Modernizing enterprise data management with DataOps
1. Introduction
DataOps transpires as one of the key dominators in constructing data and analytics pipelines in fulfilling rapid business needs. Latest reports suggest that globally almost 60% of enterprises harness data analytics directly or indirectly to unlock varied business opportunities. To top it up, 49% of respondents from another leading survey suggested enhanced decision-making with data analytics.
It’s clear that enterprises today are embracing data as a highly valuable resource to drive long-term business benefits – from unlocking the business value to improving the bottom line. However, there’s still some way to go before data analysis becomes ubiquitous. And, even the organizations trying to leverage data analytics often face substantial challenges in instituting data-enabled workflows. The guidebook explains how DataOps can overcome these challenges starting from the basics.
2. DataOps Vs DevOps – The differences
In essence, DevOps is a set of practices that emphasizes process automation for different teams including software development, IT, operations, and quality assurance. DevOps enables the teams to easily and efficiently complete their tasks including design infra, coding practices, testing, delivery, deployment, security, performance tracking and monitoring.
DataOps can be described as a form of DevOps that includes data analysis and empowers businesses in the creation of processes that meet user needs throughout the life cycle of any data usage.
Some of the key differences between DevOps and DataOps are indicated below:
| Parameter | DevOps | DataOps |
|---|---|---|
|
Quality component |
The primary objective of DevOps is to create an end product or software which ticks all the quality parameters. Devops as a service achieves this by shortening development cycles and removing development bottlenecks. |
The primary objective of DataOps is to ensure that quality data enters the data pipeline and trusted, highquality insights are generated through continuous data validation at each point of the data pipeline. |
|
Orchestration cycle |
The DevOps process doesn’t essentially require complex orchestration of application codes. |
For seamless execution of the DataOps process, data teams need to ensure that both data pipeline and analytics development processes are seamlessly orchestrated. |
|
Agile capabilities |
DevOps facilitates frequent deployments and quick recovery in case of any deployment failures. |
Reduction in time to identify metadata and marked improvement in data quality. |
|
Delivery automation |
|
|
|
Testing cycles |
The testing cycle in DevOps spans the entire application development and deployment cycle. The testing phases include performance testing, operations testing and security testing. |
In the DataOps process, the testing covers both the data pipeline and the analytics development process. These tests help detect data anomalies, erroneous data volumes and ensure that fresh analytics is validated before deployment. |
|
Operating environment |
Stakeholders are assisted in providing real-time feedback post each sprint with real-time collaboration Optimization is feedback oriented. |
Stakeholders are assisted in deriving insights from new data flowing into the system with real-time collaboration. Optimization is result-oriented. |
3. Data infrastructure challenges faced by enterprises
An organization may face a host of challenges in building data pipelines and streamlining data analytics. The associated challenges may be based on proprietary choices, cloud and edge computing-related challenges, structural challenges, and many others.
Technology selection for data pipeline development:
On an application level, DataOps pipeline building can be approached in two ways – through a DIY approach using open-source platforms or using proprietary commercial products. Using open-source has its advantages in terms of flexibility and availability as open-source licenses give users the freedom of changing the programs. However, this translates to an increased workload for data engineers where they need to handle multiple data sources, essential features, protocol support, permission management, and more.
On the other hand, proprietary products may be cost-intensive due to excessive licensing costs based on connector fees or data ingestion rates. Also scaling them on operational levels can be challenging as well when operating on a multitude of similar data pipelines. However, there are obvious operational benefits with simplified governance, management, and security.
Multiple data sources:
Another pertinent challenge towards DataOps implementation is with data management from multiple data locations. Today, business data often moves around an increasingly diverse ecosystem consisting of multi-cloud and edge. This can perhaps explain why only 32% of available enterprise data is utilized while more than two-thirds remain unleveraged. Moreover, it is estimated that by 2025, close to 80% of all enterprise data (up from 35% in 2015) will be stored in core and edge, requiring enterprises to focus on edge data management to bring analytics into play. And, as more and more data is created outside the traditional data centers, the cloud will gradually extend to the edge, altering the paradigm to “cloud and edge” instead of “cloud vs edge”. This data boom over time would soon warrant automation in data management.
Legacy systems and processes:
Other than this, legacy organizational systems and processes often serve as an obstacle in seamless data usage. Organizational data teams face constant interruptions with data and analytical errors. It is estimated that data scientists spend almost 75% of their time preparing data and executing manual steps. This is further exacerbated by a siloed organizational structure that hinders collaboration between groups and leads to overall lengthier analytics cycle time.
The challenges can often be daunting and deter an organization from utilizing valuable business data as a source of insight. Several other factors including process bottlenecks, rigid data architectures, wait time for approvals, technical debt from previous deployments, data discrepancy & data deduplication and more are also at play.
Considering this plethora of challenges, organizations need to rethink their data strategies and approaches radically. An integration of data workflow and processes that enables rapid implementation of ideas and quick execution of higher quality models and analytics will be required to integrate high-quality data analytics into the regular workflow. Here, one of the first steps is to understand data governance and how to orchestrate it.
4. How can DataOps create a difference?
DataOps applies management and analytic processes across the entire data lifecycle and optimizes the performance of each step (from ingestion to analysis) of the data pipeline. With DataOps, several DevOps concepts are blended in with data engineering to provide organizational structures, tools and processes to the data-focused enterprise. Due to its inherent nature and practices, DataOps helps organizations counter the prime challenges related to institutionalizing data focused workflows.
DataOps developers have constantly designed solutions focused on the ever-growing data needs of enterprises. With rising capabilities, advantages keep emerging too. Owing to its inherent benefits, DataOps solves the most pertinent challenges organizations face in terms of implementing data workflows. The most common and overarching benefits include:
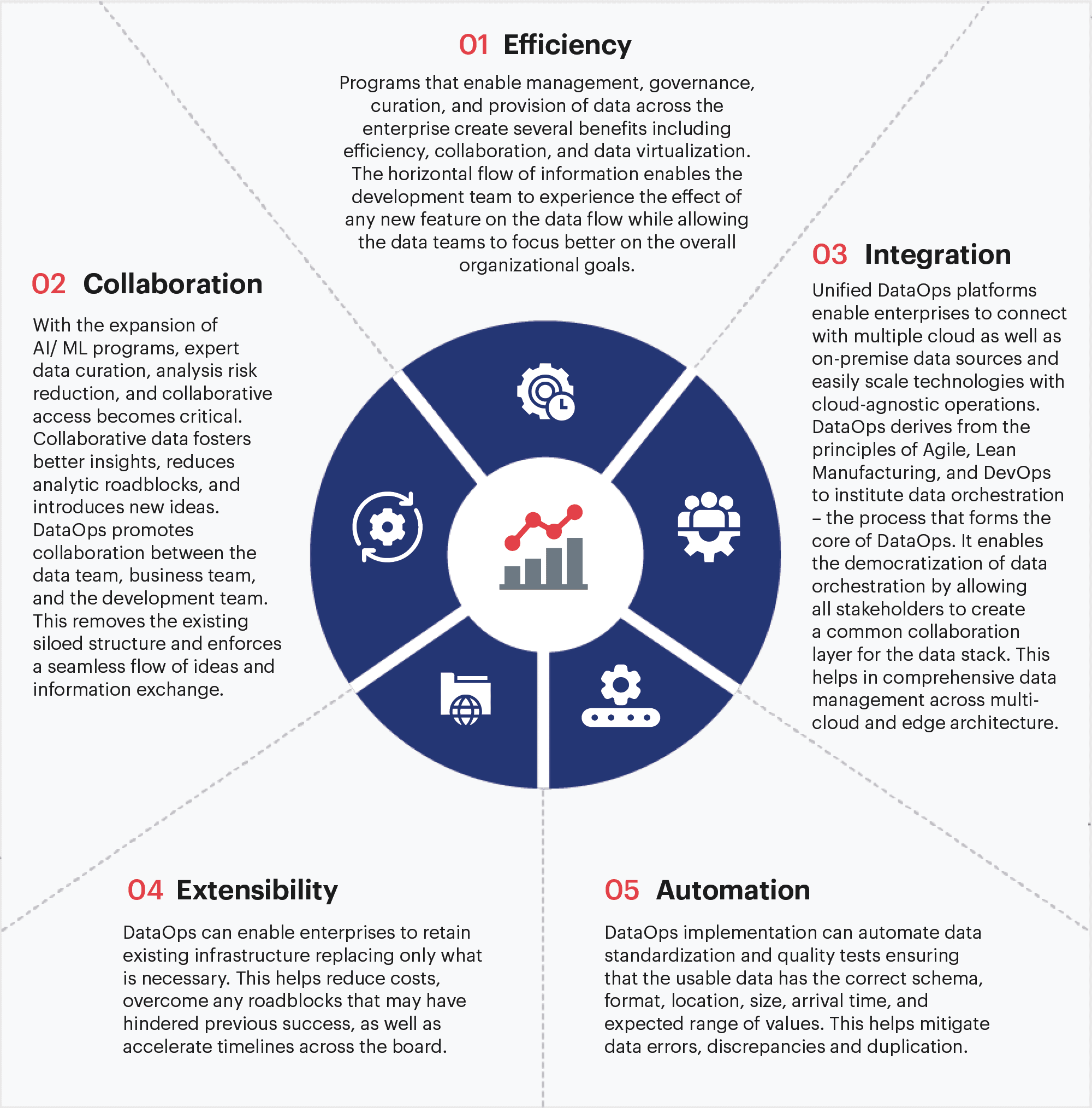
Empower business teams with insights from high quality data
5. How to implement a successful DataOps strategy?
As evident, migrating to DataOps would be prudent for most future-facing enterprises looking to leverage their data resources. DataOps utilizes specialized teams with goal-oriented processes similar to agile development. For organizational analytics teams, migrating to a DataOps structure is akin to any major change management and it includes enterprise-wide involvement and partaking. Once all stakeholders are aligned, the technicality of the change involves the execution of the below-mentioned steps:
- Automating the process to validate the source/upstream data as per business requirements
- Automating the process to check all data were ingested in the pipeline
- Validating the data at each point of the pipeline or sub part of the outline
- Automating the reprocessing mechanism to run the sub part of the pipeline that has the corrupted data
- Setting up a visualization dashboard to monitor the pipeline behavior
- Automating the final validation process where input and output data were compared on the basis of business logic
- Implementing alert and monitoring checks on data values throughout the pipeline
6. Automating data pipelines
As development teams expand, data pipelines grow in complexity. To maintain process efficiency, organizations need to standardize data flow between different steps of the data lifecycle. Being central to running a data-driven business, DataOps leverages continuous testing, monitoring, containerization, orchestration, and collaborative development to enable the automation of data pipelines and ultimately improve data quality and accelerate data output.
DataOps breaks down every part of an existing pipeline into several mini pipelines. This creates the opportunity to automate and orchestrate individual tasks within the mini pipelines. The standardization of the individual parts further enhances the interoperability of new pipelines reducing the need for insecure workarounds. In such an environment, agile methodologies can be safely applied to ensure continuous data refinement prior to proceeding to the next stages. The adoption of DataOps also automates data preparation and enables deployment of data catalogs.
7. Enterprise data governance with DataOps
DataOps introduces operations agility to data analytics in order to enable the cohesion of data teams and users. This results in the higher efficiency and efficacy levels of the data operations. Under this paradigm, the data teams publish either new or updated analytics in sprints or short increments. This enables the team to continually reassess its priorities and adapt to ever-evolving requirements based on constant user feedback.
Agile development techniques are especially useful in accelerating the time to value and offer rapid response to customer requirements in the context of data pipelines as the requirements are constantly evolving. At the same time, DataOps also helps organizations govern the comprehensive workflow processes associated with data analysis – from data ingestion, to transformation,all the way to analysis and reporting.
Data governance
Data Governance is a quintessential part of Sigmoid’s digital analytics strategy. It includes working with stakeholders to identify compliance, security, and privacy standards to be followed in support projects. The process begins with an initial scoping that aims at understanding the current system and a detailed component-by-component action plan to improve the general availability of the system.
As such, data governance frameworks support an organization’s strategy to manage data. From data collection, management, security, and storage, data governance frameworks cover end-to-end enterprise data life-cycle. An effective data governance framework must account for:
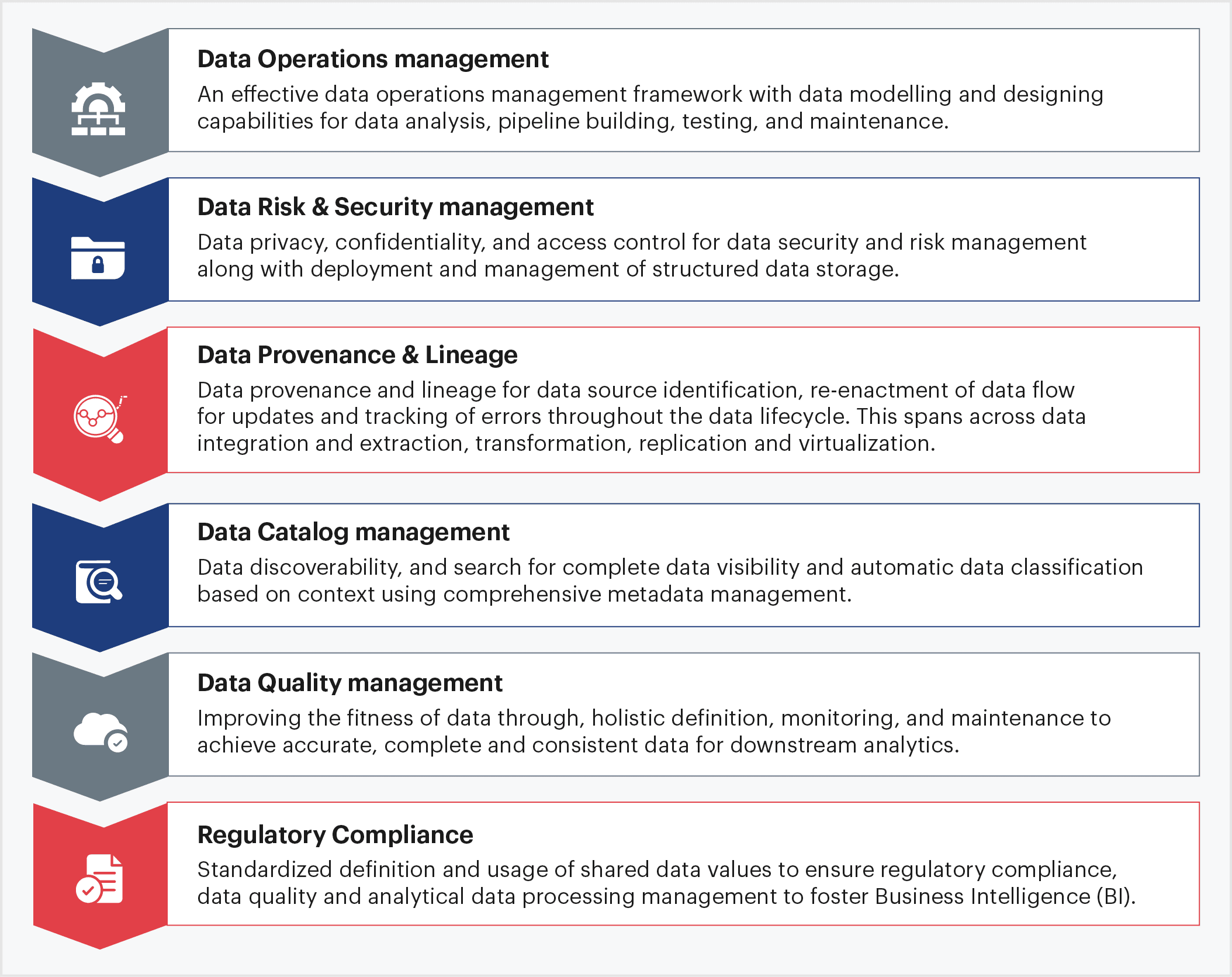
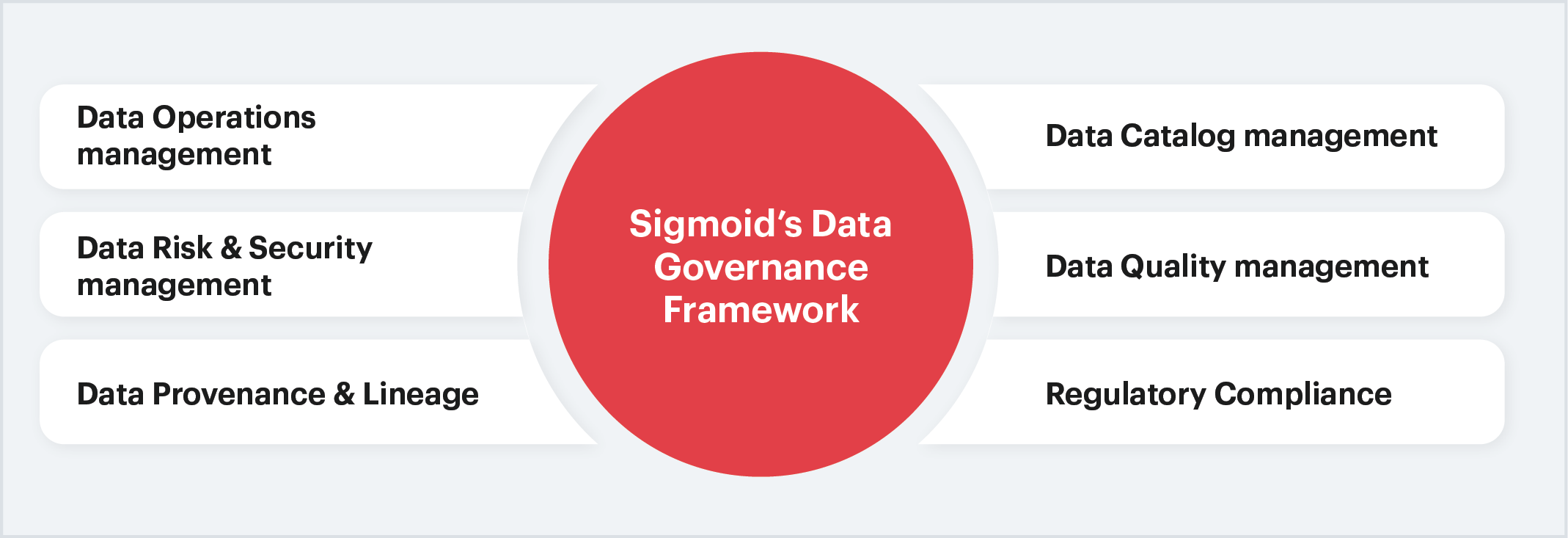
Sigmoid’s Approach to Data Governance
It is important to note that, in many cases, data teams slow down the data pipeline to solve governance and related issues. Sigmoid’s process ensures that this common practice is avoided.
Conclusion
It is evident that enterprises today must embrace DataOps to channelize data across their organizational workflow. However, a well thought out strategy is to be set in place while planning the data journey to align with both long term and short term goals. In this direction, implementing DataOps to institute effective Data Governance must be considered in conjunction with strategic partners. Leveraging the expertise of experienced transition partners can ensure that bespoke action strategies are formed based on organization-specific conditions, plans, and requirements.
Organizations that can successfully embark on DataOps based data journeys stand to gain long-term in the form of operational agility, better governance, and substantially more informed decision-making. This assures they remain competitive and relevant in the face of present challenges while gearing up to be resilient and thriving in the future.
About the author
Jagannath is an Enterprise DataOps Architect at Sigmoid with vast experience in architecting and implementing data solutions for businesses on AWS, GCP and Azure.
He is instrumental in maintaining and supporting highly critical data systems for clients across CPG, Retail, AdTech, BFSI, QSR and Hi-Tech verticals.