---
# Apache Spark for real-time analytics
**URL:** https://www.sigmoid.com/blogs/apache-spark-for-real-time-analytics/
Date: 2019-02-13
Author: Sigmoid
Post Type: post
Summary: Apache Spark is the hottest analytical engine in the world of Big Data and Data Engineering. Apache Spark architecture is largely used...Read More...
Categories: Data Management
Tags: Cloud Transformation
Featured Image: https://www.sigmoid.com/wp-content/uploads/2019/02/apache-spark-for-real-time-analytics.jpg
---
Apache Spark is the hottest analytical engine in the world of Big Data and [Data Engineering.](/ebooks-whitepapers/data-engineering-overcome-challenges-in-enterprise-analytics/) Apache Spark architecture is largely used by the [big data](/blogs/big_data_cloud_the_perfect_combination_for_business_transformation/) community to leverage its benefits such as speed, ease of use, [unified architecture,](/case-studies/unified-analytics-platform/) and more. [Apache Spark](/blogs/near-real-time-finance-data-warehousing-using-apache-spark-and-delta-lake/) has come a long way from its early years to today where researchers are exploring [Spark ML.](/blogs/improving-data-processing-with-spark-3-0-delta-lake/) In this article, we will cover Apache Spark and its importance, as part of Real-Time [Analytics.](/blogs/top-data-analytics-trends-to-watch-out-in-2021/)
[Apache Spark](/blogs/apache-spark-on-dataproc-vs-google-bigquery/) is an open-source fast engine, for large-scale data processing on a distributed computing cluster. It was initially designed at Berkeley University and later donated to the Apache software foundation. Spark can interactively be used from Java, Scala, [Python](/blogs/10-must-have-skills-for-data-engineering-jobs/), and R among others, and is also capable of reading from HBase, Hive, Cassandra, and any HDFS data source. Its interoperability and versatile nature make Apache Spark one of the most flexible and powerful [data processing](/blogs/improving-data-processing-with-spark-3-0-delta-lake/) tools available today.
Apache Spark architecture is well suited for data cleansing, data wrangling, and [ETL.](/etl-and-data-pipeline/) It has an advanced DAG execution engine that supports acyclic data flow and in-memory computing, which helps to run programs up to 100x faster than Hadoop MapReduce in memory. Spark is a multi-stage RAM-capable cluster-computing framework, which can perform both batch processing and [stream processing.](/blogs/fault-tolerant-stream-processing/) It has libraries for [machine learning,](/data-science-services/) interactive queries, and [graph analytics,](/industries/media-and-digital-advertising/) which can run in Hadoop clusters through YARN, MESOS, and EC2, while it has its own standalone mode. Spark batch processing applications provide high volume as compared to real-time processing, which provides low latency.
While using Hadoop for data analytics, many organizations figured out the following concerns:
- MapReduce Programming is not a good match for all analytics problems, as it isn’t efficient for iteration and interaction analytics.
- It was getting increasingly difficult to find entry-level programmers with good Java skills, to be productive with MapReduce.
- With the emergence of new tools and technology, fragmented data security issues emerged, which resulted in Kerberos authenticated protocol.
- Hadoop lacked full-feature tools for data management, data cleansing, governance, and metadata.
## Apache Spark solves the above concerns:
- Spark uses Hadoop HDFS as it doesn’t have its own distributed file system. Hadoop MapReduce is strictly disk-based, whereas Spark can use memory as well as the disk for processing.
- MapReduce uses persistent storage, whereas Spark uses Resilient Distributed Datasets (RDDs) which can be created in three ways: parallelizing, reading a stable external data source such as HDFS file, and transformations on existing RDDs.
We can process these RDDs using the operations like map, filter, reduceByKey, join and window. The results are stored in the data store for further analytics, which is used for generating [reports](/blogs/automate-data-ingestion/) and dashboards. A transformation will be applied to every element in RDD and RDDs are distributed among the participating machines. Partition in RDD is generally defined by the locality of the stable source and can be controlled by the user through Repartitioning.
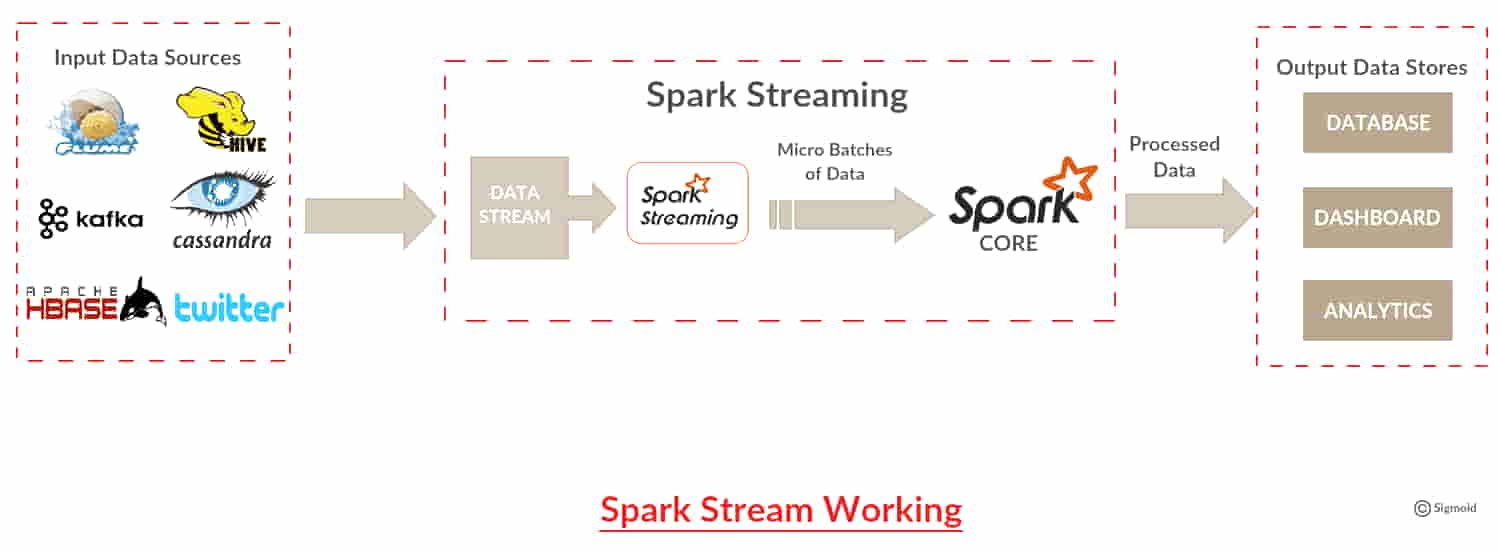
Time and speed are of key relevance when it comes to business decisions. To make relevant business decisions, [Big Data](/blogs/sigmoids_7_step_approach_for_project_success/) is ingested in [real-time](/blogs/automate-data-ingestion/) and insightful values must be extracted upon its arrival. So, there are different streaming data processing frameworks like Apache Samza, Storm, Flink, and [Spark Streaming.](/blogs/spark-streaming-internals/)
## Here are our top 5 picks of Apache Spark Streaming applications:
- Real-Time Online Recommendation
- Event Processing Solutions
- [Fraud Detection](/case-studies/fraud-detection/)
- Live Dashboards
- Log Processing in Live Streams
### Wrapping Up
Apache Spark Stream is most suitable for high speed and real-time analytics, which makes it the most sought-after technology in the [Big Data world.](/blogs/critical_exercise_that_guarantees_big_data_project_success/) Complex [machine learning](/machine-learning-operationalization-mlops/) algorithms are built and implemented on different streaming data sources through Apache Spark to extract insights and help detect anomalous patterns with real-time monitoring. Through the Spark Streaming library, it is now possible to process and apply complex business logic to these streams.
Apache Spark architecture allows a [continuous stream](/blogs/spark-streaming-production/) of data by dividing the stream into [micro](/blogs/microservices-based-architecture-key-to-scaling-enterprise-ml-models/)-batches called Discretized stream or Dstream, which is an API. Dstream is a sequence of RDDs that are created from input data or from sources such as Kafka, Flume, or by applying operations on other Dstream. RDDs thus generated can be converted into data frames and queried using Spark SQL. Dstream can be subjected to any application that can query RDD through Spark’s JDBC driver and stored in Spark’s working memory to query it later on-demand of Spark’s API.
So, now we understand how the [Spark Streaming](/blogs/spark-streaming-production/) library can be used for processing real-time data. This library is important for data processing, which plays a pivotal role in providing real-time insights.
## About the Author
Raghavendra is the Assistant Marketing Manager at Sigmoid. He specializes in content marketing domains, digital and social media marketing.
[lc_the_tags]
## Featured blogs
[lc_get_posts post_type="post"
posts_per_page="4" orderby="date" output_view="lc_get_posts_mycustom_view" output_number_of_columns="4"
output_wrapper_class="row" output_article_class="shadow" output_hide_elements="Excerpt"
output_excerpt_length="0" output_excerpt_text="Read More" output_heading_tag="span"
output_featured_image_format="thumbnail" output_featured_image_class="card-img-left" ]
## Share
[addtoany]
Subscribe to get latest insights
## Talk to our experts
Get the best ROI with Sigmoid’s services in data engineering and AI
## Suggested readings
[View all](/blogs/)

#### [Apache Spark on DataProc vs Google BigQuery](/blogs/apache-spark-on-dataproc-vs-google-bigquery/)
[Read blog](/blogs/apache-spark-on-dataproc-vs-google-bigquery/)

#### [How to Optimize Nested Queries using Apache Spark](/blogs/optimize-nested-queries-using-apache-spark/)
[Read blog](/blogs/optimize-nested-queries-using-apache-spark/)

#### [ETL on Cloud: How is cloud Transforming ETL for Big Data Analytics](/blogs/etl-on-cloud-transforming-big-data-analytics/)
[Read blog](/blogs/etl-on-cloud-transforming-big-data-analytics/)
---
## Categories
- Data Management
---
## Navigation
- [WordPress.org](https://wordpress.org/)
- [Documentation](https://wordpress.org/documentation/)
- [Learn WordPress](https://learn.wordpress.org/)
- [Support](https://wordpress.org/support/forums/)
- [Feedback](https://wordpress.org/support/forum/requests-and-feedback)
- [Sigmoid](https://www.sigmoid.com/)
- [Community](https://community.wpmanageninja.com/portal/space/fluent-forms/home)
- [Docs](https://wpmanageninja.com/docs/fluent-form/)
- [Developer Docs](https://developers.fluentforms.com/)
- [Documentation](https://imagify.io/documentation/)
- [Rate Imagify on WordPress.org](https://wordpress.org/support/view/plugin-reviews/imagify?rate=5#postform)
- [Manage](admin.php?page=litespeed)
- [Settings](admin.php?page=litespeed-cache)
- [Image Optimization](admin.php?page=litespeed-img_optm)
- [Company](/about-sigmoid)
- [Newsroom](/newsroom)
- [Life at Sigmoid](/careers)
- [Takshashila](/takshashila)
- [Contact Us](/contact-us)
- [AI Strategy Blueprint your AI advantage](/enterprise-ai-strategy/)
- [Generative AI Drive innovation with Generative AI](/generative-ai/)
- [Responsible AI Build trust with ethical AI practices](/responsible-ai-in-enterprise/)
- [Agentic AI Reshape business with scalable agentic systems](/agentic-ai-solutions/)
- [AI Managed Services Ensure reliable AI performance](/ai-managed-services/)
- [Advanced Analytics Transform your business with data-driven insights](/advanced-data-analytics-solutions/)
- [Start Assessment](/agentic-ai-readiness-index/)
- [Data Strategy Strong data foundations for scalable AI](/data-analytics-strategy/)
- [Data Management Leverage data as a strategic asset](/ai-data-management-services/)
- [Data Ops Automate data for speed and quality](/data-devops/)
- [Data Engineering Deliver insights faster with scalable pipelines](/data-engineering/)
- [Cloud Transformation Modernize data to maximise efficiency](/cloud-migration/)
- [Download Whitepaper](/ebooks-whitepapers/building-data-products-in-a-data-mesh-to-drive-business-value/)
- [Data Modeling Structure data for better decisions](/data-modeling-services/)
- [Data Visualization Transform data into actionable stories](/data-visualization-service/)
- [BI Migration Enhance decision making with modern BI tools](/bi-migration/)
- [Data Observability Build trust with healthy, accurate data](/data-observability/)
- [Automated Insights Make smarter decisions with auto-generated insights](/automated-insights/)
- [Download Whitepaper](/ebooks-whitepapers/power-bi-hacks/)
- [CPG & Retail End-to-end analytics for planning, operations, and commercial excellence](/industries/cpg-analytics/)
- [Life Sciences Trusted intelligence across clinical, commercial, and operational workflows](/industries/life-sciences/)
- [Financial Services AI-powered analytics for risk, compliance and customer experience](/industries/banking-financial-analytics-services/)
- [Read case study](/case-studies/data-clean-room-enables-real-time-insights-to-improve-operational-efficiency/)
- [MediaIQ Advanced platform for in-flight marketing measurement](/accelerators/sigmoid-mediaiq-multi-touch-attribution-tool/)
- [CampaignIQ AI-driven platform for optimized campaign budget allocation](/accelerators/sigmoid-campaigniq/)
- [AssistBot GenAI email assistant that automates human-like responses](/accelerators/sigmoid-assistbot-for-ai-email-assistant/)
- [CreativeBot GenAI tool for personalized and brand-aligned creative design](/accelerators/sigmoid-creativebot/)
- [SocialBot GenAI platform to analyze digital conversations and trends](/accelerators/#marketing|socialbot)
- [DemandIQ Predict trends accurately and optimize inventory management](/accelerators/sigmoid-demandiq/)
- [NetworkIQ Track and optimize logistics operations in real-time to quickly address disruptions](/accelerators/sigmoid-networkiq/)
- [SupplyIQ End-to-end platform to optimize supply chain operations](/accelerators/sigmoid-supplyiq/)
- [ProcurementIQ Automated procurement operations for maximum savings, compliance and efficiency](/accelerators/sigmoid-procurementiq/)
- [RapidML Accelerated deployment for machine learning models](/accelerators/sigmoid-rapidml/)
- [DataGuard Comprehensive platform for proactive data quality management](/accelerators/data-quality-tool-sigmoid-dataguard/)
- [CloudPulse Cloud cost optimization platform with multi-cloud management](/accelerators/sigmoid-cloudpulse/)
- [RAPID GenAI foundation with built-in governance and cost clarity](/accelerators/sigmoid-rapid/)
- [AnalyticsBot GenAI based platform to streamline decision-making in analytics](/accelerators/sigmoid-analyticsbot/)
- [DataConnect Seamlessly ingest, integrate and harmonize data from diverse sources](/accelerators/sigmoid-dataconnect/)
- [Reconica AI-powered data harmonization and reconciliation engine](/accelerators/sigmoid-reconica/)
- [ConverseBot GenAI driven insights generation for automated insights from reports](/accelerators/#sales|conversebot)
- [iNRM Cross-lever revenue growth optimization platform](/accelerators/sigmoid-inrm/)
- [AssortmentIQ Optimize shelf layouts and assortment mix at scale with AI-based insights](/accelerators/sigmoid-assortmentiq/)
- [Read Whitepaper](/ebooks-whitepapers/building-agentic-ai-chatbots-for-business-process-transformation/)
- [Listen Podcast](/events/podcast/how-jack-in-the-box-is-redefining-personalization-and-supply-chain-with-ai/)
- [Blogs](/blogs/)
- [White Papers](/ebooks-whitepapers/)
- [Case Studies](/case-studies/)
- [Podcast](/events/podcast/#Podcasts)
- [Read Blog](/blogs/the-genai-adoption-triad-responsibility-ethics-and-explainability/)
- [ConverseBot](/accelerators/#sales|conversebot/)
## Tags
- Cloud Transformation
---
## Footer Links
- [Talk to our AI experts](/contact-us/)
- [AI Strategy](/enterprise-ai-strategy/)
- [Agentic AI](/agentic-ai-solutions/)
- [Generative AI](/generative-ai/)
- [AI Managed Services](/ai-managed-services/)
- [Responsible AI](/responsible-ai-in-enterprise/)
- [Advanced Analytics](/advanced-data-analytics-solutions/)
- [Data Strategy](/data-analytics-strategy//)
- [Data Engineering](/data-engineering/)
- [Data Management](/ai-data-management-services/)
- [Cloud Transformation](/cloud-transformation/)
- [Data Ops](/data-devops/)
- [Data Visualization](/data-visualization-service/)
- [Automated Insights](/automated-insights/)
- [BI Migration](/bi-migration/)
- [Data Modeling](/data-modeling-services/)
- [Data Observability](/data-observability/)
- [CPG & Retail](/industries/cpg-analytics/)
- [Financial Services](/industries/banking-financial-analytics-services/)
- [Life Sciences](/industries/life-sciences/)
- [Case Studies](/case-studies/)
- [Thought Leadership](/ebooks-whitepapers/)
- [Blogs](/blogs/)
- [Company](/about-sigmoid/)
- [Newsroom](/newsroom/)
- [Accelerators](/accelerators/)
- [Careers](/careers/)
- [Privacy Policy |](/privacy-policy/)
- [Cookie Policy](/cookie-policy/)