---
# Why Apache Arrow is the future for open source columnar
**URL:** https://www.sigmoid.com/blogs/apache-arrow-future-open-source-columnar-memory-analytics/
Date: 2016-03-29
Author: Sigmoid
Post Type: post
Summary: Apache Arrow is an example of open source technology and is a de facto standard for columnar in-memory analytics. Engineers from across...Read More...
Categories: Data Management
Tags: Cloud Transformation
Featured Image: https://www.sigmoid.com/wp-content/uploads/2016/03/Why-Apache-Arrow-is-the-Future-for-Open-Source-Columnar-banner-opt-1.jpg
---
Apache Arrow is an example of open source technology and is a de facto standard for columnar in-memory analytics. Engineers from across the top level Apache projects are contributing towards creating Apache Arrow. In the coming years we can expect all the big data platforms adopting Apache Arrow as its columnar in-memory layer.

What can we expect from an in-memory system like Apache Arrow:
- Columnar: Over the past few years, big data is all about columnar. It was primarily inspired by the creation and adoption of Apache Parquet and other columnar data storage technologies.
- In-memory: SAP HANA was the first one to accelerate the analytical workloads with its in-memory component and then Apache Spark brought open source technology to limelight which accelerates the workloads by holding the data in memory.
- Complex data and dynamic schemas: Solving business problems are much easier when we represent the data through hierarchical and nested data structures. This was the primary reason for the adoption of JSON and document based databases.
At this point most of the systems out there hardly support two of the above concepts. Many exist which support one of them. That’s where the Apache Arrow kicks in, which supports all three of them seamlessly.
Arrow is being designed in a way to support complex data and dynamic schema and in terms of performance, it is totally based on in-memory and is columnar storage.
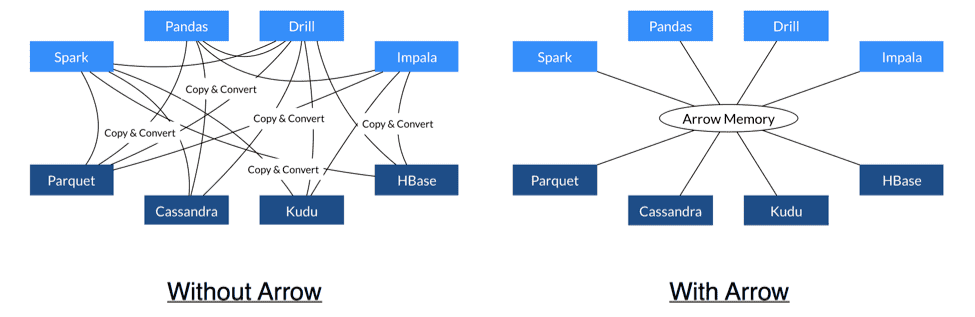
The bottleneck with any typical system comes when the data is moved across machines, Serialization is an overhead in many cases, Arrow improves the performance for the data movement within a cluster without any serialization or deserialization.
Another important aspect of Arrow is when two systems use Arrow as their in-memory storage, for example Kudu could send Arrow data to Impala for analytics purposes since both of them are Arrow-enabled without involving any costly deserialization on the receipt. Inter Process Communication is mostly happening through shared memory, TCP/IP and RDMA with Arrow. It also supports a wide variety of data types which includes both the SQL and JSON types, such as Int, BigInt, Decimal, VarChar, Map, Struct and Array.
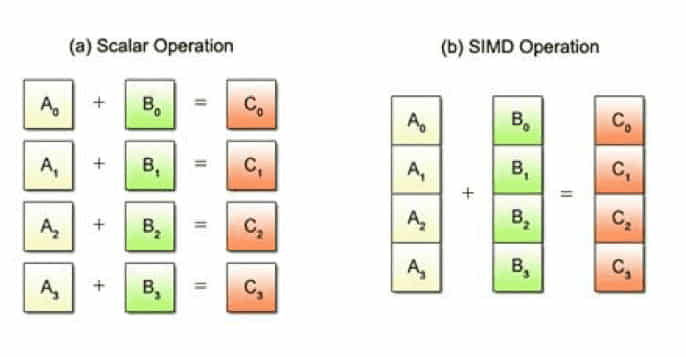
Nobody wants to wait longer to get their answers from the data. The faster they gets the answer the faster they can ask other questions or solve their business problems. CPUs these days become faster and more sophisticated in design, the key challenge in any system is making sure the CPU Utilization is at ~100% and is using it efficiently. When the data is in columnar structure, it is much easier to use SIMD instructions over it.
SIMD is short for Single Instruction/Multiple Data, while the term SIMD operations refers to a computing method that enables processing of multiple data with a single instruction. In contrast, the conventional sequential approach using one instruction to process each individual data is called scalar operations. In some cases, when using AVX instructions, these optimizations can increase performance by two orders of magnitude.
Arrow is designed to maximize the cache locality, [pipelining](/etl-and-data-pipeline/) and SIMD instructions. Cache locality, pipelining and super-word operations frequently provide 10-100x faster execution performance. Since many analytical workloads are CPU bound, these benefits translate into dramatic end-user performance gains. These gains result in faster answers and higher levels of user concurrency.
## About the Author
Akhil, a Software Developer at Sigmoid focuses on distributed computing, big data analytics, scaling and optimising performance.
[lc_the_tags]
## Featured blogs
[lc_get_posts post_type="post"
posts_per_page="4" orderby="date" output_view="lc_get_posts_mycustom_view" output_number_of_columns="4"
output_wrapper_class="row" output_article_class="shadow" output_hide_elements="Excerpt"
output_excerpt_length="0" output_excerpt_text="Read More" output_heading_tag="span"
output_featured_image_format="thumbnail" output_featured_image_class="card-img-left" ]
## Share
[addtoany]
## Subscribe to get latest insights
## Talk to our experts
Get the best ROI with Sigmoid’s services in data engineering and AI
## Suggested readings
[View all](/blogs/)
#### [Why B2B marketers need interactive analytics platform?](/blogs/why-b2b-marketers-need-interactive-analytics-platform/)
[Read blog](/blogs/why-b2b-marketers-need-interactive-analytics-platform/)

#### [5 Ways IoT-Based Predictive Maintenance Generates Business Value](/blogs/iot-based-predictive-maintenance/)
[Read blog](/blogs/iot-based-predictive-maintenance/)

#### [Creating a single source of truth for banks to accelerate productivity and customer satisfaction](/blogs/single-source-of-truth-for-banks/)
[Read blog](/blogs/single-source-of-truth-for-banks/)
---
## Categories
- Data Management
---
## Navigation
- [Company](/about-sigmoid)
- [Newsroom](/newsroom)
- [Life at Sigmoid](/careers)
- [Takshashila](/takshashila)
- [Contact Us](/contact-us)
- [AI Strategy Blueprint your AI advantage](/enterprise-ai-strategy/)
- [Generative AI Drive innovation with Generative AI](/generative-ai/)
- [Responsible AI Build trust with ethical AI practices](/responsible-ai-in-enterprise/)
- [Agentic AI Reshape business with scalable agentic systems](/agentic-ai-solutions/)
- [AI Managed Services Ensure reliable AI performance](/ai-managed-services/)
- [Advanced Analytics Transform your business with data-driven insights](/advanced-data-analytics-solutions/)
- [Start Assessment](/agentic-ai-readiness-index/)
- [Data Strategy Strong data foundations for scalable AI](/data-analytics-strategy/)
- [Data Management Leverage data as a strategic asset](/ai-data-management-services/)
- [Data Ops Automate data for speed and quality](/data-devops/)
- [Data Engineering Deliver insights faster with scalable pipelines](/data-engineering/)
- [Cloud Transformation Modernize data to maximise efficiency](/cloud-migration/)
- [Download Whitepaper](/ebooks-whitepapers/building-data-products-in-a-data-mesh-to-drive-business-value/)
- [Data Modeling Structure data for better decisions](/data-modeling-services/)
- [Data Visualization Transform data into actionable stories](/data-visualization-service/)
- [BI Migration Enhance decision making with modern BI tools](/bi-migration/)
- [Data Observability Build trust with healthy, accurate data](/data-observability/)
- [Automated Insights Make smarter decisions with auto-generated insights](/automated-insights/)
- [Download Whitepaper](/ebooks-whitepapers/power-bi-hacks/)
- [CPG & Retail End-to-end analytics for planning, operations, and commercial excellence](/industries/cpg-analytics/)
- [Life Sciences Trusted intelligence across clinical, commercial, and operational workflows](/industries/life-sciences/)
- [Financial Services AI-powered analytics for risk, compliance and customer experience](/industries/banking-financial-analytics-services/)
- [Read case study](/case-studies/data-clean-room-enables-real-time-insights-to-improve-operational-efficiency/)
- [MediaIQ Advanced platform for in-flight marketing measurement](/accelerators/sigmoid-mediaiq-multi-touch-attribution-tool/)
- [CampaignIQ AI-driven platform for optimized campaign budget allocation](/accelerators/sigmoid-campaigniq/)
- [AssistBot GenAI email assistant that automates human-like responses](/accelerators/sigmoid-assistbot-for-ai-email-assistant/)
- [CreativeBot GenAI tool for personalized and brand-aligned creative design](/accelerators/sigmoid-creativebot/)
- [SocialBot GenAI platform to analyze digital conversations and trends](/accelerators/#marketing|socialbot)
- [DemandIQ Predict trends accurately and optimize inventory management](/accelerators/sigmoid-demandiq/)
- [NetworkIQ Track and optimize logistics operations in real-time to quickly address disruptions](/accelerators/sigmoid-networkiq/)
- [SupplyIQ End-to-end platform to optimize supply chain operations](/accelerators/sigmoid-supplyiq/)
- [ProcurementIQ Automated procurement operations for maximum savings, compliance and efficiency](/accelerators/sigmoid-procurementiq/)
- [RapidML Accelerated deployment for machine learning models](/accelerators/sigmoid-rapidml/)
- [DataGuard Comprehensive platform for proactive data quality management](/accelerators/data-quality-tool-sigmoid-dataguard/)
- [CloudPulse Cloud cost optimization platform with multi-cloud management](/accelerators/sigmoid-cloudpulse/)
- [RAPID GenAI foundation with built-in governance and cost clarity](/accelerators/sigmoid-rapid/)
- [AnalyticsBot GenAI based platform to streamline decision-making in analytics](/accelerators/sigmoid-analyticsbot/)
- [DataConnect Seamlessly ingest, integrate and harmonize data from diverse sources](/accelerators/sigmoid-dataconnect/)
- [Reconica AI-powered data harmonization and reconciliation engine](/accelerators/sigmoid-reconica/)
- [ConverseBot GenAI driven insights generation for automated insights from reports](/accelerators/#sales|conversebot)
- [iNRM Cross-lever revenue growth optimization platform](/accelerators/sigmoid-inrm/)
- [AssortmentIQ Optimize shelf layouts and assortment mix at scale with AI-based insights](/accelerators/sigmoid-assortmentiq/)
- [Read Whitepaper](/ebooks-whitepapers/building-agentic-ai-chatbots-for-business-process-transformation/)
- [Listen Podcast](/events/podcast/how-jack-in-the-box-is-redefining-personalization-and-supply-chain-with-ai/)
- [Blogs](/blogs/)
- [White Papers](/ebooks-whitepapers/)
- [Case Studies](/case-studies/)
- [Podcast](/events/podcast/#Podcasts)
- [Read Blog](/blogs/the-genai-adoption-triad-responsibility-ethics-and-explainability/)
- [ConverseBot](/accelerators/#sales|conversebot/)
## Tags
- Cloud Transformation
---
## Footer Links
- [Talk to our AI experts](/contact-us/)
- [AI Strategy](/enterprise-ai-strategy/)
- [Agentic AI](/agentic-ai-solutions/)
- [Generative AI](/generative-ai/)
- [AI Managed Services](/ai-managed-services/)
- [Responsible AI](/responsible-ai-in-enterprise/)
- [Advanced Analytics](/advanced-data-analytics-solutions/)
- [Data Strategy](/data-analytics-strategy//)
- [Data Engineering](/data-engineering/)
- [Data Management](/ai-data-management-services/)
- [Cloud Transformation](/cloud-transformation/)
- [Data Ops](/data-devops/)
- [Data Visualization](/data-visualization-service/)
- [Automated Insights](/automated-insights/)
- [BI Migration](/bi-migration/)
- [Data Modeling](/data-modeling-services/)
- [Data Observability](/data-observability/)
- [CPG & Retail](/industries/cpg-analytics/)
- [Financial Services](/industries/banking-financial-analytics-services/)
- [Life Sciences](/industries/life-sciences/)
- [Case Studies](/case-studies/)
- [Thought Leadership](/ebooks-whitepapers/)
- [Blogs](/blogs/)
- [Company](/about-sigmoid/)
- [Newsroom](/newsroom/)
- [Accelerators](/accelerators/)
- [Careers](/careers/)
- [Privacy Policy |](/privacy-policy/)
- [Cookie Policy](/cookie-policy/)