---
# Apache Spark on DataProc vs Google BigQuery
**URL:** https://www.sigmoid.com/blogs/apache-spark-on-dataproc-vs-google-bigquery/
Date: 2020-05-26
Author: Sigmoid
Post Type: post
Summary: Introduction When it comes to Big Data infrastructure on Google Cloud Platform, the most popular choices by data architects today are Google...Read More...
Categories: Data Management
Tags: Cloud Transformation
Featured Image: https://www.sigmoid.com/wp-content/uploads/2020/05/Apache-Spark-on-DataProc-vs-Google-BigQuery-banner-opt-1.jpg
---
## Introduction
When it comes to Big Data infrastructure on Google Cloud Platform, the most popular choices by data architects today are Google BigQuery, a serverless, highly scalable, and cost-effective [cloud data warehouse](/cloud-migration/), Apache Beam based Cloud Dataflow, and Dataproc, a fully managed cloud service for running [Apache Spark](/blogs/apache-spark-for-real-time-analytics/) and Apache Hadoop clusters in a simpler, more cost-efficient way.
[Data architects and engineers](/blogs/10-hacks-to-prepare-for-data-engineering-interviews/) looking at moving to [Google Cloud Platform](/press-release/partnership-with-google-cloud/) often face challenges in terms of selecting the best technology stack based on their requirements. It should not only process large volumes of data but also do it in a cost-effective yet reliable manner.
In the following sections, we will look at the research we conducted to provide interactive business intelligence reports and visualizations for thousands of end-users using BigQuery and DataProc. Furthermore, as these users can concurrently generate a variety of such interactive reports, we need to design a system that can analyze billions of data points in real-time. This will also tell how to leverage BigQuery or Apache Spark for real-time data processing. By the end of the article, we will do a quick comparison of the two tech stacks, and how BigQuery technology stands in comparison with [Spark technology](/blogs/near-real-time-finance-data-warehousing-using-apache-spark-and-delta-lake/).
## Requirements
For technology evaluation purposes, we narrowed it down to the following requirements –
Raw data set of **175TB** size: This dataset is quite diverse with scores of tables and columns consisting of metrics and dimensions derived from multiple sources.
Catering to ** 30,000 unique users**
Serving up to** 60 concurrent queries ** to the platform users
The problem statement due to the size of the base dataset and requirement for a high real-time querying paradigm requires a big data solution such as big data on [Spark](/blogs/apache-spark-for-real-time-analytics/) or BigQuery.
## Salient Features of Proposed Solution
The solution took into consideration the following 3 main characteristics of the desired system:
- Analyzing and classifying expected user queries and their frequency.
- Developing various pre-aggregations and projections to reduce data churn while serving various classes of user queries.
- Developing a state-of-the-art ‘Query Rewrite Algorithm’ to serve the user queries using a combination of aggregated datasets.
## Tech Stack Considerations
For benchmarking performance and the resulting cost implications, the following technology stack on Google Cloud Platform was considered:
Cloud DataProc + Google Cloud Storage
For Distributed processing – Apache Spark on Cloud DataProc
For Distributed Storage – Apache Parquet File format stored in Google Cloud Storage
Cloud DataProc + Google BigQuery using Storage API
For Distributed processing – Apache Spark on Cloud DataProc
For Distributed Storage – BigQuery Native Storage (Capacitor File Format over Colossus Storage) accessible through BigQuery Storage API
Native Google BigQuery for both Storage and processing – On-Demand Queries
Using BigQuery Native Storage (Capacitor File Format over Colossus Storage) and execution on BigQuery Native MPP (Dremel Query Engine)
All the queries were run in a demand fashion. The project will be billed on the total amount of data processed by user queries.
Native Google BigQuery with fixed price model
Using BigQuery Native Storage (Capacitor File Format over Colossus Storage) and execution on BigQuery Native MPP (Dremel Query Engine)
Slots reservations were made and slots assignments were done to dedicated GCP projects. All the queries and their processing will be done on the fixed number of BigQuery Slots assigned to the project.
## Tech Stack Performance Comparison
After analyzing the dataset and expected query patterns, a data schema was modeled. Dataset was segregated into various tables based on various facets. Several layers of aggregation tables were planned to speed up the user queries.
All the user data was partitioned in a time series fashion and loaded into respective fact tables. Furthermore, various aggregation tables were created on top of these tables. All the metrics in these aggregation tables were grouped by frequently queried dimensions.
In the next layer on top of this base dataset, various aggregation tables were added, where the metrics data was rolled up on a per-day basis.
All the probable user queries were divided into 5 categories –
- Raw data and lifting over 3 months of data
- Aggregated data and lifting over 3 months of data
- Aggregated data over 7 days.
- Aggregated data over 15 days.
- Raw data over 1 month.
The total data processed by individual queries depends upon the time window being queried and the granularity of the tables being hit.
### Query Response times for large data sets – Spark and BigQuery
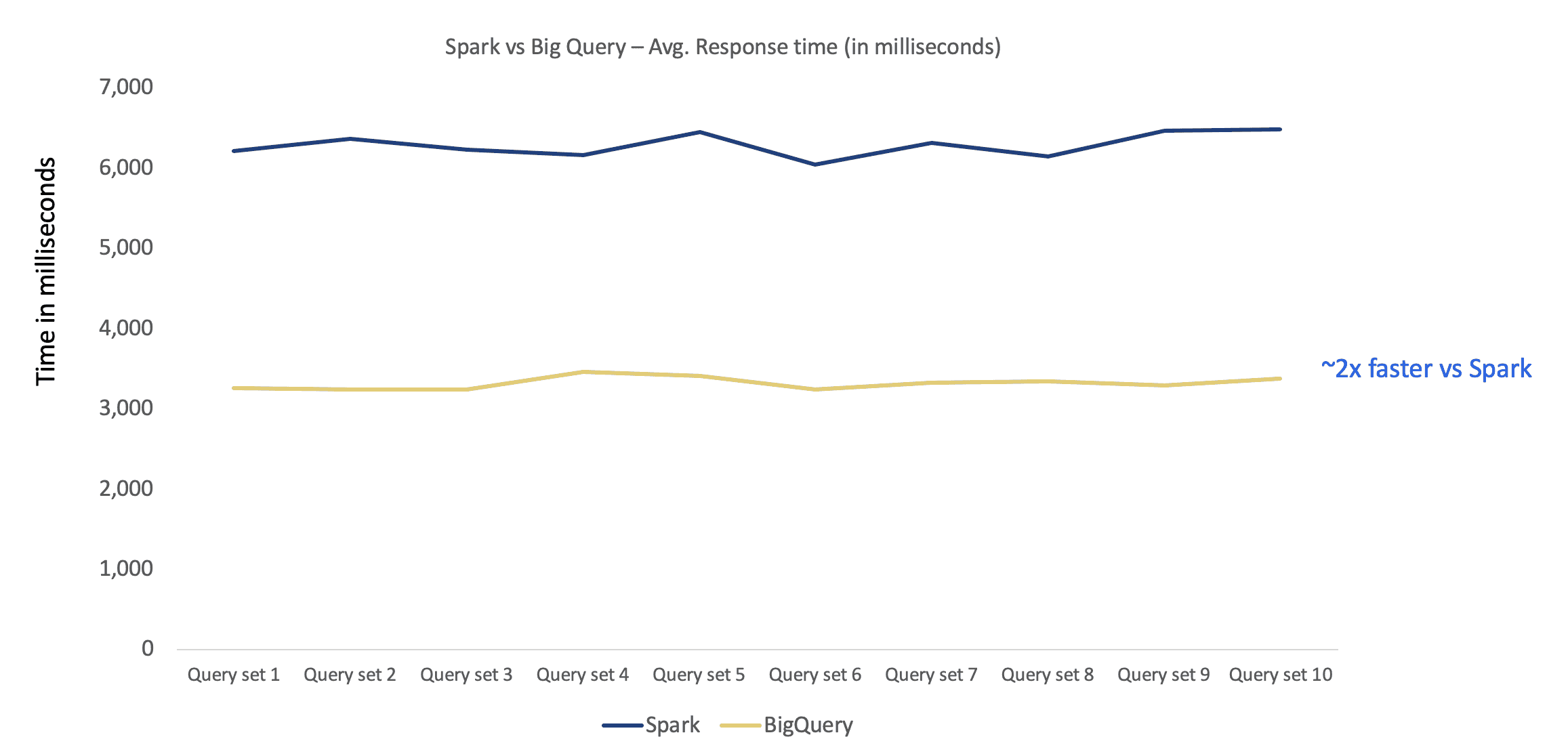
Test Configuration
Total Threads = 60,Test Duration = 1 hour, Cache OFF
1) Apache Spark cluster on Cloud DataProc
Total Nodes = 150 (20 cores and 72 GB), Total Executors = 1200
2) BigQuery cluster
BigQuery Slots Used = 1800 to 1900
### Query Response times for aggregated data sets – Spark and BigQuery
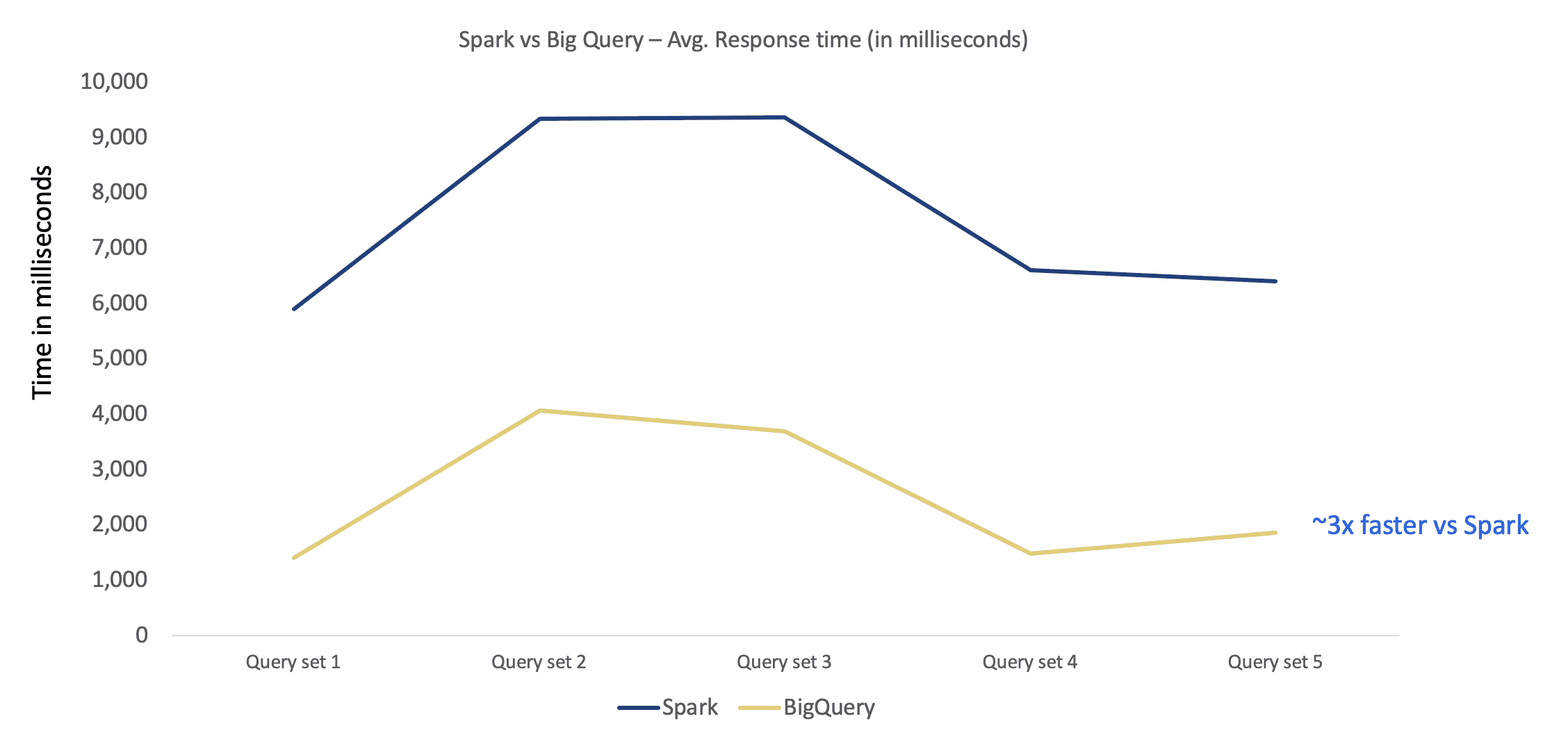
Test Configuration
Total Threads = 60,Test Duration = 1 hour, Cache OFF
1) Apache Spark cluster on Cloud DataProc
Total Machines = 250 to 300, Total Executors = 2000 to 2400, 1 Machine = 20 Cores, 72GB
2) BigQuery cluster
BigQuery Slots Used: 2000
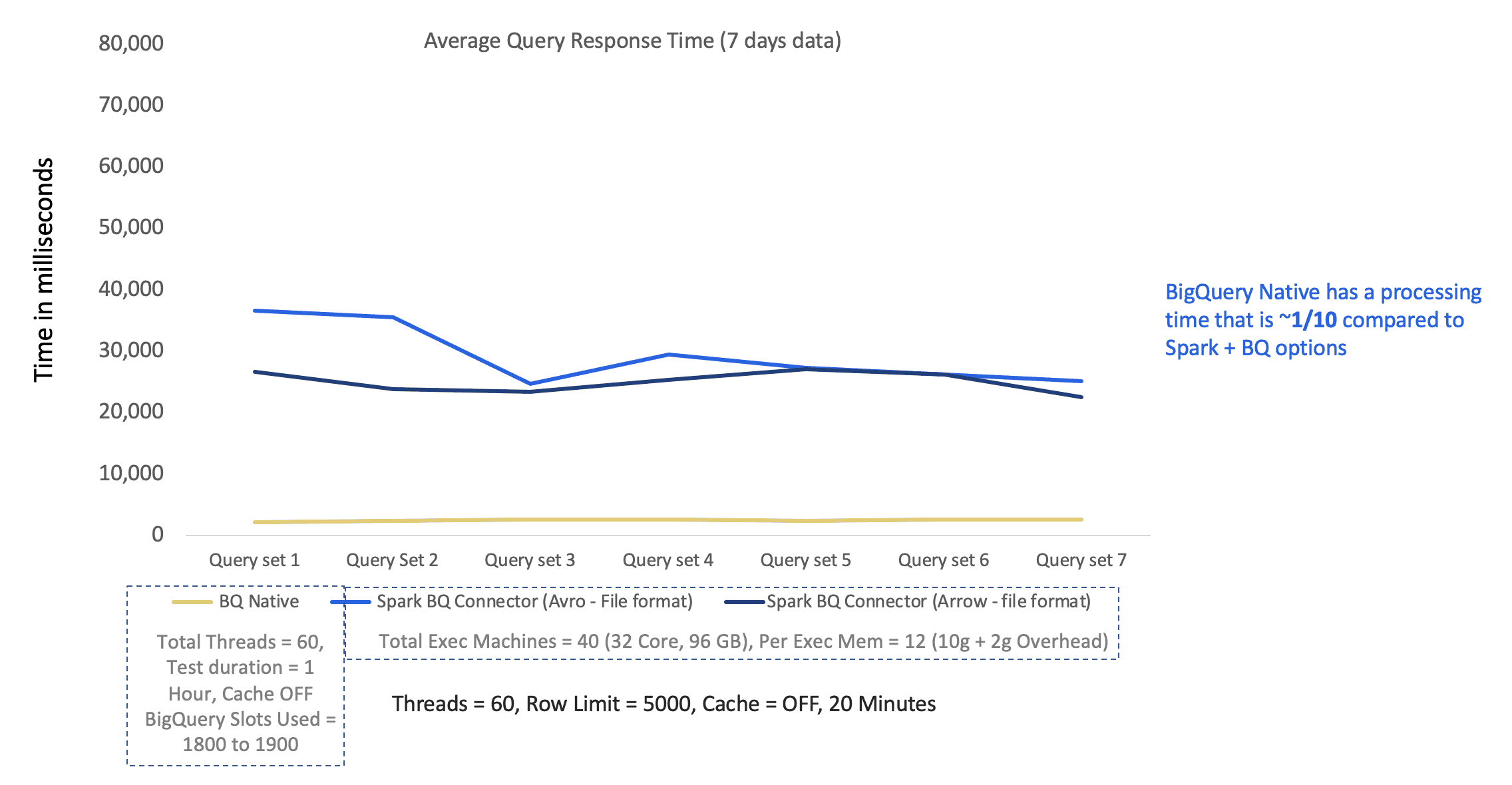
### Performance testing on 7 days data – Big Query native & Spark BQ Connector
It can be seen that BigQuery Native has a processing time that is ~1/10 compared to Spark + BQ options
### Performance testing on 15 days data – Big Query native & Spark BQ Connector
It can be seen that BigQuery Native has a processing time that is ~1/25 compared to Spark + BQ options
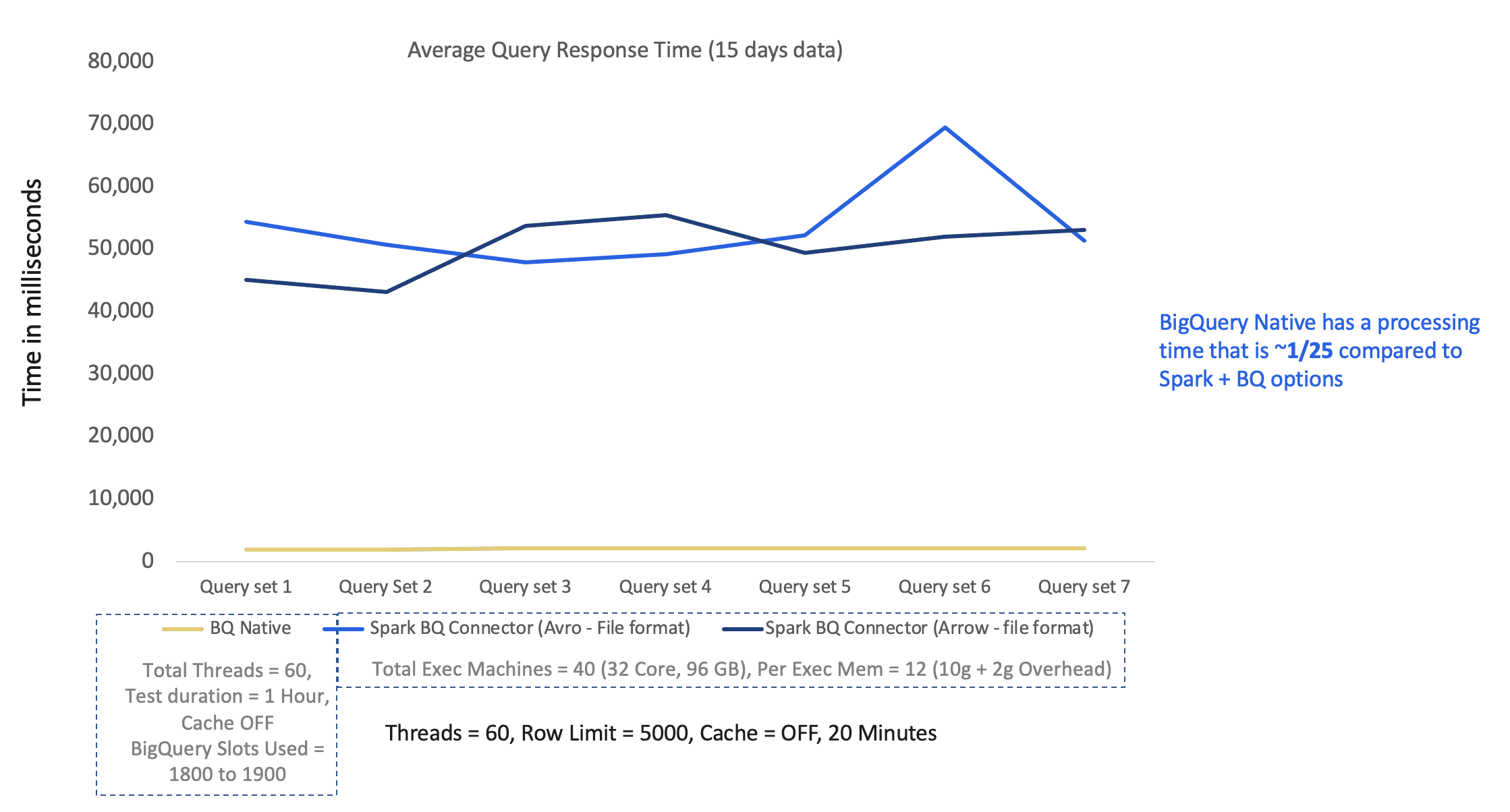
Processing time seems to reduce with an increase in the data volume
### Longevity Tests – BigQuery Native REST API
Once it was established that BigQuery Native outperformed other tech stack options in all aspects, we also ran extensive longevity tests to evaluate the response time consistency of data queries on BigQuery Native REST API.
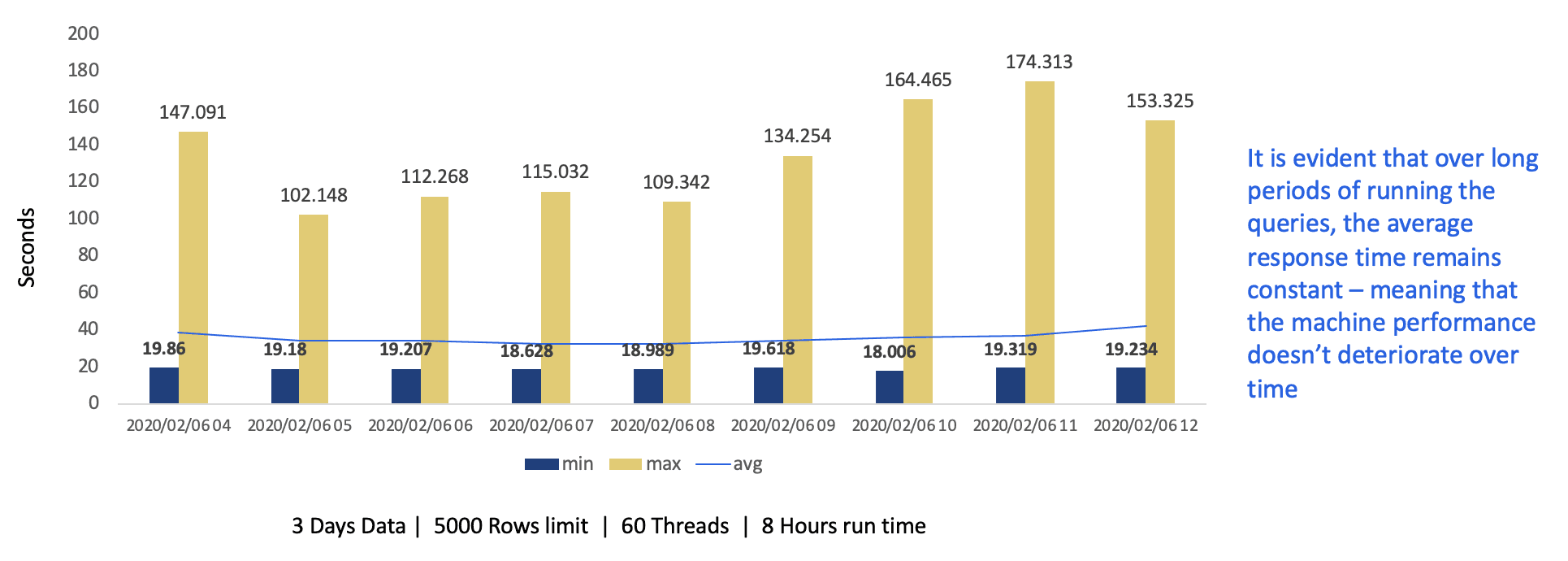
## ETL performance – BigQuery Native
To evaluate the [ETL performance](/etl-and-data-pipeline/) and infer various metrics with respect to the execution of ETL jobs, we ran several types of jobs at varied concurrency.
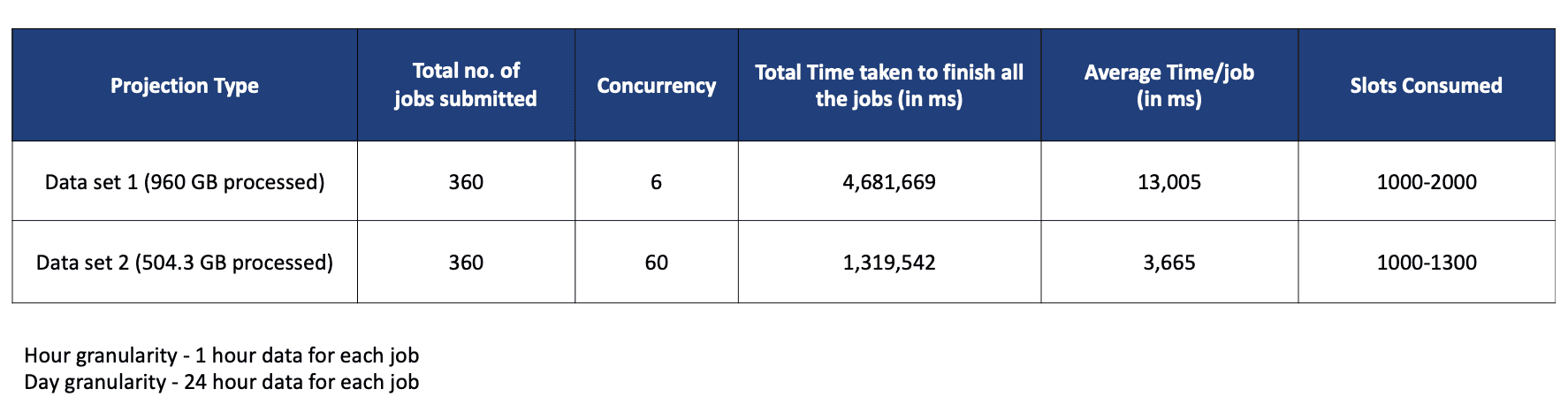
In BigQuery, similar to interactive queries, the [ETL jobs](/blogs/etl-on-cloud-transforming-big-data-analytics/) running in the batch mode were very performant and finished within expected time windows. This should allow all the ETL jobs to load hourly data into user-facing tables and complete it in a timely fashion.
Running the ETL jobs in batch mode has another benefit. All jobs running in batch mode do not count against the maximum number of allowed concurrent BigQuery jobs per project.
## Comparing costs – Apache Spark vs BigQuery technology
Here we capture the comparison undertaken to evaluate the cost viability of the identified technology stacks.
Actual Data Size used in exploration:
Two Months billable dataset size in BigQuery: 59.73 TB.
Two Months billable dataset size of Parquet stored in Google Cloud Storage: 3.5 TB. Parquet file format
follows columnar storage resulting in great compression, reducing the overall storage costs.
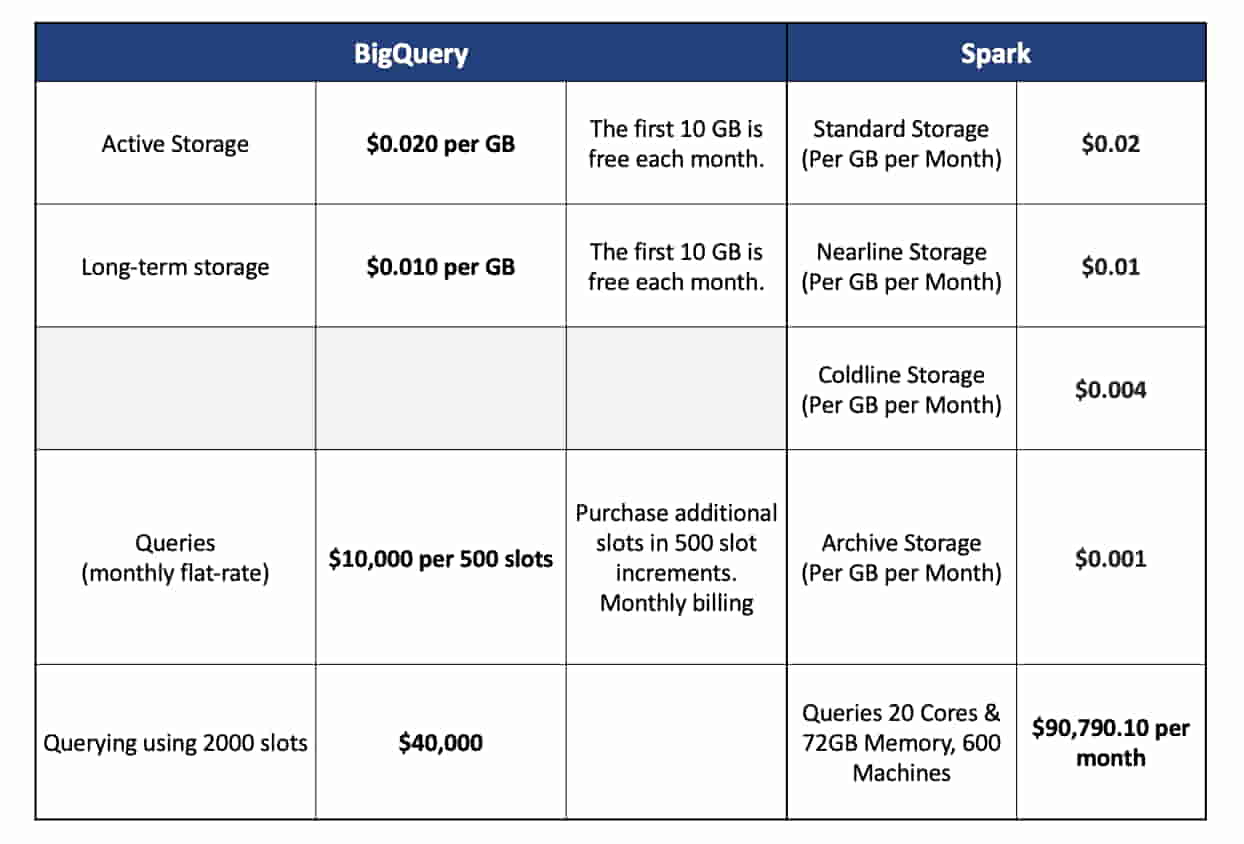
Actual Data Size used in exploration-
BigQuery 2 Months Size (Table): 59.73 TB
Spark 2 Months Size (Parquet): 3.5 TB
In BigQuery – storage pricing is based on the amount of data stored in your tables when it is uncompressed
In BigQuery – even though on-disk data is stored in Capacitor, a columnar file format, storage pricing is based on the amount of data stored in your tables when it is uncompressed. Hence, the Data Storage size in BigQuery is **~17x** higher than that in Apache Spark on GCP in parquet format.
## Conclusion
- For both small and large datasets, user queries’ performance on the BigQuery Native platform was significantly better than that on the Spark Dataproc cluster.
- Query cost for both On-Demand queries with BigQuery and [Spark-based queries](/blogs/optimize-nested-queries-using-apache-spark/) on Cloud DataProc is substantially high.
- Using BigQuery with a Flat-rate priced model resulted in sufficient cost reduction with minimal performance degradation.
### About the Authors
Prateek Srivastava is Technical Lead at Sigmoid with expertise in Big data, Streaming, Cloud and Service Oriented architecture. Roushan is a Software Engineer at Sigmoid, who works on building ETL pipelines and Query Engine on Apache Spark & BigQuery, and optimising query performance
[lc_the_tags]
## Featured blogs
[lc_get_posts post_type="post"
posts_per_page="4" orderby="date" output_view="lc_get_posts_mycustom_view" output_number_of_columns="4"
output_wrapper_class="row" output_article_class="shadow" output_hide_elements="Excerpt"
output_excerpt_length="0" output_excerpt_text="Read More" output_heading_tag="span"
output_featured_image_format="thumbnail" output_featured_image_class="card-img-left" ]
## Share
[addtoany]
Subscribe to get latest insights
## Talk to our experts
Get the best ROI with Sigmoid’s services in data engineering and AI
## Suggested readings
[View all](/blogs/)

#### [Apache Spark for Real-time Analytics](/blogs/apache-spark-for-real-time-analytics/)
[Read blog](/blogs/apache-spark-for-real-time-analytics/)

#### [How to Optimize Nested Queries using Apache Spark](/blogs/optimize-nested-queries-using-apache-spark/)
[Read blog](/blogs/optimize-nested-queries-using-apache-spark/)

#### [Cloud Data Warehouse is The Future of Data storage](/blogs/cloud-data-warehouse-is-the-future-of-data-storage/)
[Read blog](/blogs/cloud-data-warehouse-is-the-future-of-data-storage/)
---
## Categories
- Data Management
---
## Navigation
- [WordPress.org](https://wordpress.org/)
- [Documentation](https://wordpress.org/documentation/)
- [Learn WordPress](https://learn.wordpress.org/)
- [Support](https://wordpress.org/support/forums/)
- [Feedback](https://wordpress.org/support/forum/requests-and-feedback)
- [Sigmoid](https://www.sigmoid.com/)
- [Community](https://community.wpmanageninja.com/portal/space/fluent-forms/home)
- [Docs](https://wpmanageninja.com/docs/fluent-form/)
- [Developer Docs](https://developers.fluentforms.com/)
- [Documentation](https://imagify.io/documentation/)
- [Rate Imagify on WordPress.org](https://wordpress.org/support/view/plugin-reviews/imagify?rate=5#postform)
- [Manage](admin.php?page=litespeed)
- [Settings](admin.php?page=litespeed-cache)
- [Image Optimization](admin.php?page=litespeed-img_optm)
- [Company](/about-sigmoid)
- [Newsroom](/newsroom)
- [Life at Sigmoid](/careers)
- [Takshashila](/takshashila)
- [Contact Us](/contact-us)
- [AI Strategy Blueprint your AI advantage](/enterprise-ai-strategy/)
- [Generative AI Drive innovation with Generative AI](/generative-ai/)
- [Responsible AI Build trust with ethical AI practices](/responsible-ai-in-enterprise/)
- [Agentic AI Reshape business with scalable agentic systems](/agentic-ai-solutions/)
- [AI Managed Services Ensure reliable AI performance](/ai-managed-services/)
- [Advanced Analytics Transform your business with data-driven insights](/advanced-data-analytics-solutions/)
- [Start Assessment](/agentic-ai-readiness-index/)
- [Data Strategy Strong data foundations for scalable AI](/data-analytics-strategy/)
- [Data Management Leverage data as a strategic asset](/ai-data-management-services/)
- [Data Ops Automate data for speed and quality](/data-devops/)
- [Data Engineering Deliver insights faster with scalable pipelines](/data-engineering/)
- [Cloud Transformation Modernize data to maximise efficiency](/cloud-migration/)
- [Download Whitepaper](/ebooks-whitepapers/building-data-products-in-a-data-mesh-to-drive-business-value/)
- [Data Modeling Structure data for better decisions](/data-modeling-services/)
- [Data Visualization Transform data into actionable stories](/data-visualization-service/)
- [BI Migration Enhance decision making with modern BI tools](/bi-migration/)
- [Data Observability Build trust with healthy, accurate data](/data-observability/)
- [Automated Insights Make smarter decisions with auto-generated insights](/automated-insights/)
- [Download Whitepaper](/ebooks-whitepapers/power-bi-hacks/)
- [CPG & Retail End-to-end analytics for planning, operations, and commercial excellence](/industries/cpg-analytics/)
- [Life Sciences Trusted intelligence across clinical, commercial, and operational workflows](/industries/life-sciences/)
- [Financial Services AI-powered analytics for risk, compliance and customer experience](/industries/banking-financial-analytics-services/)
- [Read case study](/case-studies/data-clean-room-enables-real-time-insights-to-improve-operational-efficiency/)
- [MediaIQ Advanced platform for in-flight marketing measurement](/accelerators/sigmoid-mediaiq-multi-touch-attribution-tool/)
- [CampaignIQ AI-driven platform for optimized campaign budget allocation](/accelerators/sigmoid-campaigniq/)
- [AssistBot GenAI email assistant that automates human-like responses](/accelerators/sigmoid-assistbot-for-ai-email-assistant/)
- [CreativeBot GenAI tool for personalized and brand-aligned creative design](/accelerators/sigmoid-creativebot/)
- [SocialBot GenAI platform to analyze digital conversations and trends](/accelerators/#marketing|socialbot)
- [DemandIQ Predict trends accurately and optimize inventory management](/accelerators/sigmoid-demandiq/)
- [NetworkIQ Track and optimize logistics operations in real-time to quickly address disruptions](/accelerators/sigmoid-networkiq/)
- [SupplyIQ End-to-end platform to optimize supply chain operations](/accelerators/sigmoid-supplyiq/)
- [ProcurementIQ Automated procurement operations for maximum savings, compliance and efficiency](/accelerators/sigmoid-procurementiq/)
- [RapidML Accelerated deployment for machine learning models](/accelerators/sigmoid-rapidml/)
- [DataGuard Comprehensive platform for proactive data quality management](/accelerators/data-quality-tool-sigmoid-dataguard/)
- [CloudPulse Cloud cost optimization platform with multi-cloud management](/accelerators/sigmoid-cloudpulse/)
- [RAPID GenAI foundation with built-in governance and cost clarity](/accelerators/sigmoid-rapid/)
- [AnalyticsBot GenAI based platform to streamline decision-making in analytics](/accelerators/sigmoid-analyticsbot/)
- [DataConnect Seamlessly ingest, integrate and harmonize data from diverse sources](/accelerators/sigmoid-dataconnect/)
- [Reconica AI-powered data harmonization and reconciliation engine](/accelerators/sigmoid-reconica/)
- [ConverseBot GenAI driven insights generation for automated insights from reports](/accelerators/#sales|conversebot)
- [iNRM Cross-lever revenue growth optimization platform](/accelerators/sigmoid-inrm/)
- [AssortmentIQ Optimize shelf layouts and assortment mix at scale with AI-based insights](/accelerators/sigmoid-assortmentiq/)
- [Read Whitepaper](/ebooks-whitepapers/building-agentic-ai-chatbots-for-business-process-transformation/)
- [Listen Podcast](/events/podcast/how-jack-in-the-box-is-redefining-personalization-and-supply-chain-with-ai/)
- [Blogs](/blogs/)
- [White Papers](/ebooks-whitepapers/)
- [Case Studies](/case-studies/)
- [Podcast](/events/podcast/#Podcasts)
- [Read Blog](/blogs/the-genai-adoption-triad-responsibility-ethics-and-explainability/)
- [ConverseBot](/accelerators/#sales|conversebot/)
## Tags
- Cloud Transformation
---
## Footer Links
- [Talk to our AI experts](/contact-us/)
- [AI Strategy](/enterprise-ai-strategy/)
- [Agentic AI](/agentic-ai-solutions/)
- [Generative AI](/generative-ai/)
- [AI Managed Services](/ai-managed-services/)
- [Responsible AI](/responsible-ai-in-enterprise/)
- [Advanced Analytics](/advanced-data-analytics-solutions/)
- [Data Strategy](/data-analytics-strategy//)
- [Data Engineering](/data-engineering/)
- [Data Management](/ai-data-management-services/)
- [Cloud Transformation](/cloud-transformation/)
- [Data Ops](/data-devops/)
- [Data Visualization](/data-visualization-service/)
- [Automated Insights](/automated-insights/)
- [BI Migration](/bi-migration/)
- [Data Modeling](/data-modeling-services/)
- [Data Observability](/data-observability/)
- [CPG & Retail](/industries/cpg-analytics/)
- [Financial Services](/industries/banking-financial-analytics-services/)
- [Life Sciences](/industries/life-sciences/)
- [Case Studies](/case-studies/)
- [Thought Leadership](/ebooks-whitepapers/)
- [Blogs](/blogs/)
- [Company](/about-sigmoid/)
- [Newsroom](/newsroom/)
- [Accelerators](/accelerators/)
- [Careers](/careers/)
- [Privacy Policy |](/privacy-policy/)
- [Cookie Policy](/cookie-policy/)