The Quantum Supremacy Experiment
Reading Time: 4 minutes

As a continuation of our previous blog about Quantum Computing and Quantum Supremacy, we have tried to explain the what, why and how of the experiment performed by Google as mentioned in this paper, where they have claimed to have achieved Quantum Supremacy. If you are not familiar with Quantum Computing, we recommend you to go through our previous blog first!
In a nutshell, Google’s experiment can be split into these 3 components:
- Generation of a pseudo random number
- Consisted of a quantum circuit with a random sequence of a single or 2 qubit logical operations (gates)
- But more random numbers is challenging
- Random sampling of the generated numbers
- Another quantum circuit
- Sample verification to check whether it was truly random
- This was done by computing the probability that a given random number appears in a sequence sample and verify if it appeared often
And to achieve this they have designed and calibrated a special quantum processor. Let us unravel each of these aspects!
Quantum Processor for Quantum Supremacy
For many years now, physicists have been investing tremendous amounts of time and effort to explore the power of quantum computing, but is it really worth it? To answer this question, Google came up with an experiment that is considered to be an important milestone in this field. They developed a new 54-qubit processor, named “Sycamore”, that is made of fast and high-fidelity quantum logic gates, to perform benchmark testing.
For stating quantum supremacy, technical advances — such as implementing advanced quantum processors — were made to contribute to the error correction. They executed fast, high-fidelity gates simultaneously on a 2D qubit array. The special processor was calibrated at both component and system level, for which a new tool called Cross-Entropy Benchmarking (XEB) has been created to compare the changes with its ideal probability calculated experimentally via simulation on a classical device. Component level fidelities were used to check on the performance of the whole system.

Quantum Supremacy Experiment
To demonstrate quantum supremacy, researchers compared their quantum processor against the state-of-the-art classical computers in a task of sampling the output of a pseudo-random quantum circuit. “Random” circuits are a suitable choice for benchmarking because they lack structure, and therefore, allow for limited guarantees of computational hardness.
The circuits were designed by repeated single-qubit and two-qubit logical operations, to entangle a set of qubits. Sampling the quantum circuit’s output produces a set of bit-strings whose probability distribution, due to quantum interference, resembles a patchy intensity pattern produced by light interference in laser scatter, where the probability of occurrence of some bit-strings is higher than others. For a circuit, they computed linear XEB fidelity and collected the measured bit-strings {xi} which is the mean of the simulated probabilities of the bit-strings:
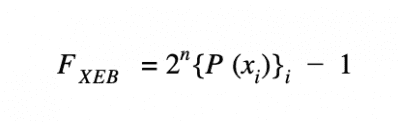
Where, n : number of qubits and P (xi): probability of bit-string xi computed for the ideal quantum circuit and the average is over the observed bit-strings. F XEB is correlated with how often we sample high probability bit-strings. In case of no errors, F XEB will be 1. The probabilities P (xi) were obtained from classically simulating the quantum circuit.
The goal was to achieve a high enough F XEB for a circuit with sufficient width, depth and low error rates, such that the classical computing cost is prohibitively large. As a result, their machine performed the target computation in 200 seconds, which would have otherwise taken 10,000 years for the world’s fastest supercomputer to produce a similar output.
Conclusion
The quantum supremacy experiment and research done till date for developing quantum computers have shown a pathway into a multitude of applications of quantum computing including machine learning, encryption, security, data generation, optimization, etc. Use of advanced quantum processors has further advanced research in this space.
Quantum computing can help us in significantly reducing the computational time as compared to working on classical computers. In the machine learning domain, development is still in process, and various researchers are developing the existing ML algorithms for quantum computers from scratch. The ‘Qiskit’ library is already in the making, which you can find on IBM Q Experience, where some of the basic ML algorithms have already been implemented and can be run on your devices with simulator-backend as well as IBM Q machine-backend. In the upcoming blogs, we’ll be covering the current state of Quantum computers, it’s scope and applications, what Quantum Machine Learning is, how we can make some ML algorithms work in the quantum environment, and our contributions to the Quantum world.
References
- Quantum supremacy using a programmable superconducting processor
- Quantum Supremacy explained by a youtube
About the Author
Aniruddh Rawat is a Data Scientist at Sigmoid. He works with data and application of Machine Learning algorithms. Currently he is focusing on Quantum Machine Learning, Recommendation Systems.
Featured blogs







Featured blogs