buy more.
Analytics competitors do all those things in a coordinated way, as part of an overarching strategy championed by top leadership and pushed down to decision-makers at every level. Employees hired for their expertise with numbers or trained to recognize their importance are armed with the best evidence and the best quantitative tools. As a result, they make the best decisions: big and small, every day, over and over and over.
With time, data management tools have also become increasingly more accessible and affordable for companies. Big data analytics platforms, for instance, are helping smaller organizations with the opportunity to derive actionable insights for the data and in the process, drive ROI from their data projects. Going forward, as these tools become cheaper, their usability will naturally increase. And, in order to ensure maximum returns from the tools, companies will have to focus on fortifying their data engineering initiatives.
Some of the other trends that are further expected to amplify the importance of data engineering going forward are:
Almost 75% of all the data available today were created in the last five years alone. In the next five years, it will grow by another 152% [6](#reference).
- The rise of Open Source Technologies
- Data-at-scale
### The rise of open source technologies
Data engineering has come a long way since the early days of closed-source proprietary platforms and tools. Today, the rise of open-source software and tools and their growing popularity in enterprise projects present a different picture for data engineers. The availability of open source has provided organizations with a way to minimize vendor lock-ins and even do away with them entirely. As more open-source tools become available data engineers will need to incorporate them wisely to maximize efficiency while reducing the cost of processes.
### Data-at-scale
Simply put, the amount of data at our disposal is increasing exponentially. As this trend continues, two things are bound to happen. Firstly, there will be a growing need for data engineers. Secondly, data engineers will need to focus on streamlining processes and perpetually adapt to the availability of newer, more proficient data engineering tools.
For businesses to make the most of their data, they will need to focus on creating a complete support structure for the analytics and data science team. And, this requires generous investments in data engineering. Irrespective of their existing analytics capability, businesses will need to understand the importance of long-term goals like a data-first culture and exploring data analytics in auditing opportunities, and overcoming challenges.
## 4. Data as the cornerstone of competitive advantage
With almost every enterprise focusing on software development and commoditizing other business functions, data engineering is quickly becoming the new competitive frontier. By harvesting data from a wide range of structured and unstructured sources, a robust data management framework can help businesses account for external factors such as [customer behavior](/customer-analytics/) in their decision-making process. For instance, retailers use engineered data from social media and online portals to analyze their customers’ purchase behavior to provide relevant suggestions.
## Deliver a scalable data infrastructure for AI/ML initiatives
[lc_get_post post_type="lc_block" slug="whitepaper-middle-contact-form"]
## 5. Data engineering – a specialized skill
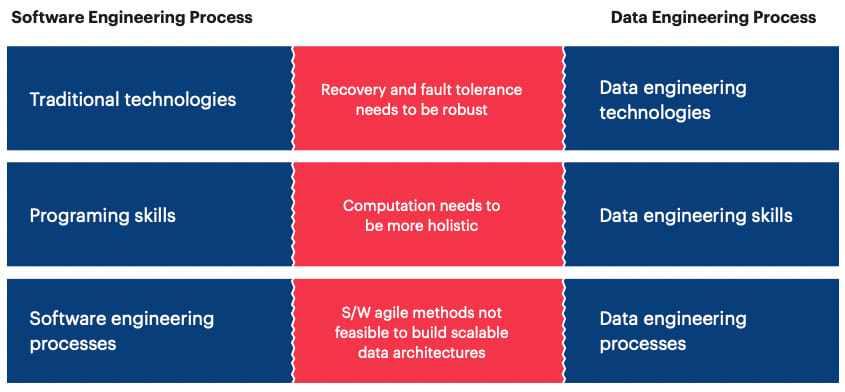
Fig. 2: Gaps between software and data engineering
Although data engineering has risen as a specific skill from the software engineering profession, there are very specialized activities and processes central to data, that make it a distinct and complete function in itself. The 3 tenets of people, process, and technology significantly transform to form data engineering practice to amplify the business value of analytics.
Most organizations typically approach data engineering using the traditional software engineering practices that they have established internally. This could adversely impact the business outcomes. Data engineering has a different development and training process. A regular software engineer can’t be just asked to perform the role of a data engineer.
### Data lifecycle management
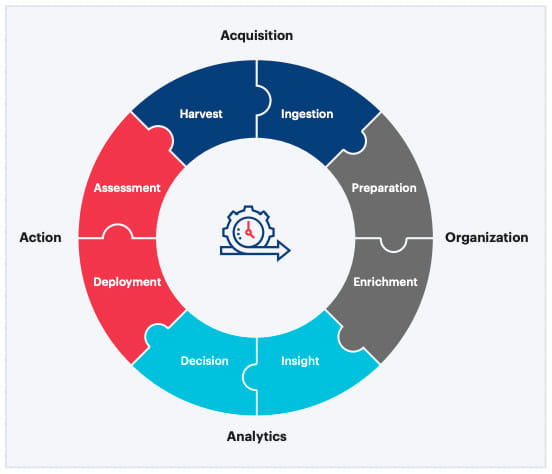
Fig. 3: The Data Processing Cycle
Driven by the three core tenets, a typical data engineering lifecycle focuses on acquiring necessary data, organizing it, making it available for analyses, and subsequently deriving insights.
### Organization
Preparing the acquired data involves using various tools to improve data. Common improvement parameters or indicators include:
- Data integrity
- Latency
- Accuracy
- Consistency
The objective of this exercise is to make the data ready for further analysis and involves various operations such as supplementing metadata, data correlation, data munging, and application data security strategy.
The next stage of the data preparation process in data engineering life cycle involves making the data more insightful by focusing on context. This includes various operations like data labeling and data modeling.
Another critical data engineering functionality is creation and [management of cloud databases](/cloud-migration/) and storage systems like data lake, and enterprise data warehouses. Database-centric data engineering functions such as these are focused on populating analytics databases. In fact, data standardization, preparation, and enrichment are some of the earliest stages of this process. Once the data has been extracted and modified and reformatted, it is loaded into the data warehouse.
### Analytics and action
Once the data has gone through these stages, it is ready to be visualized and analyzed. This marks the shift from observational data to actionable information. The first stage of this process is data insight which essentially refers to understanding data through analysis. This can be either real-time, interactive, or batch. Finally, the results of the data insights stage are used to drive actions, outcomes, and further assessments.
One critical aspect of data engineering that serves as a natural requirement across every stage of data processing is data governance. It is the process of managing the availability, integrity, security, and usability of data within internal systems on the basis of internal data policies and standards that control data usage. A well-thought-out data governance plan can help companies ensure that data is reliable and trustworthy across channels and is not misused.
Over time, efficient data governance has become a defining factor of a [successful data strategy](/data-strategy/), considering how important it is for organizations to comply with stringent data control and privacy regulations.
### The tools of the trade
The data engineering process is a complex and intricate affair and requires several tools to store and manipulate data. However, there is no one tool that can get the complete job done. The process, therefore, requires a combination of data engineering tools and technologies that need to be used either simultaneously or sequentially to get the desired results. Some of the different types of tools needed to develop a data pipeline include:
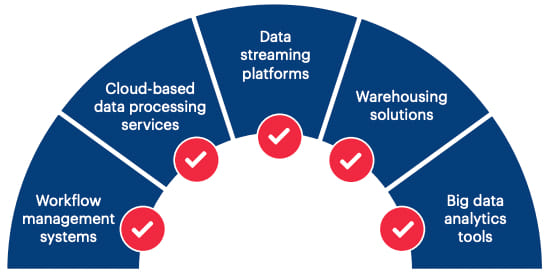
### A holistic approach for data engineering initiatives
Essentially enterprises need to adopt an integrated platform for end-to-end data engineering initiatives instead of stitching together piecemeal solutions aligned to separate processes. To achieve this, an approach such as the one below can help.
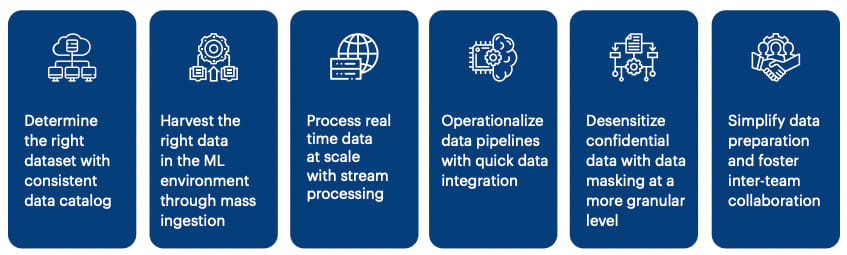
### Leverage high quality insights for effective enterprise data management
[lc_get_post post_type="lc_block" slug="whitepaper-middle-contact-form"]
## 6. Building a winning data engineering team
Till the last few years, companies solely focused on building data science teams, however, there is a new impetus to data engineering. Earlier, data engineering would typically refer to data warehousing and executing run-of-the-mill DBMS functions. Over time, however, data engineers had to evolve and [gain skills](/blogs/10-must-have-skills-for-data-engineering-jobs/) in areas that were not considered part of the traditional data engineering job. These included information security, software development lifecycle (SDLC) management practices, [data architecture](/ebooks-whitepapers/modern-data-architecture-data-lake/), and overall business domain knowledge. They also need advanced programming skills to build systems for continuous and automated data exchange.
The increasing complexity associated with the ‘data boom’ means that going forward deriving insights will require more than just applying a set of rudimentary algorithms and depending on basic analytical principles. Organizations will have to clearly demarcate roles in every aspect of the data management process be it engineers or scientists to ensure that data is managed efficiently and used appropriately. It’s safe to say that data engineers will continue playing a critical role in this process, developing and implementing more advanced technologies that will foster a truly data-driven future.
Furthermore, data engineering involves complexities that go beyond the realm of software engineering:
Systems response: There is a need to understand how different data systems behave differently as they scale. Two software behaving exactly the same way on small-scale data may be completely different as they are scaled.
Training costs: Training engineers to scale systems on cloud and fast-evolving technologies to manage data is a costly affair.
Math: As data engineers work closely with data scientists, the ability to understand data and analyze it statistically is critical.
Algorithms complexity: Algorithm written on 1 TB data of O(n) complexity may complete in 1 day whereas O(n^2) may take 1 month and cost 30x more.
Open source technologies: Technologies are evolving swiftly and new open-source and cloud projects enter the ecosystem. On a monthly basis. Data engineers need to be trained on the latest tech stack to deliver high-impact business solutions.
The fundamental responsibility of a data engineer ultimately boils down to delivering clean, accurate, usable, and methodically governed data. This is what differentiates a data engineer from a software engineer – for the latter, their product is the software, whereas, for a data engineer, the product is data. The roles may apparently seem to overlap from a functional standpoint, and this is the major reason why companies sometimes end up working with traditional IT firms on data projects and eventually run into issues.
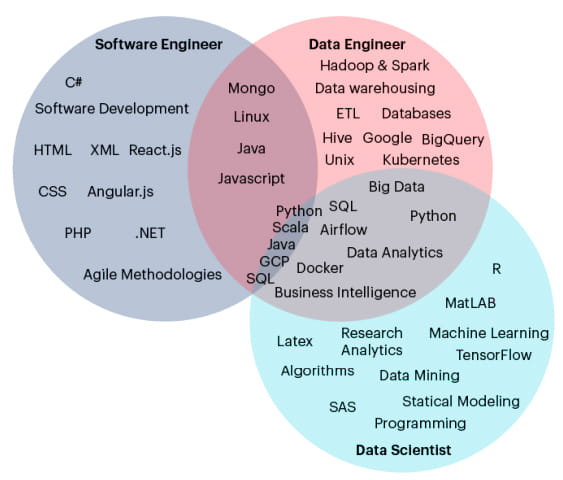
Figure 4: Skill comparison between software engineers, data engineers and data scientists (Adapted from www.ryanswanstrom.com)
### Some of the key differences between data engineering and software engineering are:
Software engineering
Data engineering
Design of software, development of operating system and apps, back/front end development
Advanced data infrastructure, data pipelines, distributed computing, concurrent programming
Build first, iterate later
Problem formulation drives refinement of the use case
Largely driven by agile development framework
Agile along with speed and scalability as pillars of process
Data pipelines and infrastructure management are not always flexible to manage change in data volume
Scalable architecture to manage change in data volume
Focus on architecture and coding
Focus on accurate data availability
Testing is fairly straightforward
Testing is more complex as data changes daily
Traditional development process and training
Knowledge of multiple skills & technologies is a must
## Looking for reliable data management solution?
[lc_get_post post_type="lc_block" slug="whitepaper-middle-contact-form"]
## 7. Bolstering data engineering with DataOps
With time, the number of data pipelines maintained by an organization has grown by leaps and bounds owing to increased demands from data engineers, data scientists and data-heavy applications. This has resulted in data silos that are seldom integrated with other pipelines, data producers or data sets. Since the data resides across various systems and platforms, gaining access and control over it becomes a daunting task.
[DataOps](/blogs/dataops-things-you-need-to-know/) overcome these data engineering challenges and deliver analytics with agility and speed while ensuring data quality. Deriving inspiration from Lean Manufacturing, DevOps and Agile practices, DataOps stresses collaboration, communication and automation between processes involving [data engineers/ETL engineers](/blogs/5-tips-for-preparing-resume-for-a-data-engineering-interview/), data analysts, data scientists and IT. It essentially focuses on getting clean, usable insights by leveraging the interdependencies within the entire analytics chain.
A DataOps enabled process utilizes workflow automation and toolchain to capture data at its source while feeding downstream systems for models, reports and visualization. In a data production environment, DataOps can directly exploit existing tests, logics and workflows to ensure optimum data quality.
## Build highly available & scalable AI/ML systems that stand the test of time
[lc_get_post post_type="lc_block" slug="whitepaper-middle-contact-form"]
## Conclusion
Data engineering enables data consumers across the organization with clean, quality data they can trust, allowing them to drive better business insights and actions. As enterprises look to modernize their data and analytics environment, data engineering is on the rise.
Apart from setting up a data science team, companies should focus on building a strong data engineering foundation, as they are poised to play a critical role in helping organizations derive value out of their data at scale. As businesses continue to integrate various types of data in order to make informed decisions, the need for the right insights delivered to the right people at the right time is ever-growing.
The emergence of data engineering as a specialized skill has allowed organizations to collect, store, transform, and classify data and make the most out of their AI-ML projects. Going forward, the organizations that intend to drive successful and impactful data initiatives will invariably have to integrate their data management strategy with a dedicated data engineering team or work with external specialists.
## References
1 Understanding Challenges and Opportunities in Data Management: https://www.dnb.com/perspectives/master-data/data-management-report.html
2 Winning With AI: https://image-src.bcg.com/Images/Final-Final-Report-Winning-With-AI-R_tcm21-231660.pdf
3 Accelerating AI with Data Management; Accelerating Data Management with AI: https://www.ibm.com/downloads/cas/YD5R1XLB
4 How Companies Learn Your Secrets: https://www.nytimes.com/2012/02/19/magazine/shopping-habits.html?pagewanted=1&_r=1&hp
5 https://hbr.org/2006/01/competing-on-analytics – HBR article – ‘Competing on analytics
6 Amount of information globally 2010-2024: https://www.statista.com/statistics/871513/worldwide-data-created/
[lc_get_post post_type="lc_section" slug="transform-data-common-footer-cta"]
---
## Navigation
- [WordPress.org](https://wordpress.org/)
- [Documentation](https://wordpress.org/documentation/)
- [Learn WordPress](https://learn.wordpress.org/)
- [Support](https://wordpress.org/support/forums/)
- [Feedback](https://wordpress.org/support/forum/requests-and-feedback)
- [Sigmoid](https://www.sigmoid.com/)
- [Community](https://community.wpmanageninja.com/portal/space/fluent-forms/home)
- [Docs](https://wpmanageninja.com/docs/fluent-form/)
- [Developer Docs](https://developers.fluentforms.com/)
- [Documentation](https://imagify.io/documentation/)
- [Rate Imagify on WordPress.org](https://wordpress.org/support/view/plugin-reviews/imagify?rate=5#postform)
- [Manage](admin.php?page=litespeed)
- [Settings](admin.php?page=litespeed-cache)
- [Image Optimization](admin.php?page=litespeed-img_optm)
- [Company](/about-sigmoid)
- [Newsroom](/newsroom)
- [Life at Sigmoid](/careers)
- [Takshashila](/takshashila)
- [Contact Us](/contact-us)
- [AI Strategy Blueprint your AI advantage](/enterprise-ai-strategy/)
- [Generative AI Drive innovation with Generative AI](/generative-ai/)
- [Responsible AI Build trust with ethical AI practices](/responsible-ai-in-enterprise/)
- [Agentic AI Reshape business with scalable agentic systems](/agentic-ai-solutions/)
- [AI Managed Services Ensure reliable AI performance](/ai-managed-services/)
- [Advanced Analytics Transform your business with data-driven insights](/advanced-data-analytics-solutions/)
- [Start Assessment](/agentic-ai-readiness-index/)
- [Data Strategy Strong data foundations for scalable AI](/data-analytics-strategy/)
- [Data Management Leverage data as a strategic asset](/ai-data-management-services/)
- [Data Ops Automate data for speed and quality](/data-devops/)
- [Data Engineering Deliver insights faster with scalable pipelines](/data-engineering/)
- [Cloud Transformation Modernize data to maximise efficiency](/cloud-migration/)
- [Download Whitepaper](/ebooks-whitepapers/building-data-products-in-a-data-mesh-to-drive-business-value/)
- [Data Modeling Structure data for better decisions](/data-modeling-services/)
- [Data Visualization Transform data into actionable stories](/data-visualization-service/)
- [BI Migration Enhance decision making with modern BI tools](/bi-migration/)
- [Data Observability Build trust with healthy, accurate data](/data-observability/)
- [Automated Insights Make smarter decisions with auto-generated insights](/automated-insights/)
- [Download Whitepaper](/ebooks-whitepapers/power-bi-hacks/)
- [CPG & Retail End-to-end analytics for planning, operations, and commercial excellence](/industries/cpg-analytics/)
- [Life Sciences Trusted intelligence across clinical, commercial, and operational workflows](/industries/life-sciences/)
- [Financial Services AI-powered analytics for risk, compliance and customer experience](/industries/banking-financial-analytics-services/)
- [Read case study](/case-studies/data-clean-room-enables-real-time-insights-to-improve-operational-efficiency/)
- [MediaIQ Advanced platform for in-flight marketing measurement](/accelerators/sigmoid-mediaiq-multi-touch-attribution-tool/)
- [CampaignIQ AI-driven platform for optimized campaign budget allocation](/accelerators/sigmoid-campaigniq/)
- [AssistBot GenAI email assistant that automates human-like responses](/accelerators/sigmoid-assistbot-for-ai-email-assistant/)
- [CreativeBot GenAI tool for personalized and brand-aligned creative design](/accelerators/sigmoid-creativebot/)
- [SocialBot GenAI platform to analyze digital conversations and trends](/accelerators/#marketing|socialbot)
- [DemandIQ Predict trends accurately and optimize inventory management](/accelerators/sigmoid-demandiq/)
- [NetworkIQ Track and optimize logistics operations in real-time to quickly address disruptions](/accelerators/sigmoid-networkiq/)
- [SupplyIQ End-to-end platform to optimize supply chain operations](/accelerators/sigmoid-supplyiq/)
- [ProcurementIQ Automated procurement operations for maximum savings, compliance and efficiency](/accelerators/sigmoid-procurementiq/)
- [RapidML Accelerated deployment for machine learning models](/accelerators/sigmoid-rapidml/)
- [DataGuard Comprehensive platform for proactive data quality management](/accelerators/data-quality-tool-sigmoid-dataguard/)
- [CloudPulse Cloud cost optimization platform with multi-cloud management](/accelerators/sigmoid-cloudpulse/)
- [RAPID GenAI foundation with built-in governance and cost clarity](/accelerators/sigmoid-rapid/)
- [AnalyticsBot GenAI based platform to streamline decision-making in analytics](/accelerators/sigmoid-analyticsbot/)
- [DataConnect Seamlessly ingest, integrate and harmonize data from diverse sources](/accelerators/sigmoid-dataconnect/)
- [Reconica AI-powered data harmonization and reconciliation engine](/accelerators/sigmoid-reconica/)
- [ConverseBot GenAI driven insights generation for automated insights from reports](/accelerators/#sales|conversebot)
- [iNRM Cross-lever revenue growth optimization platform](/accelerators/sigmoid-inrm/)
- [AssortmentIQ Optimize shelf layouts and assortment mix at scale with AI-based insights](/accelerators/sigmoid-assortmentiq/)
- [Read Whitepaper](/ebooks-whitepapers/building-agentic-ai-chatbots-for-business-process-transformation/)
- [Listen Podcast](/events/podcast/how-jack-in-the-box-is-redefining-personalization-and-supply-chain-with-ai/)
- [Blogs](/blogs/)
- [White Papers](/ebooks-whitepapers/)
- [Case Studies](/case-studies/)
- [Podcast](/events/podcast/#Podcasts)
- [Read Blog](/blogs/the-genai-adoption-triad-responsibility-ethics-and-explainability/)
- [ConverseBot](/accelerators/#sales|conversebot/)
---
## Footer Links
- [Talk to our AI experts](/contact-us/)
- [AI Strategy](/enterprise-ai-strategy/)
- [Agentic AI](/agentic-ai-solutions/)
- [Generative AI](/generative-ai/)
- [AI Managed Services](/ai-managed-services/)
- [Responsible AI](/responsible-ai-in-enterprise/)
- [Advanced Analytics](/advanced-data-analytics-solutions/)
- [Data Strategy](/data-analytics-strategy//)
- [Data Engineering](/data-engineering/)
- [Data Management](/ai-data-management-services/)
- [Cloud Transformation](/cloud-transformation/)
- [Data Ops](/data-devops/)
- [Data Visualization](/data-visualization-service/)
- [Automated Insights](/automated-insights/)
- [BI Migration](/bi-migration/)
- [Data Modeling](/data-modeling-services/)
- [Data Observability](/data-observability/)
- [CPG & Retail](/industries/cpg-analytics/)
- [Financial Services](/industries/banking-financial-analytics-services/)
- [Life Sciences](/industries/life-sciences/)
- [Case Studies](/case-studies/)
- [Thought Leadership](/ebooks-whitepapers/)
- [Blogs](/blogs/)
- [Company](/about-sigmoid/)
- [Newsroom](/newsroom/)
- [Accelerators](/accelerators/)
- [Careers](/careers/)
- [Privacy Policy |](/privacy-policy/)
- [Cookie Policy](/cookie-policy/)