Getting data into Spark Streaming
Reading Time: 6 minutes

In the previous blog post we talked about an overview of Spark Streaming, and now let us take a look on different source systems that can be used for creating Spark Streams.
Spark Streaming provides out of the box connectivity for various source systems. It provides built in support for Kafka, Flume, Twitter, ZeroMQ, Kinesis and Raw TCP.
This blog serves as a guide for using and choosing the appropriate source for a Spark Streaming application. It also shares the steps needed to connect to the required system. The selection of the source system depends on the use case/application.
We need a basic machine set up to connect to any of the source systems, you can follow our Spark installation for the set up.
We will look into various source systems in detail, starting with Kafka as it is the most commonly used for Spark streams.
Sources for Spark Streams
Kafka
Kafka is available under Apache Licence. It provides a Distributed, Reliable Topic based Publisher-Subscriber Messaging System. If you are just starting with streaming, the above sentence may seem too complicated, let’s break it down.
Distributed – Kafka can run on a set of servers called brokers. The brokers replicate data among themselves. This distributed architecture allows Kafka to be scalable.
Publisher-Subscriber System – It provides a topic based streaming system for Apache Spark Streaming to process. Consumers can subscribe and get messages from a topic.
Reliable – Messages passed to Kafka are persisted on disk and replicated to prevent loss of Data.
Also, Kafka guarantees to preserve the order of messages received from a producer i.e. messages received from a producer are logged and passed downstream in the order the messages are received.
Once you have Kafka running on a cluster you can use the createStream method to access data from Kafka.
Below is the API reference for KafkaUtils[1].

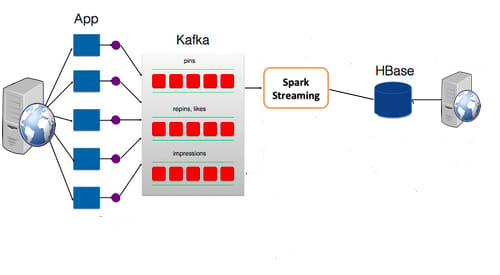
Application
At Sigmoid, we have used Kafka for implementing Spark Streaming for an Online Advertising Optimization System. The requirement is to pick the most suitable ad for a user, the one which is most likely to be clicked by him. Many websites which are clients to this Advertisement Optimization system push messages to the Kafka Cluster via a Kafka Producer. The output of the Kafka stream is written to a HBASE database or any other distributed database, to be read by the client. The system is pretty stable and scales well when the load grows. Such a system allows one to find the effectiveness of a campaign in real-time.
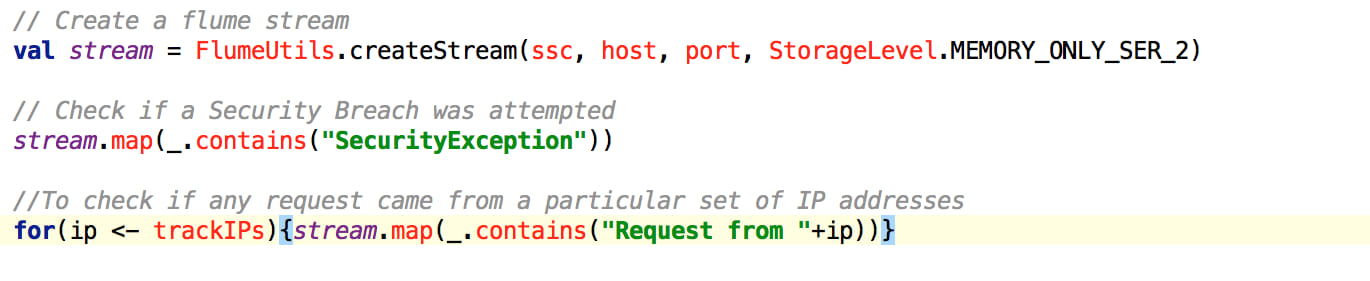
The code below depicts how you can use Kafka to create a Stream of Data, and generate the probabilities for various advertisements being clicked.
Flume is designed to pull data from various sources and push it in HDFS whereas Kafka is designed to provide data to many systems, where HDFS could be one of the systems.
Flume
Like Kafka, Flume is also available under Apache Licence and is a distributed, reliable system for collecting, aggregating and moving large amounts of log data from variable sources to a centralized data source. It is similar to Apache Kafka, in being distributed, reliable and a ready to use messaging system. But Kafka is usable in a wider number of use cases. Flume was initially designed for log processing but can be used in any real time event processing systems.
Distributed – Flume runs on a cluster, which allows it to be scalable
Reliable – Events passed to the stream are deleted only when the events have been stored in the channel of the next agent.
Recoverability – Events are staged in a channel, which is backed by a local file system. The events generated during system outage cannot be recovered. But Flume can restore all the events which are already received and can get those events processed in Spark Streaming.
If the flume cluster is already running, you would need to connect to it from your spark streaming code. FlumeUtils can be used to create a stream of data.
Below is the API reference for FlumeUtils[2].

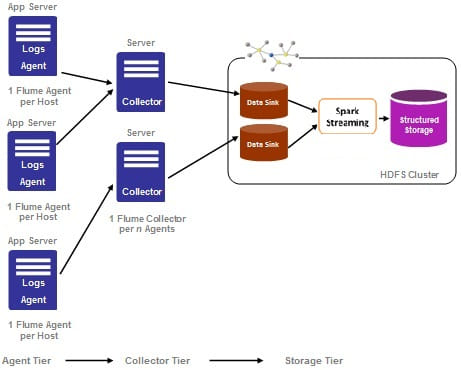
Application
Log analysis is useful to detect system faults, failures, security attacks using which remedial action can be taken before service quality degrades. Spark Streaming allows to analyze logs in real time and allows the user to implement real-time log analytics. Flume is often used to process logs for analytics purpose.
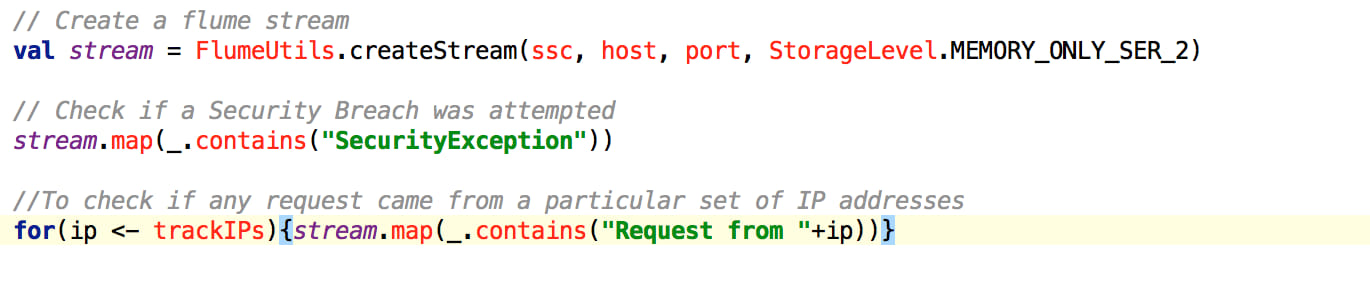
The code below depicts how you can create a Stream of data from Flume and create a stream of alerts if anything suspicious is found in the logs.
Flume is designed to pull data from various sources and push it in HDFS whereas Kafka is designed to provide data to many systems, where HDFS could be one of the systems.
MQTT (Message Queue Telemetry Transport)
MQTT is a widely used simple and lightweight messaging protocol. It implements a Publisher subscriber messaging system. It is designed for small devices with limited memory, unreliable networks, low bandwidth, like mobile devices. It is suitable for Internet of Things (IoT) use cases.
Similar to Flume and Kafka, Spark Streaming provides a library for MQTT connectivity also. You can use MQTTUtils to connect to an existing and running MQTT Stream.
Below is the API reference for MQTTUtils[3].

Application
Vehicle driver monitoring applications analyze various data points and come up with suggestions for you to improve your driving skills, get better mileage from your vehicle. Such systems record and transmit the vital parameters of your vehicle to a streaming system, the streaming system performs the various computations on the data to generate usable data points. A lightweight queue can be used on such a device to transmit events to Spark streams.
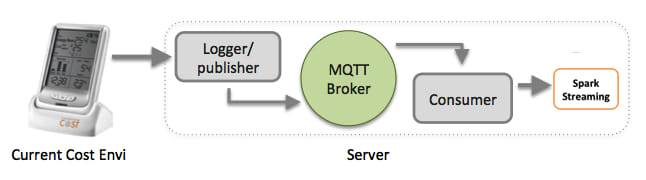
The code below depicts how you can create a Stream using MQTT utils and use that stream to check if the gear used is optimal.

ZeroMQ
Kinesis is a managed service, therefore, the user does not have to think about how to process data simultaneously but concentrate more on the logic of processing this data. Plug-in your code for processing the data and let Kinesis handle the processing for you. Since it is managed by Amazon it is more stable and scalable than any of the systems discussed, but it does not allow the type of flexibility as you can have with Kafka or any other systems.
For connecting to a Kinesis Store from Spark Streaming use KinesisUtils.
Applications
Applications discussed for Flume or Kafka are applicable for Kinesis.
- Click streams from websites: Customers can be provided with real-time analytics of their websites
- Stock market firms: can make use of the real time data coming in, helping them know the trends of the industry
Spark streaming can connect to any other Source system using custom receivers and an API to communicate with the system.
The table below is to summarize the features we have covered above in this blog.
| Feature/Source | Kafka | Flume | MQTT | ZeroMQ | Kinesis |
|---|---|---|---|---|---|
|
Open Source/Proprietary |
Open source – Apache | Open source – Apache | Open source – Eclipse | Open source – Mozilla Public License | Proprietary – Amazon |
|
Light Weight |
No | No | Yes | Yes | No |
|
Distributed |
Yes | Yes | No | N/A | Yes |
|
Messaging Component |
Messaging System | Messaging System | Messaging System | Messaging Library | Messaging System |
|
Advantages |
Widely accepted architecture, suitable for any source type | Suitable for log processing | Fits the IoT use case, can be used to perform many IoT applications | Provides a messaging library, flexibility to the user to implement any mechanism for the messaging queue | Provides a scalable queue for event processing |
Application |
General scalable stream processing | Log processing | IoT, mobile devices, Lightweight, event processing | IoT, mobile devices, Lightweight, event processing | General scalable stream processing |
About the Author
Arush was a technical team member at Sigmoid. He was involved in multiple projects including building data pipelines and real time processing frameworks.
Featured blogs






Featured blogs