Building modern data architecture with data lake
- Chapter- 1 Introduction
- Chapter- 2 What is data lake
- Chapter- 3 Data lake architecture
- Chapter- 4 Data lakes & data warehouses: The difference
- Chapter- 5 Comparing key data lake models
- Chapter- 6 Best practices for building data lake architecture
- Chapter- 7 Accelerating the analytics journey with cloud data lake
1. Introduction
The success of a business in the digital age depends on how well it capitalizes on the available data and its ability to deliver real-time insights at the point of action. This means that companies need to ensure ease of data access for stakeholders while maintaining data quality. And the good news is that companies are fast taking note.
Research from BI Survey reveals that almost half of the future-facing enterprises have understood the obvious benefits of data with 48% of them assigning a high value to information (data) to enable decision making. Another 46% of the respondents stated that they are treating data as a valuable asset worth storing and processing for future business benefits. Given this inclination to derive value out of the available data, it is crucial for businesses to look for data storage options that can enable them to quickly ingest, store, fetch, and analyze the available data for real-time decision-making. And it is here where data lakes can help organizations gain a competitive edge by helping them store and maintaining the processing capacity of data.
2. What is data lake
A data lake is essentially a centralized data repository platform that allows organizations to efficiently store data and leverage tools to perform tasks ranging from exploring data to running advanced analytics on large and varied datasets. A data lake is governed by a particular standard that facilitates lineage tracking, security enforcement, and centralized auditing.
3. Key components of a data lake architecture
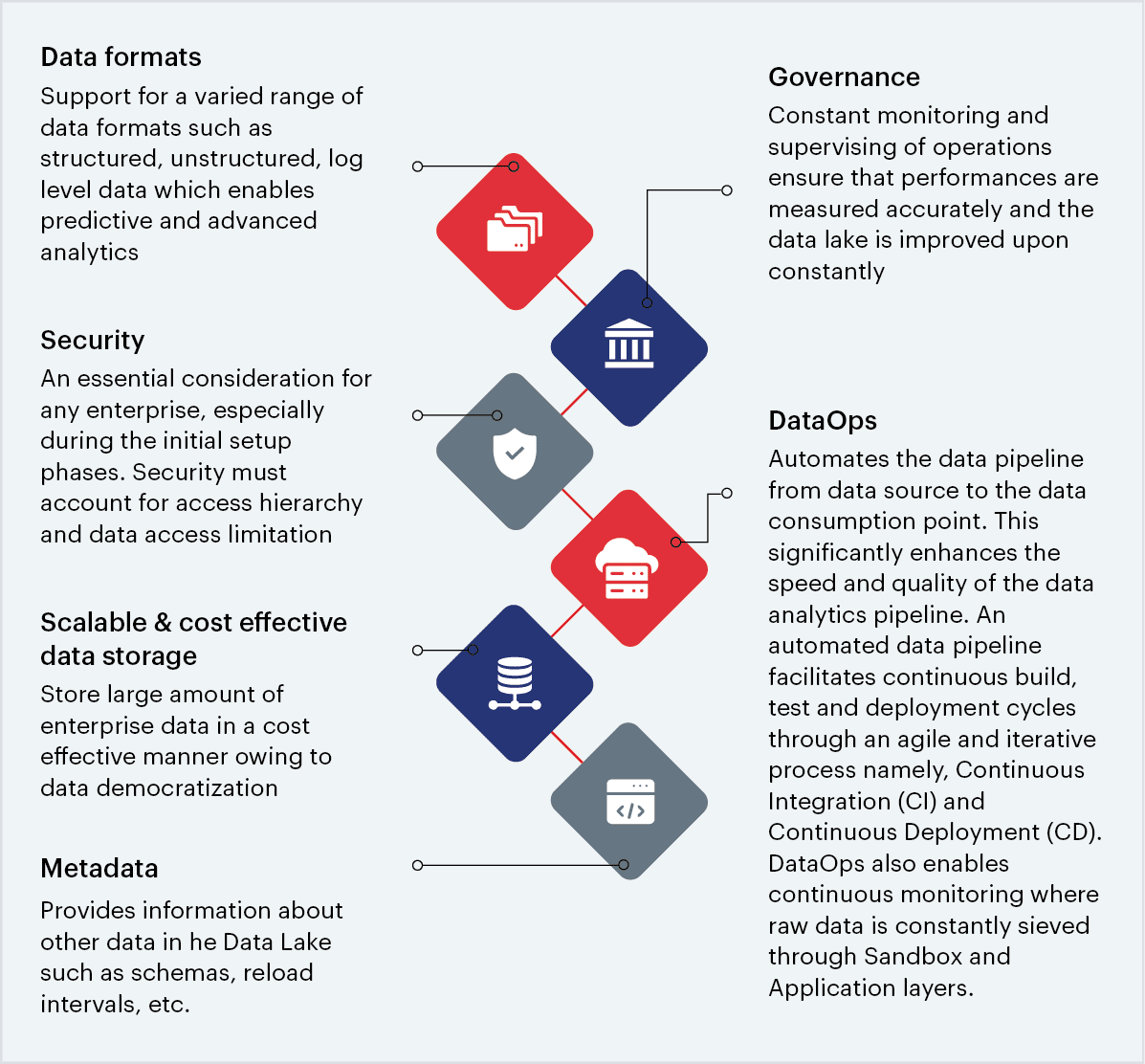
Fig 1: Data lake architecture components
3.1 The advantage of cloud data lakes
The most axial benefit of a data lake is the centralization of disparate data sources. Data can be collated from multiple silos to form a unified source of truth. Big data, search, and analytics techniques can then combine and process these sources which are otherwise not possible.
The flexibility offered by data lakes enables enterprises to apply suitable security measures to protect any proprietary information and set up access levels. Security levels can also provide granular control which grants the user access to any information without the visibility of the source of the data. This can be beneficial under numerous circumstances such as the non-applicability of data source, licensing limits of the original content source, or the presence of obsolete or decommissioned data sources.
The accessibility of data lakes makes normalization and enrichment of the data an easy process. Data preparation practices such as indexing, de-normalization, metadata extraction, aggregation, format conversion, cross-linking, augmentation, or entity extraction are all simplified. This established method of data preparation also helps optimize costs by reducing upfront data preparation charges.
Moreover, the flexibility of access facilitated by data lakes allows organizations to collect data from anywhere around the globe and promote content re-usage to drive critical business decisions. On the whole, data lakes can foster data democracy within an organization and foster agility and innovation throughout.
4. Data lakes & data warehouses: The difference
Data lakes can act as the cornerstone of a modern big data architecture but they are not synonymous with data warehouses despite their similarity in terms of basic purpose and objective. There are of course, significant differences between the two.
| Data lakes | Data warehouses | |
|---|---|---|
|
Structure of data |
Raw – Often requires larger storage capacity |
Processed – Requires comparatively lesser storage |
|
Purpose |
Undetermined – Raw data flows in to either cater to a specific utilization objective or simply for storage |
Being utilized – All data is stored with specific utilization in mind |
|
Users |
Data scientists/Data experts – Needs specialized tools to translate raw data for specific business usage |
Business professionals – Most employees can read and use the processed data to be used for charts, tables, spreadsheets, and more |
|
Accessibility |
Accessing and changing data is easier and faster due to a lack of structure and few limitations |
Data is well structured making data manipulation cumbersome and costly |
A data lake acts as a centralized repository where all data can be stored at any scale. The data can be stored as-is, i.e. a raw and granular format and it can have various levels of structuring (structured, unstructured, or semi-structured) along with metadata tags and identifiers for quicker retrieval. This makes the data highly flexible for future use and ideal for analytics. In most cases, data lake configurations are made on commodity hardware that is both scalable as well as inexpensive. These clusters can either be on-premises or entirely on the cloud. There are a few key attributes of a big data repository to be classified as a data lake:
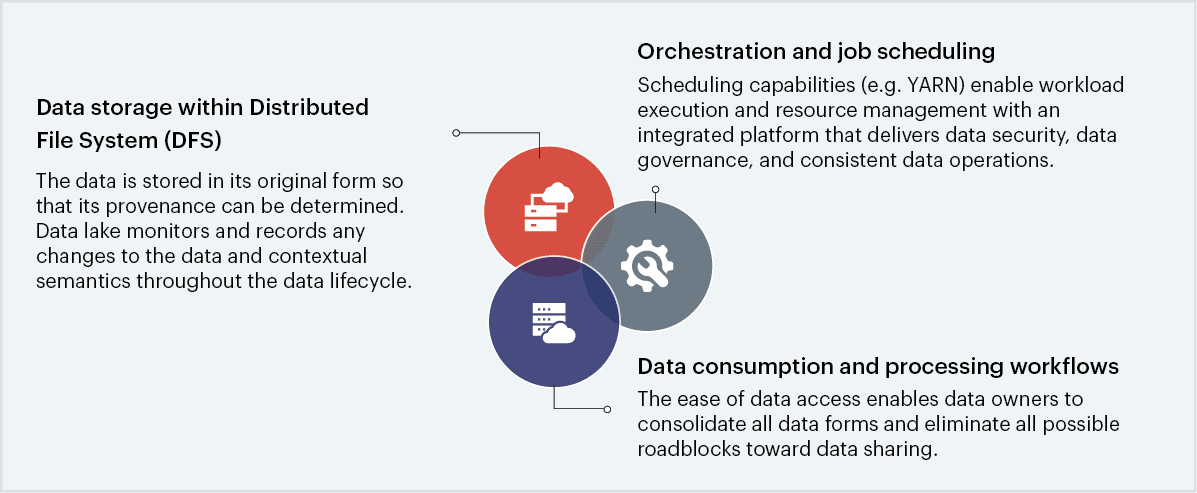
Fig 2: Attributes of a big data repository to be classified as a data lake
Know more about building modern data architectures
5. Comparing key data lake models
Data lakes can either be built on-premises or on the cloud, depending on the requirement. However, given the flexibility and scalability that the cloud offers, currently, it is mostly preferred for data lake deployments. Organizations that already possess on-premise data lakes but are contemplating shifting to the cloud may find the migration process quite challenging. They need to first figure out the right way to shift the vast amounts of existing data and then determine the right data lake architecture. The following are the key options that organizations have when it comes to data lake architectures:

On-premise data lake
With an on-premise data lake, companies are often required to manage both the infrastructure and hardware – management of batch ETL jobs, allocation of local servers, reduction of downtime, and so on. From a software standpoint, data engineers need to leverage a wide range of advanced data management tools in order to ingest, categorize, process, and query the data stored in the data lake. In order to maintain on-premise data lakes, companies need to make upfront investments in order to procure additional servers and storage equipment which often manifests in additional IT and engineering costs. As far as scalability is concerned, companies need to manually configure and add additional servers in case there is a need to support more data users or manage larger volumes of data.
Cloud data lake
Cost efficiency, storage availability, reduced IT and data engineering costs are some of the key aspects that make cloud the most favorable option for data lake commissioning. Cloud allows companies to operate in an agile manner without the need to align every data-related decision-making with capability. With the cloud, companies can eliminate the need to build and nurture a dedicated infrastructure and allocate engineering resources to develop new business functionality. Cloud platforms also come embedded with high-end tools that can help companies build robust data pipelines. In most cases, the pipelines are often pre-built so data teams can come up with a working solution without spending several hours in data engineering. In the AWS cloud data lake platform, for instance, resource management is handled with multiple data ingestion tools including Kinesis Streams, Direct Connect, Snowball, and Kinesis Firehose. They allow the transfer of very large volumes of data to the Amazon S3.
Besides creating a cloud-native data lake, companies have the option to implement other cloud data lake models, based on the requirement such as:
Hybrid data lake: Maintaining both cloud and on-premise data lake comes with its very own challenges and benefits. Managing an on-premise data management operation requires additional engineering expertise, as does the constant migration of data from on-premise to the cloud. This two-pronged approach offers a major benefit though. It allows companies to store less important data on-prem while transferring more critical data to the cloud where it can be quickly made analytics-ready.
Multi-cloud data lake: This data lake architecture allows companies to take the advantage of multiple cloud offerings combined. For instance, companies embracing hybrid cloud data lake architecture can leverage both Azure and AWS to create data models and manage the same. While the hybrid model can be ideal for companies looking to reap the advantages of more than one cloud platform, it also requires more expertise to enable seamless communication between two functionally disparate platforms.
Custom built scalable data lake (using open-source technologies)
The open-source data lake model can be an ideal option for companies looking to create a cloud-native yet cloud platform service agnostic data lake or analytics solution. Today a growing number of organizations seek flexibility when it comes to implementing data-driven solutions on any of the available public/private cloud platforms. And the availability of open-source tools makes this a possibility. For instance, an organization can leverage the Kubernetes open-source platform as a foundation for a data lake thereby gaining the flexibility to move it to any public, private, or hybrid cloud platform. Also, it can implement other open-source tools to optimize specific data lake functions on the basis of requirements- a combination of Presto and Hive meta-store can be utilized for data querying, Apache Airflow can be utilized for workflow management, Spark for ETL requirements, Docker for image registries, Git for CI/CD pipelines and so on.
6. Best practices for building data lake architecture
It can be stated that Data lakes serve as the cornerstone of modern big data architecture, but enterprises need to tread carefully and follow some best practices that will enable them to design a robust data lake, rather than weighing down on IT departments with technical debts.
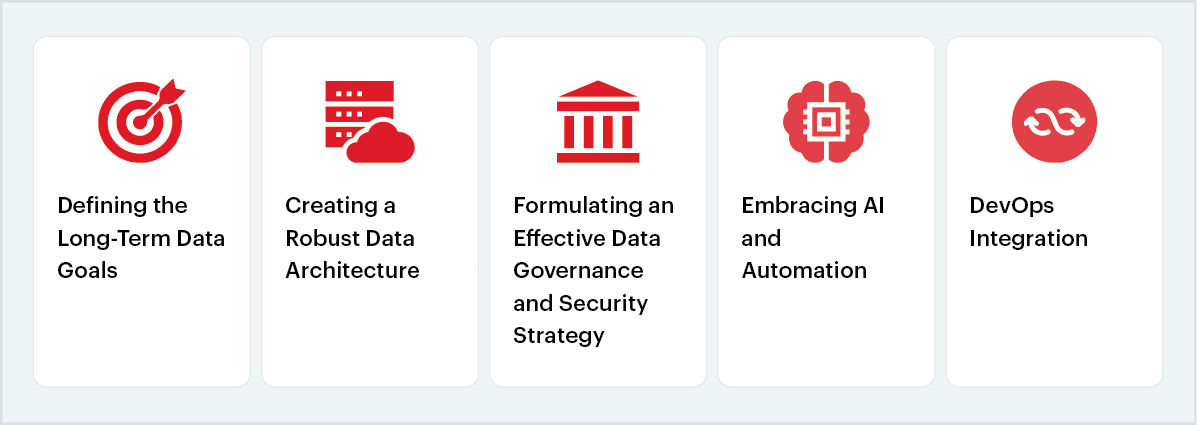
Fig 3: Best practices to develop a data lake
1. Defining the long-term data goals
The first step is to clarify and outline an organization’s data strategy and desired outcomes. Instead of simply gathering massive amounts of data, organizations should focus on formulating a clear data strategy to avoid data silos, scale up, and foster an information-driven culture. Clearly defining a long-term data goal can help companies drive data strategies and activities and incrementally enhance processes through which data is managed.
2. Creating a robust data architecture
The rewards of a well-structured data architecture include operational efficiencies, actionable business insights, and the opportunity to capitalize on alternative business opportunities. And, it goes without saying that any effective data strategy needs to be underpinned by a strong data architecture that includes rules governing structured databases and the systems connecting data with the business processes that consume the same.
Organizations need to adopt updated data workflows to create a strong data architecture through processes like data profiling, data cataloging, data backup, and archiving.
3. Formulating an effective data governance and security strategy
Datasets can be effectively stored in data lakes through profiling, cataloging, and backup. But without a stringent data governance policy, data teams would find it difficult to find and use the required data sets. A thoroughly governed data lake comprises clean and usable data from both structured and unstructured sources that can be easily identified, accessed, managed, and protected. This is why a robust and effective data strategy must account for metadata management and data governance which can uphold optimum data quality that translates to consumption confidence for the business users.
4. Embracing AI and automation
The best way to enhance the performance of a data lake is by automating the data pipeline – starting from data ingestion and updating to creating analytics-ready datasets for visualization. Organizations need to systematically leverage AI and automation to enable better classification, analysis, and learning from a diverse dataset coming in at a fast pace. Automation infuses agility within the data lake management process helping companies mitigate data swamps, implement ready-reference architectures, ensure robust governance, automate legwork, and most importantly, create a data-friendly culture for the organization.
5. Integrating DataOps
Contemporary data management initiatives require the seamless movement of data between all the key business processes and stakeholder touchpoints. This process needs to be underpinned by automation-based monitoring in order to ensure constant uptime. It is here where DataOps- the application of DevOps to data management practices, can help data teams set clear guidelines regarding the process of data collection and the location from where the data is generated.
7. Accelerating the analytics journey with cloud data lake
When designed and deployed systematically, cloud data lakes can help accelerate an organization’s journey towards embracing actionable analytics through value-added data innovation and exploration. There are several aspects that make cloud data lakes a convenient data storage option for companies looking to leverage technologies like AI and ML to solve use cases.
Data stored in cloud data lakes are often in raw formats and they are not pre-configured when they enter company systems. This makes the data highly usable and it can be leveraged beyond just basic data capturing operations. Data scientists and data teams, for instance, conducting the exploratory analysis can find and access data quickly in a data lake, irrespective of the format. A thoroughly governed “raw data repository” can serve as a gold mine for data scientists looking to create a robust and effective analytics program. And, as companies extend the use of data lakes beyond small, low-value pilot projects, they will have the upper hand to create ‘self-service’ options for data users where they can generate their own data reports and insights. Take the case of a leading American multinational consumer products company that collaborated with Sigmoid to harness real-time insights into sales trends through data lakes.
7.1 Case study:
Building a data foundation for automated data ingestion and reporting

Business challenge
The client is a leading CPG firm operating in the domains of oral care and personal care. They didn’t have access to timely sales transaction data from retailers and wanted more insights on the latest trends across sales in different geographies. By leveraging the power of data from big retailers like Walmart, Amazon, and Target, among others, they wanted to generate fast, granular insights and automate reports’ download from the vendor’s dashboard. The absence of a central data repository meant that the process to access specific data from retailers was highly manual and had several missing data points for holidays and weekends. It took a week’s time to access particular data from the retailers. Moreover, this data was only available to certain members within the company, making it difficult for the people on the ground to understand how their business is doing.
Sigmoid solution
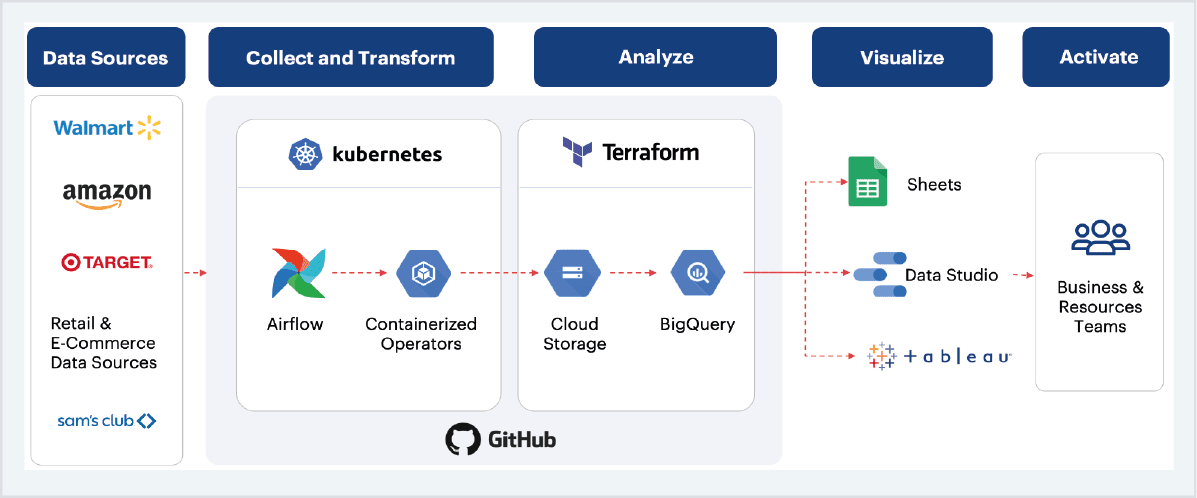
Fig 4: Solution architecture
Sigmoid created a Data Lake of the retailers’ data for the client that then enabled:
- Data harmonization between external sources and internal products and hierarchy
- Use of standard forex data for currency conversions across geographies
- Deduplication and reinstatement of the data
Before being sent to Google BigQuery. The older pipelines were monolithic, requiring manual interventions at various steps for currency conversion and aggregations. We performed data harmonization between external sources and internal products and hierarchy. A binary search was implemented to identify data discrepancies rather than performing a full scan. Additionally, our approach created several generic steps like drop rows/drop columns/remove characters, etc which can be used in different sources with the minimum development effort. We even automated the download of reports from the vendor’s dashboard and monitored the correct flow of data from the dashboard to BigQuery.
Business outcomes
The solution enabled the client with faster access to data, thereby reducing the time to get actionable insights. This fast and efficient data availability enabled them to forecast demand and fulfill order management requests. The enhanced reporting across retailers and geographies helped avoid stockouts and ensured that hundreds of users had access to the same quality data that was earlier accessible to only certain employees.
Conclusion
As businesses continue to rely on data from myriad sources for advanced analytics, the volume, velocity and complexity of the data that has to be managed, increases. Additionally, the increasing number of end users that depend on organizational data to generate the right insights in a timely manner, calls for modern data platforms that can store, scale and cater to the demands of advanced analysis in a cost effective manner.
When enterprises build robust data foundations with data lakes and end to end data pipelines, open source technologies are an ideal choice for smooth functioning of data operations, consistent access to quality data and reliable self serve analytics without much dependence on IT teams.