---
# 9 things you need to know about microservices
**URL:** https://www.sigmoid.com/blogs/9-things-you-need-to-know-about-microservices/
Date: 2020-12-22
Author: Sigmoid
Post Type: post
Summary: The rise of microservices The chart below clearly shows that microservices have been trending since 2015. This is because the arrival of...Read More...
Categories: Data Management
Tags: AI/ML, Cloud Transformation
Featured Image: https://www.sigmoid.com/wp-content/uploads/2023/11/9-things-you-need-to-know-about-microservices-banner-opt.jpg
---
The rise of microservices
The chart below clearly shows that microservices have been trending since 2015.
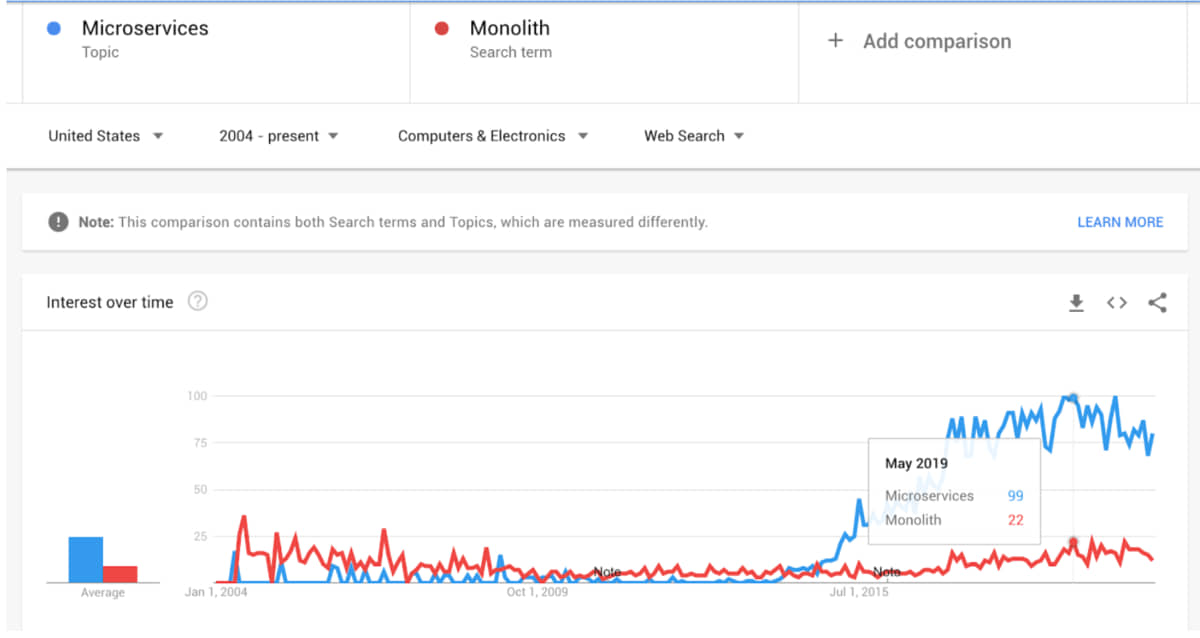
This is because the arrival of docker and [kubernetes](/blogs/containerization-of-pyspark-using-kubernetes/) around 2015 almost nullified the effort and resources required for the scaling and deployment of microservices, which was otherwise arduous because of the lengthy deployment times.
## What is a Microservice?
Someone coming from a monolith background might say “we have a module and they separated it out and called it microservices. What difference does it make other than the overhead to maintain multiple repositories?”
So to answer this question, we need to decide how granular we want to go in splitting the services and how many resources are available to maintain them. For instance, a single person might find it difficult to manage more than 5 services with sufficient level of productivity. Generally it is observed that a single person can effectively manage and maintain up to 3 services. It’s best to split the monolith when there are enough people to manage these microservices and it should be split in a way that it seldom changes (splitting it by sub domain or business capability). On the other hand, over splitting it causes network saturation issues.
Microservice is an important concept in [data engineering](/ebooks-whitepapers/data-engineering-overcome-challenges-in-enterprise-analytics/). Let us now look at the nine important things about microservices.
**Testing of only a fraction of the application**
We often don’t have changes in every component / module in our monolith. This is specifically advantageous for [microservices architecture](/blogs/microservices-based-architecture-key-to-scaling-enterprise-ml-models/) as you only have to update & test a fraction of your overall applications. Since we only connect via API the other applications talking to the updated application have the same experience unless you introduce a breaking change.
But microservices do take more planning, time at the time of development, and coordination when your api changes. If this doesn’t bother you, you can avail the benefits of microservices architecture without worrying about the pagers at midnight.
On the other hand, when a bunch of people work on one project, Monolith applications become hard to maintain and release as it takes a good amount of time in resolving merge conflicts. And the need to deploy the whole application for any small change in a single module might seem a bit impractical to some.
**Learning from failures**
Software projects can sometimes be more complicated than we think. No matter how much care we take in filling out all the potholes, there would be some or the other scenario that can still cause issues, some edge case still left out.
So we should always be designing systems for failures. As the saying goes, a system that fails fast and recovers fast has far better scope than a system that doesn’t.
On this front, Google does exactly this with Kubernetes. With Kubernetes we can rapidly deploy and revert any changes within a matter of minutes (sometimes even seconds!!) as opposed to hours without it.
It is wise to acknowledge that there would be defects that need to be fixed, learn from these defects and automate the learnings into the process. This is also aligned [with the core philosophy of Agile Methodology](/data-devops/).
It is important to also be aware of some of the common myths
- The network is reliable.
- The network is homogeneous and the load balancing is even.
- Bandwidth is infinite.
- Transport Cost is zero.

**Blocking queries**
The concept of **failing fast** is crucial for microservices. It doesn’t make sense to wait for an hour for a query fired from a dashboard. In addition it blocks the other queries that are in line. So therefore we configure a timeout and we fail it fast. Why does failing fast become important in microservices? Because in a monolith application, we only have one service it’s fairly simple to identify failures. In a microservice, we wouldn’t be sure which is the slow service causing the system to hang.
**Kubernetes – the saving grace for scaling applications**
In an imperfect world, machines die. So, do applications that run on those machines. And these applications take the user experience with it. This can be fixed using Auto-healing.
When services are running on Kubernetes, there is no worry about such failures. But there is a catch here. For this to be possible, we need multiple instances of our service running on different machines ensuring that we have no disruption in the user experience. But not all instances can be running always.
Microservice applications when on Kubernetes can scale up and down when needed. Kubernetes can be seen as the Suit that enables our application to scale up and down as the input load does. Since with Kubernetes we don’t really have the painful part of microservices (deploying multiple microservices on multiple machines) monolith has very little advantage left.
**Single point of failures**
Often we have that one application / service / server that everyone depends on, be it a proxy server or an authentication service or a master node or a database. As most call this, the one thing that we all depend on is a Single Point of Failure.
So what’s with a single point of failure? As we know monolith architecture has everything in a single application and hence we deploy the whole application for every minor change. And there is risk involved every single time. And everything goes down if one part does.
Whereas in microservices, we have this risk but only with critical ones and only to a particular feature that depends on the upgraded microservice.
** Microservices don’t DIY**
Since each microservice is a fraction of the monolith application, it is not expected to do everything by itself. Each has a specific job and they do their best to accomplish it not worrying about other services. So when a service needs to check something related to another service, it just asks the corresponding service.
**Communication is the Key**
Since a microservice doesn’t do everything by itself, it asks the corresponding service and this continues with the corresponding service until we have what we are looking for. So the communication becomes the key in microservices architecture where in monolith, the application knows everything that it requires.
In microservices and the network IO, when a lot of microservices talk to each other the network saturates and it leads to higher latencies or worse. So while designing microservices, it’s good to keep just the required number of services. Defining success with the count of microservices in place is not right.
**Every service is different in its own way**
Every part of a monolith application has different needs. Some are very memory intensive, some have high processing requirements, some have increased communication needs – either to storage or within the network.
If the application has such requirements, it’s best to split them up and scale them independently as they please. And more over scaling algorithms can greatly benefit from separation of cpu intensive and memory intensive parts of the application.
And if there is one part of the monolith service that is very popular, spinning up more instances of just that could sometimes be beneficial.
Some are written best in golang, some in java, some in python. When a monolithic architecture is used, there is a constraint of a single language or technology. Whereas if the monolith is split into microservices, there would no longer be any constraints of a language or technology.
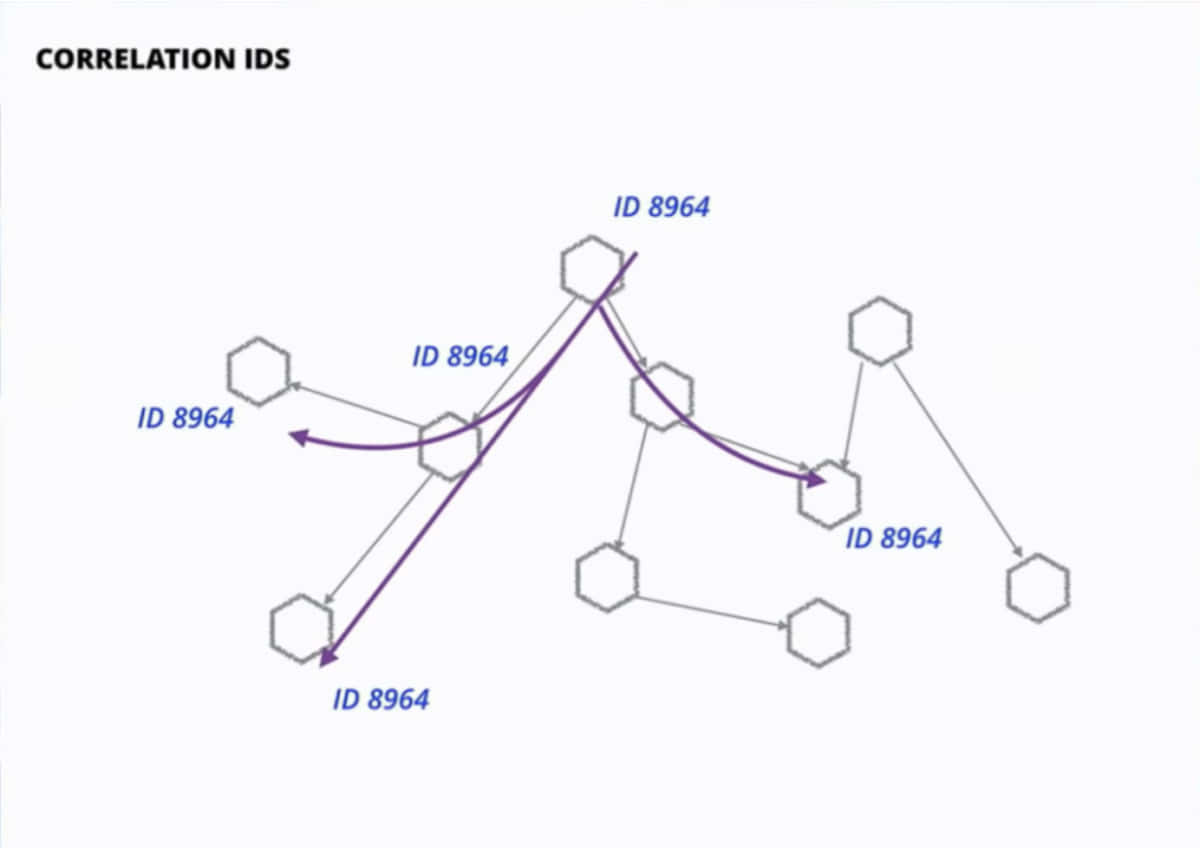
**Identifying failures?**
When it comes to application and their failures, in monolithic architecture, we have a single place, a single log file to go to but in case of microservices architecture, backtracking the issue can be tiring if the right tools are not in place. It is recommended to keep an id associated with every request for this. And a log persistence service to collect all logs from Kubernetes and persist them for analysis at a later point of time.
## What not to do with microservices
- Believing that a sprinkle of microservices will solve all development problems.
- Making the adoption of microservices the goal and measuring success in terms of the number of services written.
- Multiple application development teams attempt to adopt the microservice architecture without any coordination.
- Attempting to adopt the microservice architecture (an advanced technique) without (or not committing to) practicing basic software development techniques, such as clean code, good design, and automated testing.
- Focussing on technology aspects of microservices, most commonly the deployment infrastructure, and neglecting key issues, such as service decomposition.
- Intentionally creating a very fine-grained microservice architecture.
- Retaining the same development process and organization structure that were used when developing monolithic applications.
## Conclusion
Of late, the tech market is buzzing with the news of major tech companies like Google, Netflix stepping from monolith to microservices architecture. Kubernetes and dockerization made microservices architecture possible like never before. If network and coordination requirements at the time of API version upgrade can be managed well, the microservices architecture offers a great deal of advantages. In scenarios where the use case is very simple or an extremely small team handling a large use case with limited time for planning, monolithic architecture can be considered.
As application and software development trends continue to evolve, the debate between using microservices or leveraging traditional monolithic architectures will only become more pronounced. In the end, developers must understand what works for their teams and their product’s specific use cases.
## About the authors
Nuthan is a Data Engineer at Sigmoid who is passionate about building reliable, responsive and highly scalable end-to-end solutions by using a mix of open source technologies and cloud services.
Assisted by Shreya, Software Engineer at Sigmoid who currently works on building Query Engine and ETL pipelines on Spark, BigQuery and was involved in migration of Sigview from monolith to microservices.
[lc_the_tags]
## Featured blogs
[lc_get_posts post_type="post"
posts_per_page="4" orderby="date" output_view="lc_get_posts_mycustom_view" output_number_of_columns="4"
output_wrapper_class="row" output_article_class="shadow" output_hide_elements="Excerpt"
output_excerpt_length="0" output_excerpt_text="Read More" output_heading_tag="span"
output_featured_image_format="thumbnail" output_featured_image_class="card-img-left" ]
## Share
[addtoany]
Subscribe to get latest insights
## Talk to our experts
Get the best ROI with Sigmoid’s services in data engineering and AI
## Suggested readings
[View all](/blogs/)

#### [Quantum Computing: Implementing QSVM in IBM Q](/blogs/quantum-computing-blog-3-how-to-implement-qsvm-in-the-ibm-q-environment/)
[Read blog](/blogs/quantum-computing-blog-3-how-to-implement-qsvm-in-the-ibm-q-environment/)

#### [The Quantum Supremacy Experiment](/blogs/the_quantum_supremacy_experiment/)
[Read blog](/blogs/the_quantum_supremacy_experiment/)

#### [What’s all the fuss about Quantum Computing and Quantum Supremacy?](/blogs/whats-all-the-fuss-about-quantum-computing-and-quantum-supremacy/)
[Read blog](/blogs/whats-all-the-fuss-about-quantum-computing-and-quantum-supremacy/)
---
## Categories
- Data Management
---
## Navigation
- [WordPress.org](https://wordpress.org/)
- [Documentation](https://wordpress.org/documentation/)
- [Learn WordPress](https://learn.wordpress.org/)
- [Support](https://wordpress.org/support/forums/)
- [Feedback](https://wordpress.org/support/forum/requests-and-feedback)
- [Sigmoid](https://www.sigmoid.com/)
- [Community](https://community.wpmanageninja.com/portal/space/fluent-forms/home)
- [Docs](https://wpmanageninja.com/docs/fluent-form/)
- [Developer Docs](https://developers.fluentforms.com/)
- [Documentation](https://imagify.io/documentation/)
- [Rate Imagify on WordPress.org](https://wordpress.org/support/view/plugin-reviews/imagify?rate=5#postform)
- [Manage](admin.php?page=litespeed)
- [Settings](admin.php?page=litespeed-cache)
- [Image Optimization](admin.php?page=litespeed-img_optm)
- [Company](/about-sigmoid)
- [Newsroom](/newsroom)
- [Life at Sigmoid](/careers)
- [Takshashila](/takshashila)
- [Contact Us](/contact-us)
- [AI Strategy Blueprint your AI advantage](/enterprise-ai-strategy/)
- [Generative AI Drive innovation with Generative AI](/generative-ai/)
- [Responsible AI Build trust with ethical AI practices](/responsible-ai-in-enterprise/)
- [Agentic AI Reshape business with scalable agentic systems](/agentic-ai-solutions/)
- [AI Managed Services Ensure reliable AI performance](/ai-managed-services/)
- [Advanced Analytics Transform your business with data-driven insights](/advanced-data-analytics-solutions/)
- [Start Assessment](/agentic-ai-readiness-index/)
- [Data Strategy Strong data foundations for scalable AI](/data-analytics-strategy/)
- [Data Management Leverage data as a strategic asset](/ai-data-management-services/)
- [Data Ops Automate data for speed and quality](/data-devops/)
- [Data Engineering Deliver insights faster with scalable pipelines](/data-engineering/)
- [Cloud Transformation Modernize data to maximise efficiency](/cloud-migration/)
- [Download Whitepaper](/ebooks-whitepapers/building-data-products-in-a-data-mesh-to-drive-business-value/)
- [Data Modeling Structure data for better decisions](/data-modeling-services/)
- [Data Visualization Transform data into actionable stories](/data-visualization-service/)
- [BI Migration Enhance decision making with modern BI tools](/bi-migration/)
- [Data Observability Build trust with healthy, accurate data](/data-observability/)
- [Automated Insights Make smarter decisions with auto-generated insights](/automated-insights/)
- [Download Whitepaper](/ebooks-whitepapers/power-bi-hacks/)
- [CPG & Retail End-to-end analytics for planning, operations, and commercial excellence](/industries/cpg-analytics/)
- [Life Sciences Trusted intelligence across clinical, commercial, and operational workflows](/industries/life-sciences/)
- [Financial Services AI-powered analytics for risk, compliance and customer experience](/industries/banking-financial-analytics-services/)
- [Read case study](/case-studies/data-clean-room-enables-real-time-insights-to-improve-operational-efficiency/)
- [MediaIQ Advanced platform for in-flight marketing measurement](/accelerators/sigmoid-mediaiq-multi-touch-attribution-tool/)
- [CampaignIQ AI-driven platform for optimized campaign budget allocation](/accelerators/sigmoid-campaigniq/)
- [AssistBot GenAI email assistant that automates human-like responses](/accelerators/sigmoid-assistbot-for-ai-email-assistant/)
- [CreativeBot GenAI tool for personalized and brand-aligned creative design](/accelerators/sigmoid-creativebot/)
- [SocialBot GenAI platform to analyze digital conversations and trends](/accelerators/#marketing|socialbot)
- [DemandIQ Predict trends accurately and optimize inventory management](/accelerators/sigmoid-demandiq/)
- [NetworkIQ Track and optimize logistics operations in real-time to quickly address disruptions](/accelerators/sigmoid-networkiq/)
- [SupplyIQ End-to-end platform to optimize supply chain operations](/accelerators/sigmoid-supplyiq/)
- [ProcurementIQ Automated procurement operations for maximum savings, compliance and efficiency](/accelerators/sigmoid-procurementiq/)
- [RapidML Accelerated deployment for machine learning models](/accelerators/sigmoid-rapidml/)
- [DataGuard Comprehensive platform for proactive data quality management](/accelerators/data-quality-tool-sigmoid-dataguard/)
- [CloudPulse Cloud cost optimization platform with multi-cloud management](/accelerators/sigmoid-cloudpulse/)
- [RAPID GenAI foundation with built-in governance and cost clarity](/accelerators/sigmoid-rapid/)
- [AnalyticsBot GenAI based platform to streamline decision-making in analytics](/accelerators/sigmoid-analyticsbot/)
- [DataConnect Seamlessly ingest, integrate and harmonize data from diverse sources](/accelerators/sigmoid-dataconnect/)
- [Reconica AI-powered data harmonization and reconciliation engine](/accelerators/sigmoid-reconica/)
- [ConverseBot GenAI driven insights generation for automated insights from reports](/accelerators/#sales|conversebot)
- [iNRM Cross-lever revenue growth optimization platform](/accelerators/sigmoid-inrm/)
- [AssortmentIQ Optimize shelf layouts and assortment mix at scale with AI-based insights](/accelerators/sigmoid-assortmentiq/)
- [Read Whitepaper](/ebooks-whitepapers/building-agentic-ai-chatbots-for-business-process-transformation/)
- [Listen Podcast](/events/podcast/how-jack-in-the-box-is-redefining-personalization-and-supply-chain-with-ai/)
- [Blogs](/blogs/)
- [White Papers](/ebooks-whitepapers/)
- [Case Studies](/case-studies/)
- [Podcast](/events/podcast/#Podcasts)
- [Read Blog](/blogs/the-genai-adoption-triad-responsibility-ethics-and-explainability/)
- [ConverseBot](/accelerators/#sales|conversebot/)
## Tags
- AI/ML
- Cloud Transformation
---
## Footer Links
- [Talk to our AI experts](/contact-us/)
- [AI Strategy](/enterprise-ai-strategy/)
- [Agentic AI](/agentic-ai-solutions/)
- [Generative AI](/generative-ai/)
- [AI Managed Services](/ai-managed-services/)
- [Responsible AI](/responsible-ai-in-enterprise/)
- [Advanced Analytics](/advanced-data-analytics-solutions/)
- [Data Strategy](/data-analytics-strategy//)
- [Data Engineering](/data-engineering/)
- [Data Management](/ai-data-management-services/)
- [Cloud Transformation](/cloud-transformation/)
- [Data Ops](/data-devops/)
- [Data Visualization](/data-visualization-service/)
- [Automated Insights](/automated-insights/)
- [BI Migration](/bi-migration/)
- [Data Modeling](/data-modeling-services/)
- [Data Observability](/data-observability/)
- [CPG & Retail](/industries/cpg-analytics/)
- [Financial Services](/industries/banking-financial-analytics-services/)
- [Life Sciences](/industries/life-sciences/)
- [Case Studies](/case-studies/)
- [Thought Leadership](/ebooks-whitepapers/)
- [Blogs](/blogs/)
- [Company](/about-sigmoid/)
- [Newsroom](/newsroom/)
- [Accelerators](/accelerators/)
- [Careers](/careers/)
- [Privacy Policy |](/privacy-policy/)
- [Cookie Policy](/cookie-policy/)