Introduction to Generative Adversarial Networks
Reading Time: 4 minutes

Generative Adversarial Networks (GANs) was first introduced by Ian Goodfellow in 2014. GANs are a powerful class of neural networks that are used for unsupervised learning. GANs are based on deep learning and can create anything based on what you feed them, as they Learn-Generate-Improve. Some advanced applications of GANs are Conditional GAN (cGAN), Cycle GAN, Stack GAN, and Pix2Pix. GANs are considered one of the most intriguing trends in deep learning. In this blog, we will look at the basics of GANs and one of its advanced versions i.e Pix2Pix.
What makes up GANs
GAN comprises of a forger network (Generator) and an expert network (Discriminator), each being trained to beat the other. As such, a GAN is made of two parts:
- Generator network—Takes as input a random vector (a random point in the latent space), and decodes it into a synthetic image
- Discriminator network (or adversary)—Takes as input an image (real or synthetic), and predicts whether the image came from the training set or was created by the generator network.
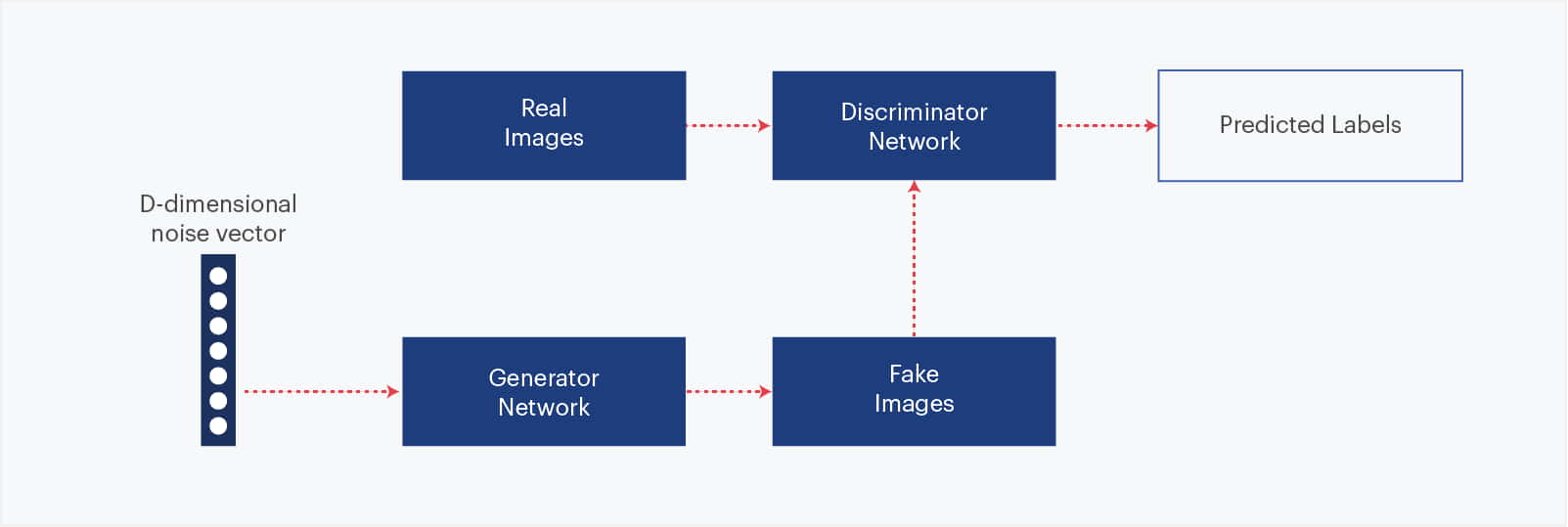
Credit- O’Reilly
A simple representation of GANs
How they work
Starting from what is usually no more than a vector of random numbers, the Generator learns to produce realistic-looking examples. It does so indirectly, through the feedback it receives from the Discriminator’s decisions. Each time the Discriminator is fooled into classifying a fake image as real, the Generator knows it did something well. And each time the Discriminator correctly rejects a Generator-produced image as fake, the Generator knows it needs to improve.
The Generator & Discriminator Tug of War
The Discriminator continues to improve as well: For each classification it makes, it is given feedback whether its guess was correct or not. So, as the Generator gets better at producing realistic-looking data, the Discriminator gets better at telling fake data from the real. Both the networks continue to simultaneously improve through this cat-and-mouse game.
The generator network is trained to be able to fool the discriminator network, and thus it evolves toward generating increasingly realistic images as training goes on: artificial images that look indistinguishable from real ones to the extent that it’s impossible for the discriminator network to tell the two apart. Meanwhile, the discriminator is constantly adapting to the gradually improving capabilities of the generator, setting a high bar of realism for the generated images. Once training is over, the generator is capable of turning any point in its input space into a believable image.
What is explained above will produce any random output given random noise vector as input. It is entirely possible to control whatever the generator network gives as output. This task can be achieved using Conditional GANs. For example, look at the image below. We give 7 as input along with a random noise vector into our GAN which is conditionally trained on MNIST dataset. By ‘conditionally’, we mean that we give the labels of the input MNIST image in both discriminator and generator along with giving the real images and random noise respectively.
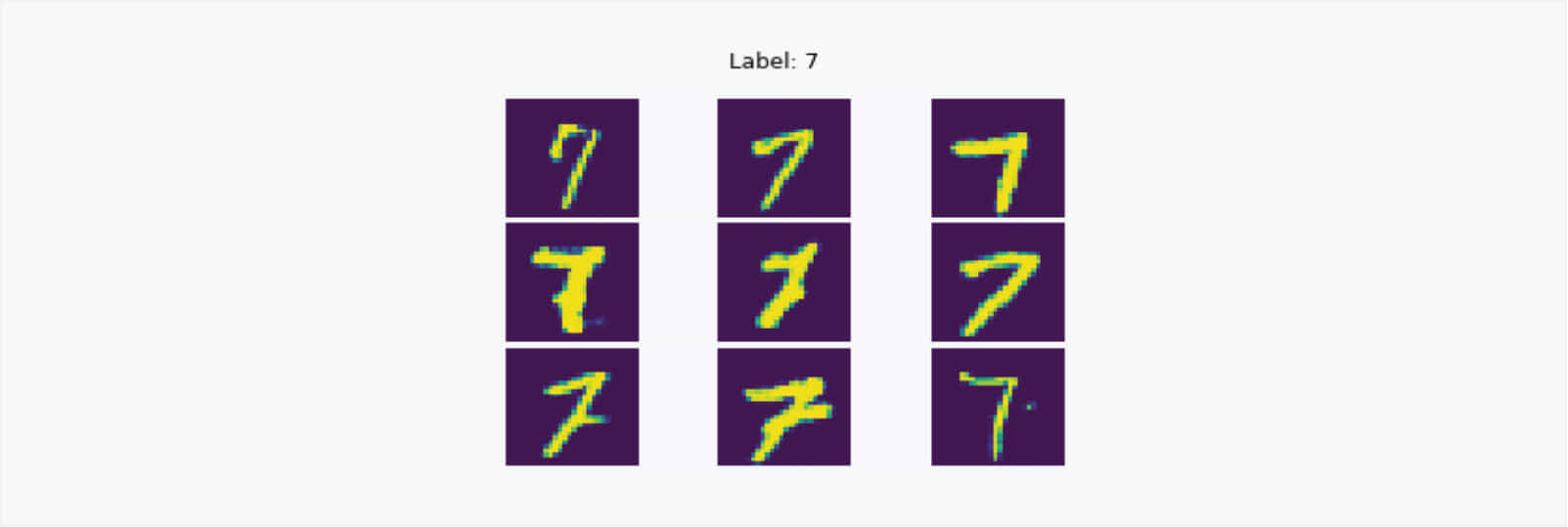
Output of the cGAN when we give Label ‘7’ as an input along with a random noise vector to the generator
Pix2Pix
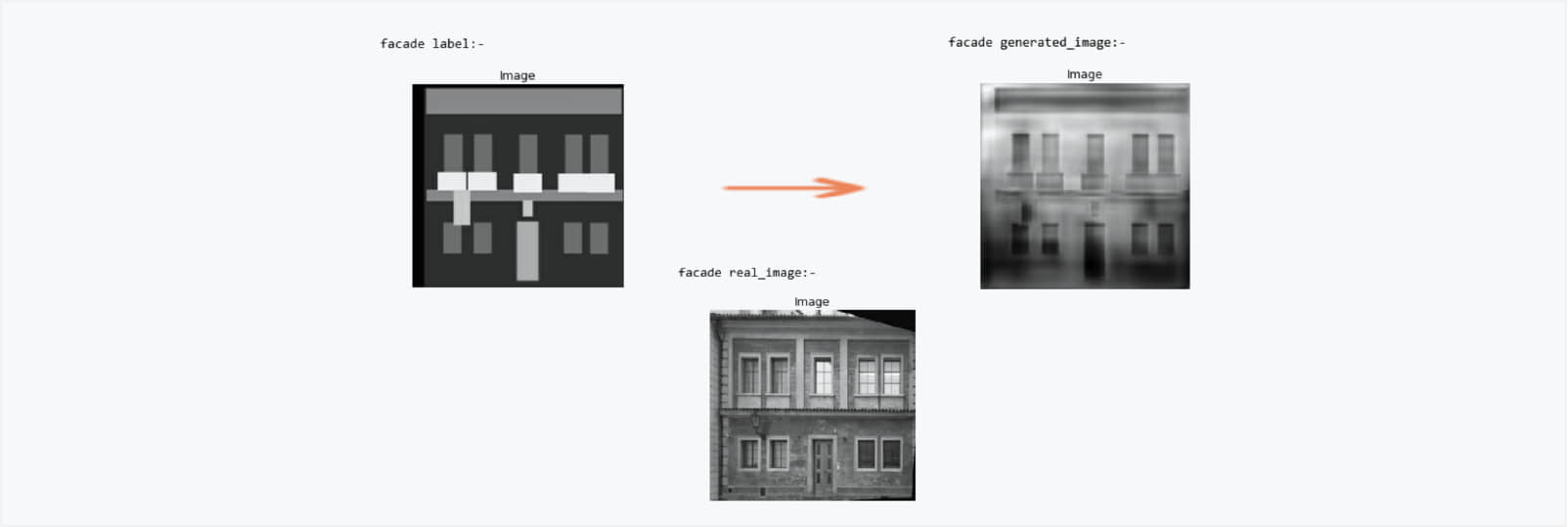
With GANs and deep learning, the above-generated image was produced in just 35 epochs of training. With more epochs, you will get better clarity in the generated images. This is just a facade label example. We can play around the readily available datasets here.
With the huge potential of GANs to generate real-looking “fake” images/data, there are concerns about their misuse. In the future, there will be restrictions on how GANs are used. Despite that, the ethical usages far outweigh the unethical ones.
About the Authors
Manish Kumar was a Data Scientist at Sigmoid. Saurabh Chandra Pandey was a Data Science intern at Sigmoid.
Featured blogs






Featured blogs