5 best practices for deploying ML models
Reading Time: 5 minutes

In our previous article – 5 Challenges to be prepared for while scaling ML models, we discussed the top five challenges in productionizing scalable models of Machine Learning. Our focus for this piece is to share the best practices for deploying ML models in production successfully.
ML models today solve a wide variety of specific business challenges across industries. There have been many examples for machine learning model deployment solving business use cases across industries. However, in this case we would look into an approach to build ML models that are produtionizable.
To begin with, the right risks have to be eliminated early off in the production process. Eliminating a higher number of risks at earlier stages of the model selection & development leads to lesser rework during the productionizing stage.
Sigmoid’s pre-webinar poll showed that 43% of companies find ML productionizing and integration challenging.
The various considerations involved in a machine learning ecosystem are — data sets, a technology stack, implementation and integrating these two, and teams who work on deploying ML models. Then comes the resilient testing framework to ensure consistent business results.
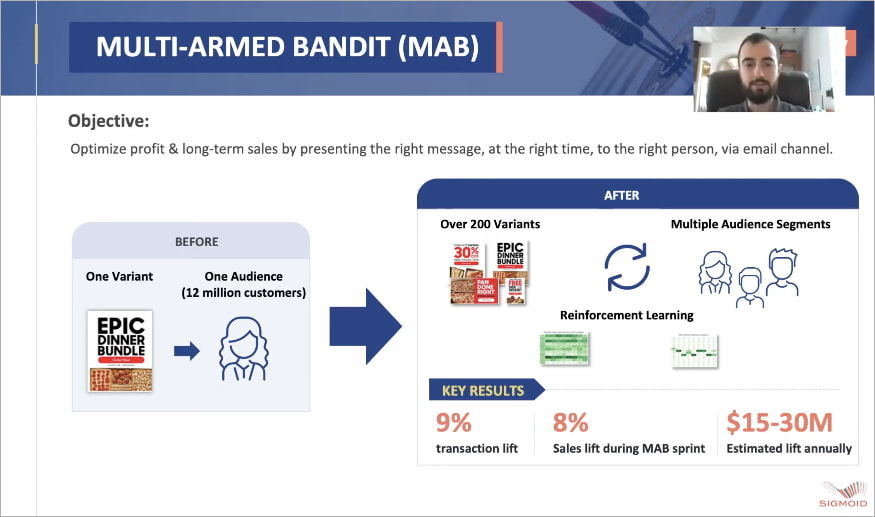
Using the best practices given below Yum! Brands were able to achieve an 8% sales uptick by productionizing their MAB models for personalized email marketing. Watch the 2 min video where Yum’s Scott Kasper explains the impact of the best practices in productionizing their MAB models
Here are the 5 best practices for deploying ML Models
1. Data Assessment
To start, data feasibility should be checked — Do we even have the right data sets to run machine learning models on top? Do we get data fast enough to do predictions?
For example, restaurant chains(QSRs) have access to millions of registered customers’ data. This sheer volume is enough for any ML model to run on top of it.
When the above data risks are mitigated, a data lake environment with easy and powerful access to a variety of required data sources should be set up. A data lake (in place of traditional warehouses) would save the team a lot of bureaucratic and manual overhead.
Experimentation with the data sets to ensure that the data has enough information to bring about the desired business change is crucial at this step. Also, a scalable computing environment to process the available data in a fast manner is a primary requirement.
When the data scientists have cleaned up, structured, and processed the different data sets, we strongly advise cataloging the data for leveraging in the future.
In the end, a strong and well-thought governance and security system should be put in place so that different teams in the organization can share the data freely.

2. Evaluation of the right tech stack
Once the ML models are chosen, they should be run manually to test their validity. For instance, in the case of personalized email marketing – Are the promotional emails that are being sent bringing in new conversions or do we need to rethink our strategy?
Upon successful manual tests, the right technology has to be chosen. The data science teams should be allowed to choose from a range of technology stacks so that they can experiment and pick up the one that makes ML productionizing easier.
The technology chosen should be benchmarked against stability, the business use case, future scenarios, and cloud readiness. Gartner states that cloud IaaS is projected to grow at 24% YoY until 2022.
Watch the 1 min video where Mayur Rustagi (CTO & Co-founder – Sigmoid) talk about proven ways to approach infrastructure components selection
3. Robust Deployment approach
Standardizing the deployment process so that the testing, integration, and training of ML models at different points become smooth is highly recommended.
Data engineers should focus on polishing the codebase, integrating the model (as an API endpoint or a bulk process model), and creating workflow automation such as smooth ML pipeline architecture so teams can integrate easily.
A complete environment with access to the right datasets and models is essential for any ML model’s success.
4. Post deployment support & testing
The right frameworks for logging, monitoring, and reporting the results would make the otherwise difficult testing process manageable.
The ML environment should be tested in real-time and monitored closely. In a sophisticated experimentation system, test results should be sent back to the data engineering teams so that they can train the ML models at scale.
For example, the data engineers can decide to overweight the variants that over-perform in the next iteration while underweighting the underperforming variants.
Negative or wildly wrong results should also be watched out for. The right SLAs need to be met. The data quality and model performance should be monitored.
The production environment would thus slowly stabilize.
5. Change management & communication
Every ML model’s success hugely depends on clear communication between the various cross-functional teams involved so that risks are mitigated at the right step.
Data engineering and data science teams would have to work together to put an ML model into production. Data scientists are advised to have full control over the system to check in code and see production results. Teams might even have to be trained for new environments.
Transparent communication would save everyone effort and time in the end.
Conclusion:
In addition to all the above best practices in place, the machine learning model should be designed to be reusable and resilient to changes and drastic events. The best-case scenario is not to have all the recommended methods in place but to make specific areas mature-enough and scalable so that they can be calibrated up and down as per the time and the business requirement.
Please email us if you have any further questions on putting Machine Learning models into production. For the full webinar recording on “Productionizing ML models at scale”, click here.
Featured blogs







Featured blogs