---
# Microservices-based architecture: Key to scaling enterprise ML models
**URL:** https://www.sigmoid.com/blogs/microservices-based-architecture-key-to-scaling-enterprise-ml-models/
Date: 2021-03-03
Author: Sigmoid
Post Type: post
Summary: The last decade has seen wholesome innovations in the field of artificial intelligence and machine learning (AI/ML). Today, progressive enterprises are increasingly...Read More...
Categories: MLOps
Tags: AI/ML, Cloud Transformation, Data Management
Featured Image: https://www.sigmoid.com/wp-content/uploads/2023/10/Microservices-based-Architecture-Key-to-Scaling-Enterprise-opt.jpg
---
The last decade has seen wholesome innovations in the field of artificial intelligence and machine learning (AI/ML). Today, progressive enterprises are increasingly leveraging ML models to drive operational growth through actionable decision-making. In the ML space, an important area of evolution has been [MLOps](/machine-learning-operationalization-mlops/) – a set of practices that help companies synergize ML, [DevOps](/industries/banking-financial-services/), and data engineering to seamlessly deploy ML models and reliably maintain ML systems.
Even when ML has gained significant popularity in helping organizations address operational gaps, there’s still a challenge when it comes to [deploying ML models](/ebooks-whitepapers/ml-models-poc-to-production/) to the production environment. The major obstacle that companies face here is the constantly changing training data sets. Using prebuilt offline models to develop practical applications can often turn out to be a tricky affair as organizational data is always evolving. In order to add new data sets to an existing application, data teams need to rebuild data models from the scratch, freshly compute scores and deploy new models without impacting the production environment. It is here where a microservices architecture can serve as a natural solution enabler helping companies achieve seamless data integration without disrupting the existing production environment.
Microservices architecture can serve as a natural solution enabler helping companies achieve seamless data integration without disrupting the existing production environment. In this blog we will discuss how microservice deployment can help companies with productionizing ML models.
## Microservices: Helping Companies Efficiently Deploy, Productionize, and Scale ML Models
Research reveals that there has been a tremendous increase in microservices deployment, and the market is expected to grow exponentially over the next decade. The global market of microservices architecture is projected to be worth $8.07 billion by 2026, up from $2.07 in 2018, growing at a healthy CAGR of 18.6%. With both the microservices architecture and MLOps on ascendancy, combining the concepts promise to bring ML success to enterprises that are envisioning a future that relies on fast application deployment, seamless operations, and agile development.
The architecture to develop and deploy machine learning models has a telling impact on its success. The ML model lifecycle ideally has four key components, which are:
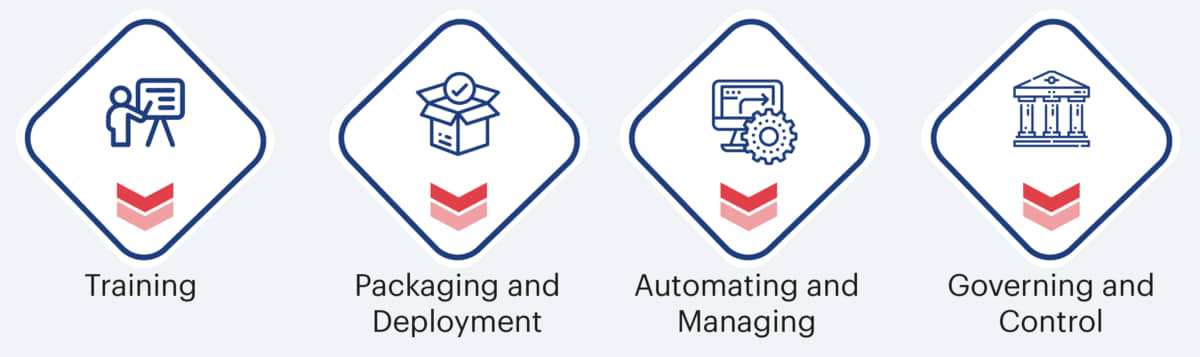
The microservices-based architecture helps create a robust [ML model lifecycle](/blogs/5-best-practices-for-putting-ml-models-into-production/), which ensures mitigation of challenges arising from underutilization and mismanagement of [data scientists](/data-science-services/) and [data engineers](/data-engineering/), fragmented communication, and siloed operations. Also, microservices-based architectures make ML models more intuitive for the users, thereby increasing productivity and improving the customer experience.
Another key element of [microservices-driven](/blogs/9-things-you-need-to-know-about-microservices/) MLOps is going serverless, which is crucial for automating container development, auto-scaling of workflow, and improved visibility and monitoring. To build automated ML pipelines, implementing serverless frameworks and utilizing an open-source tool, such as Kubeflow, is essential. By using Kubeflow pipelines and serverless frameworks, such as MLRun or Nuclio, enterprises can quickly develop and deploy automated ML pipelines without the need to overtly focus on DevOps.
Productionizing ML models has distinctive benefits, and a microservices-based architecture facilitates a product-oriented development and [deployment of the ML model](/blogs/5-best-practices-for-putting-ml-models-into-production/) and offers end-to-end visibility of the process. This approach helps in making the development process both interactive and iterative, resulting in creation of robust, automated, CI/CD-based [ML pipelines](/machine-learning-operationalization-mlops/). In other words, ML pipeline architecture and Kubeflow pipeline are crucial for productionizing ML models and unlocking the complete value of MLOps.
The following are some of the best practices when it comes to facilitating successful MLOps through a microservices architecture:
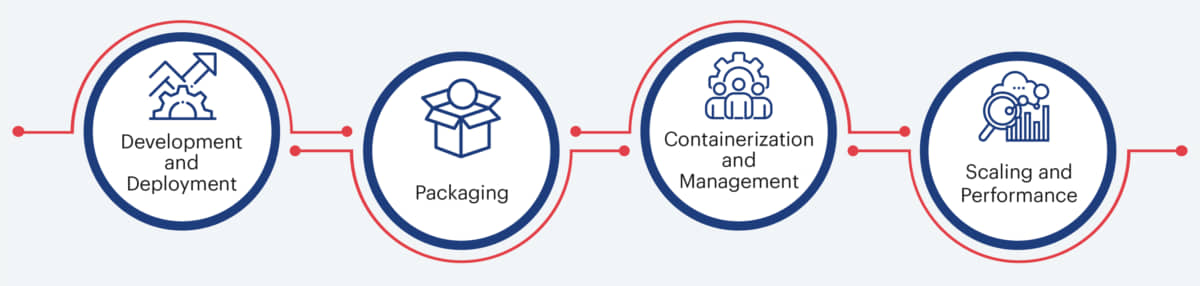
- Development and Deployment: One of the key aspects that define the success of any ML application is how easily the ML models can be developed and deployed. A common approach to ensure that development and deployment of models happen without disrupting the production environment, is to leverage a robust training dataset to create an optimized model offline. This model can then be validated offline against a pre-defined validation dataset and then uploaded to the microservices architecture. Teams can use the main messaging hub in microservices architecture to collate critical feature data from multiple disparate sources on a real-time basis.
- Packaging: Microservices architecture can allow developers to both publish a single ML capability as a standalone microservice or publish an independent application functionality as a microservice with ML capability. In both the cases however, the ML component needs to be managed separately because of complexities associated with processes like data acquisition, model training/development, model update and so on.
- Containerization and Management: In order to integrate the ML algorithm into the delivery IT platform, there are two major steps that needs to be followed. Firstly, REST API has to be integrated with the ML algorithm running behind a particular microservice. The API, run time and algorithm has to be packed in a Docker container. Secondly, all the containers (microservices) will have to be effectively managed and orchestrated. It is here where Kubernetes can help create a difference. Kubernetes can help teams properly categorize containers into compute clusters and ensure that workloads are managed as planned.
- Scaling and Performance: Since cloud and containers serve as the backbone of microservices, scalability and performance become an integral aspect. While selecting and developing different application components, developers should carefully select and finalize databases, runtimes, computing engines and storage on the basis of desired performance and scalability.
## What differentiates Microservices Architecture?
There are several aspects that make microservices architecture an ideal option for big enterprises. When compared to more conventional monolithic architectures, microservices delivers:

Enhanced Fault Isolation: The failure of a single module within microservices doesn’t affect the larger application.
Reduce Technology or Vendor Lock-in: Microservices provides with the much-needed flexibility to implement a new technology stack within an individual service on the basis of the requirement.
- User Friendly: The microservices architecture is user-friendly which helps developers clearly understand service functionality.
- Smaller and Quicker Deployments: The presence of smaller code bases in microservices allows for faster deployments.
- Scalability: Services are separately stacked in a microservices architecture, which allows enterprises to scale them on individually on the basis of requirements.
## Conclusion
Microservices architecture is paramount to enterprise aspirations of creating a robust organizational [MLOps environment](/machine-learning-operationalization-mlops/). It revolutionizes how data is ingested and validated, creates an agile environment for development and deployment, and adds another level of cybersecurity to the entire process. Furthermore, it ensures continued integration and delivery, thereby remarkably reducing time-to-value. With so much to offer, enterprises must quickly turn to microservices deployment from traditional architectures and aim at optimizing MLOps to gain business advantage and create definitive advantages.
## About the author
Shreya is a Data Engineer at Sigmoid who currently works on building Query Engine and ETL pipelines on Spark, BigQuery and was involved in migration of Sigview from monolith to microservices.
[lc_the_tags]
## Featured blogs
[lc_get_posts post_type="post"
posts_per_page="4" orderby="date" output_view="lc_get_posts_mycustom_view" output_number_of_columns="4"
output_wrapper_class="row" output_article_class="shadow" output_hide_elements="Excerpt"
output_excerpt_length="0" output_excerpt_text="Read More" output_heading_tag="span"
output_featured_image_format="thumbnail" output_featured_image_class="card-img-left" ]
## Share
[addtoany]
## Subscribe to get latest insights
## Talk to our experts
Get the best ROI with Sigmoid’s services in data engineering and AI
## Suggested readings
[View all](/blogs/)

#### [Comparison of ML Platforms in an Evolving Market](/blogs/a-critical-comparison-of-the-ml-platforms-in-an-evolving-market/)
[Read blog](/blogs/a-critical-comparison-of-the-ml-platforms-in-an-evolving-market/)

#### [5 Challenges of Scaling Machine Learning Models](/blogs/5-challenges-to-be-prepared-for-before-scaling-machine-learning-models/)
[Read blog](/blogs/5-challenges-to-be-prepared-for-before-scaling-machine-learning-models/)

#### [5 Best Practices for Deploying Machine Learning Models](/blogs/5-best-practices-for-putting-ml-models-into-production/)
[Read blog](/blogs/5-best-practices-for-putting-ml-models-into-production/)
---
## Categories
- MLOps
---
## Navigation
- [WordPress.org](https://wordpress.org/)
- [Documentation](https://wordpress.org/documentation/)
- [Learn WordPress](https://learn.wordpress.org/)
- [Support](https://wordpress.org/support/forums/)
- [Feedback](https://wordpress.org/support/forum/requests-and-feedback)
- [Sigmoid](https://www.sigmoid.com/)
- [Community](https://community.wpmanageninja.com/portal/space/fluent-forms/home)
- [Docs](https://wpmanageninja.com/docs/fluent-form/)
- [Developer Docs](https://developers.fluentforms.com/)
- [Documentation](https://imagify.io/documentation/)
- [Rate Imagify on WordPress.org](https://wordpress.org/support/view/plugin-reviews/imagify?rate=5#postform)
- [Manage](admin.php?page=litespeed)
- [Settings](admin.php?page=litespeed-cache)
- [Image Optimization](admin.php?page=litespeed-img_optm)
- [Company](/about-sigmoid)
- [Newsroom](/newsroom)
- [Life at Sigmoid](/careers)
- [Takshashila](/takshashila)
- [Contact Us](/contact-us)
- [AI Strategy Blueprint your AI advantage](/enterprise-ai-strategy/)
- [Generative AI Drive innovation with Generative AI](/generative-ai/)
- [Responsible AI Build trust with ethical AI practices](/responsible-ai-in-enterprise/)
- [Agentic AI Reshape business with scalable agentic systems](/agentic-ai-solutions/)
- [AI Managed Services Ensure reliable AI performance](/ai-managed-services/)
- [Advanced Analytics Transform your business with data-driven insights](/advanced-data-analytics-solutions/)
- [Start Assessment](/agentic-ai-readiness-index/)
- [Data Strategy Strong data foundations for scalable AI](/data-analytics-strategy/)
- [Data Management Leverage data as a strategic asset](/ai-data-management-services/)
- [Data Ops Automate data for speed and quality](/data-devops/)
- [Data Engineering Deliver insights faster with scalable pipelines](/data-engineering/)
- [Cloud Transformation Modernize data to maximise efficiency](/cloud-migration/)
- [Download Whitepaper](/ebooks-whitepapers/building-data-products-in-a-data-mesh-to-drive-business-value/)
- [Data Modeling Structure data for better decisions](/data-modeling-services/)
- [Data Visualization Transform data into actionable stories](/data-visualization-service/)
- [BI Migration Enhance decision making with modern BI tools](/bi-migration/)
- [Data Observability Build trust with healthy, accurate data](/data-observability/)
- [Automated Insights Make smarter decisions with auto-generated insights](/automated-insights/)
- [Download Whitepaper](/ebooks-whitepapers/power-bi-hacks/)
- [CPG & Retail End-to-end analytics for planning, operations, and commercial excellence](/industries/cpg-analytics/)
- [Life Sciences Trusted intelligence across clinical, commercial, and operational workflows](/industries/life-sciences/)
- [Financial Services AI-powered analytics for risk, compliance and customer experience](/industries/banking-financial-analytics-services/)
- [Read case study](/case-studies/data-clean-room-enables-real-time-insights-to-improve-operational-efficiency/)
- [MediaIQ Advanced platform for in-flight marketing measurement](/accelerators/sigmoid-mediaiq-multi-touch-attribution-tool/)
- [CampaignIQ AI-driven platform for optimized campaign budget allocation](/accelerators/sigmoid-campaigniq/)
- [AssistBot GenAI email assistant that automates human-like responses](/accelerators/sigmoid-assistbot-for-ai-email-assistant/)
- [CreativeBot GenAI tool for personalized and brand-aligned creative design](/accelerators/sigmoid-creativebot/)
- [SocialBot GenAI platform to analyze digital conversations and trends](/accelerators/#marketing|socialbot)
- [DemandIQ Predict trends accurately and optimize inventory management](/accelerators/sigmoid-demandiq/)
- [NetworkIQ Track and optimize logistics operations in real-time to quickly address disruptions](/accelerators/sigmoid-networkiq/)
- [SupplyIQ End-to-end platform to optimize supply chain operations](/accelerators/sigmoid-supplyiq/)
- [ProcurementIQ Automated procurement operations for maximum savings, compliance and efficiency](/accelerators/sigmoid-procurementiq/)
- [RapidML Accelerated deployment for machine learning models](/accelerators/sigmoid-rapidml/)
- [DataGuard Comprehensive platform for proactive data quality management](/accelerators/data-quality-tool-sigmoid-dataguard/)
- [CloudPulse Cloud cost optimization platform with multi-cloud management](/accelerators/sigmoid-cloudpulse/)
- [RAPID GenAI foundation with built-in governance and cost clarity](/accelerators/sigmoid-rapid/)
- [AnalyticsBot GenAI based platform to streamline decision-making in analytics](/accelerators/sigmoid-analyticsbot/)
- [DataConnect Seamlessly ingest, integrate and harmonize data from diverse sources](/accelerators/sigmoid-dataconnect/)
- [Reconica AI-powered data harmonization and reconciliation engine](/accelerators/sigmoid-reconica/)
- [ConverseBot GenAI driven insights generation for automated insights from reports](/accelerators/#sales|conversebot)
- [iNRM Cross-lever revenue growth optimization platform](/accelerators/sigmoid-inrm/)
- [AssortmentIQ Optimize shelf layouts and assortment mix at scale with AI-based insights](/accelerators/sigmoid-assortmentiq/)
- [Read Whitepaper](/ebooks-whitepapers/building-agentic-ai-chatbots-for-business-process-transformation/)
- [Listen Podcast](/events/podcast/how-jack-in-the-box-is-redefining-personalization-and-supply-chain-with-ai/)
- [Blogs](/blogs/)
- [White Papers](/ebooks-whitepapers/)
- [Case Studies](/case-studies/)
- [Podcast](/events/podcast/#Podcasts)
- [Read Blog](/blogs/the-genai-adoption-triad-responsibility-ethics-and-explainability/)
- [ConverseBot](/accelerators/#sales|conversebot/)
## Tags
- AI/ML
- Cloud Transformation
- Data Management
---
## Footer Links
- [Talk to our AI experts](/contact-us/)
- [AI Strategy](/enterprise-ai-strategy/)
- [Agentic AI](/agentic-ai-solutions/)
- [Generative AI](/generative-ai/)
- [AI Managed Services](/ai-managed-services/)
- [Responsible AI](/responsible-ai-in-enterprise/)
- [Advanced Analytics](/advanced-data-analytics-solutions/)
- [Data Strategy](/data-analytics-strategy//)
- [Data Engineering](/data-engineering/)
- [Data Management](/ai-data-management-services/)
- [Cloud Transformation](/cloud-transformation/)
- [Data Ops](/data-devops/)
- [Data Visualization](/data-visualization-service/)
- [Automated Insights](/automated-insights/)
- [BI Migration](/bi-migration/)
- [Data Modeling](/data-modeling-services/)
- [Data Observability](/data-observability/)
- [CPG & Retail](/industries/cpg-analytics/)
- [Financial Services](/industries/banking-financial-analytics-services/)
- [Life Sciences](/industries/life-sciences/)
- [Case Studies](/case-studies/)
- [Thought Leadership](/ebooks-whitepapers/)
- [Blogs](/blogs/)
- [Company](/about-sigmoid/)
- [Newsroom](/newsroom/)
- [Accelerators](/accelerators/)
- [Careers](/careers/)
- [Privacy Policy |](/privacy-policy/)
- [Cookie Policy](/cookie-policy/)