Creating a single source of truth for banks to accelerate productivity and customer satisfaction
Reading Time: 5 minutes

The digital revolution has created a huge influx of data across the banking industry in terms of payments, online transactions, loans, and financing. Banks are exploring this data in predicting financial trends, personalizing customer experience, preventing cybercrime, and meeting regulatory compliance requirements. Gartner predicts that augmented data management using AI/ML solutions will reduce reliance on finance analysts for data management tasks, freeing up to 20% of their time for other productive and high value tasks.
However, leveraging ML solutions efficiently to extract meaningful insights from the data remains a challenge as often the data is scattered across the organization over multiple systems, databases and geographies. In addition, this data is available in multiple formats such as text, images, videos, and others, which makes it difficult to analyze without significant amounts of work. Traditional databases and data warehouses are not equipped to prepare and handle the diverse variety of data that flows into the banks. To navigate this complex data landscape and accelerate business process implementation, banks need to create a single source of truth with the help of data lakes that can eliminate data silos and fragmented systems. Services such as AWS data lake, Azure data lake, Google data lake, and more enable banks to efficiently create a data lake and store their data.
Data lakes act as a central location to store all the data and leverage it to yield benefits that have a long-lasting business impact. Rather than forcing analysts to navigate through data silos, data lakes lay emphasis on providing banks with easy access to an expansive berth of information. A number of data processing solutions can be used to extract value from the data to provide insights and informed decision making.
Data lakes:
The implementation of the Data Lake solution enables enterprise-level transformation by bringing more agility to data exploration and analytical practices. Data lakes can:
- Easily work with raw and unprocessed data
- Process data quickly and provide valuable insights
- Easily handle volume, velocity, and variety of data
- Access data efficiently to yield outcomes that are business-driven and customer-focused
How can banks benefit from a data lake?
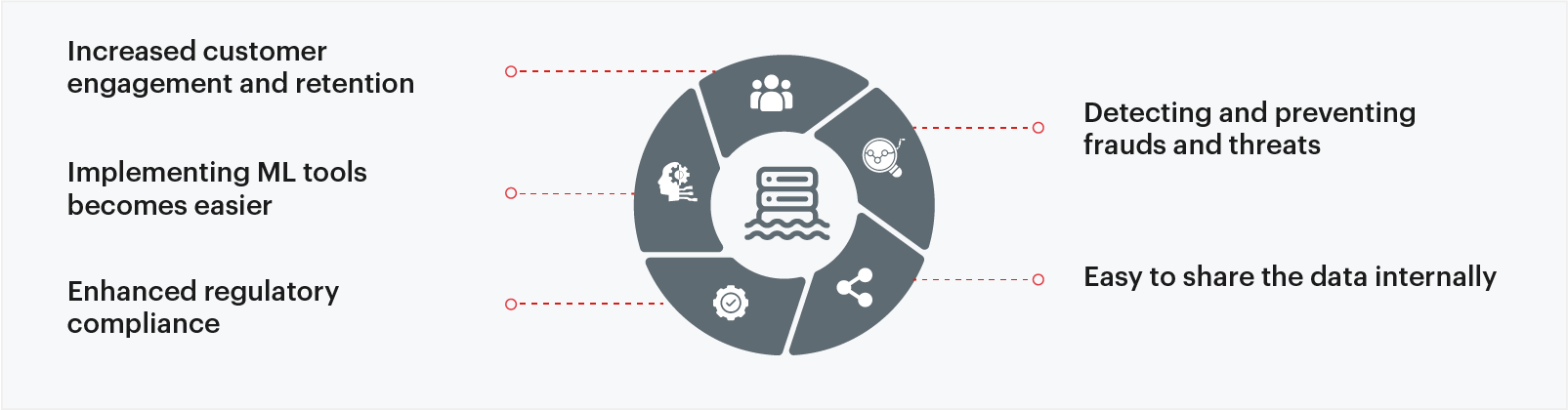
- Increased customer engagement and retention:
It is reported that 37% of banks do not have master data or a single view of customers, according to a study by Forrester. Data lakes enable banks to pull data from a wide variety of data sources to get a 360 degree view of customers to create more personalized customer experiences and support customer retention By gaining meaningful insights on customers from the data lake, banks’ marketing teams can target customers in an efficient and interactive manner and improve customer engagement online.
- Implementing ML tools becomes easier:
To yield maximum benefits from the ML system and derive value generating insights, banks need to constantly input data into it. The more the data, the better the performance of ML tools. For successful AI/ML initiatives, banks need a strong foundation of data. For creating a robust data lake, banks need to align their data strategy with business goals, find ways to make data more valuable to drive the bank’s business model, make it AI ready and more.
- Enhanced regulatory compliance:
Banks are under constant pressure to meet various regulatory compliance requirements and guidelines. At its core, governance of banks requires data aggregation and reporting. Data lakes help banks capture and automate aggregation of data across the organization to enhance data quality and gain a complete view of data across multiple channels to understand, anticipate and manage risks. Banks can aggregate risk data in near real-time and generate risk reports on demand, including crisis situations, to support changing internal needs and for auditing or supervisory queries.
- Detecting and preventing frauds and threats:
With real-time data ingestion on data lakes, banks can track all the data to identify frauds such as transaction frauds and money laundering to mitigate them at the earliest. Data lakes provide an intuitive user interface for search and ad-hoc analytics of all data and supports non-technical staff to analyze the data.
- Easy to share the data internally:
A single dataset can be used by multiple internal teams with the right access controls, for different purposes in a bank. If the data is scattered across various places, it becomes difficult for the teams to access this data leading to a delay in operations or duplication of reports due to data silos. Here, data lake makes the data easily accessible through a standardized process within an organization.
Single source of truth: 4 things to know
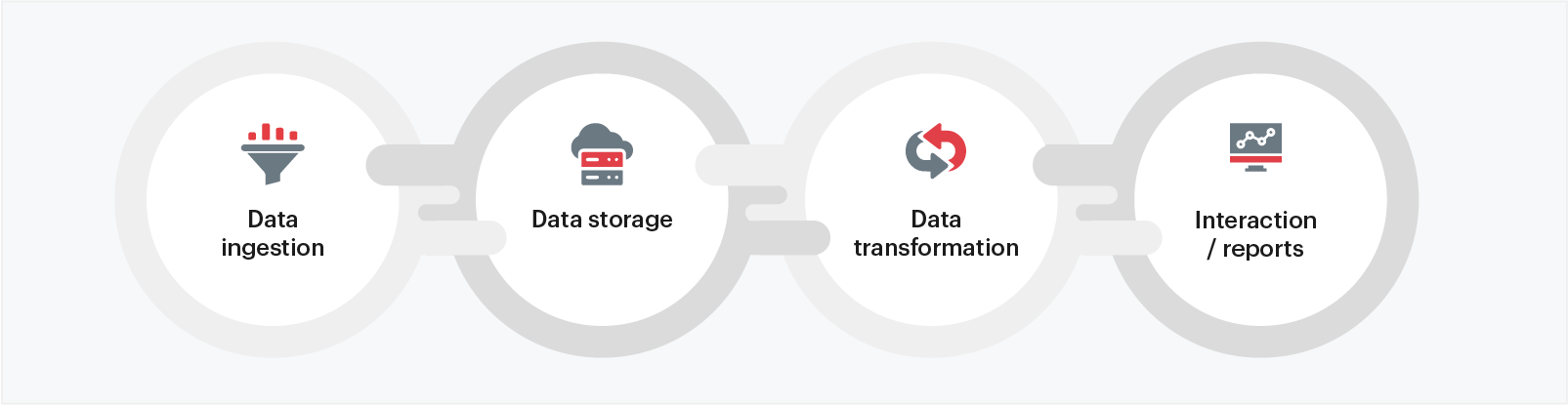
- Data ingestion: Establish a data ingestion process to extract data on a regular basis from data sources consisting of different types of data such as relational, No-SQL, streaming, batch, etc. This enables data consumers to easily browse through the dataset and schema to see if it fits their use case and get access to it. Data consumers can also reach out to producers to make changes to the data.
- Data storage: Create a data storage system that can be easily managed by a team that can manage the storage like adding hardware, replacing it, and removing it. It makes the job easy for all the users of the data.
- Data transformation: Transform and create unique data sets on the data lake based on various use cases. Multiple consumers can access data in different formats and can transform it based on their requirements.
- Interaction /reports: Query the data from different datasets in a cost effective and time efficient manner on data lakes.
To support banks in building data lakes, many service providers offer a highly available, cost-effective data lake architecture on Cloud along with a user-friendly console for searching and requesting datasets.
Conclusion
Data lakes provide banks with intelligent access to data that yields better customer experiences and enhances business outcomes. Banks can seamlessly integrate various data sources in different formats to create a single source of truth to predict and prescribe the most competent and optimized manner to effectively solve challenges with data in the banking sector.
About the Author
Tanika Gupta is Principal Data Scientist at Sigmoid and is a specialist in Machine Learning solutions for the Financial Services industry with a passion for innovation. She has over 10 years of experience and has worked at leading banking and financial institutions across the globe. Three of her ideas on payment technology have been filed for patent protection.
Featured blogs







Featured blogs